Word2Vec
斯坦福大学《自然语言处理 2023|CS224n: Natural Language Processing》中英字幕(豆包翻译)_哔哩哔哩_bilibili
斯坦福 NLP 名课带学详解 | CS224n 第 1 讲 - NLP 介绍与词向量初步(NLP 通关指南·完结 🎉) - 知乎
[09]2023 _ Lecture 9 - Pretraining.zh_en_哔哩哔哩_bilibili
WordNet 是传统的专业同义词库,但是有局限,很多同义词又有其它语境限制
Word2Vec 简介
Word2Vec 是一种用来训练词向量(Word Embedding)的模型,它能把词语转换成一个向量表示
Word2Vec 通过对大量文本数据进行训练,学习如何将每个词表示为一个向量。这些向量可以捕捉到词语的语义关系(比如“王子”与“公主”会比较相似,或者“狗”和“猫”也有相似性)
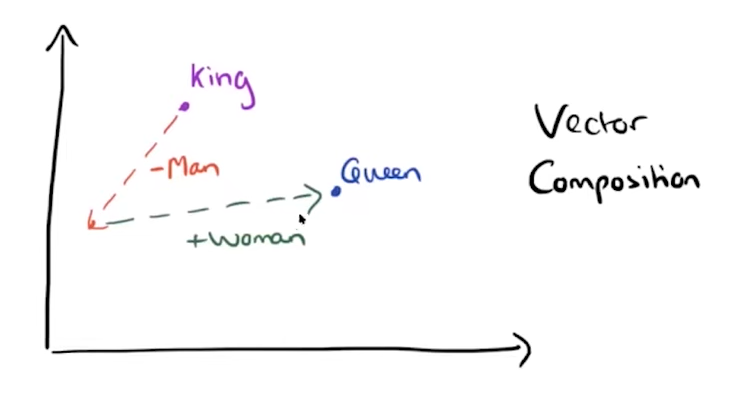
直观理解:当我们把词向量投影到二维平面时,会发现词义相似的词会聚集
我们处理的单位是一个单词,但单词的意思是需要上下文来确定的,于是我们的处理对象分为了中心词(center word),以及其对应的上下文(outside word)
相应的,我们尝试用两个 1xn 向量表示一个单词,即两个词向量(Word Embedding),一个存储单词作为中心词时的特征,另一个存储单词作为上下文时的特征
word2vec工作的大致流程是,首先初始化所有词向量为随机向量,然后根据设置窗口,利用词语库的语句样本通过损失函数不断调整词向量的值,使得损失函数最小即可
似然函数 Likelihood Function
Word2Vec 使用了“似然函数”(Likelihood Function)来衡量当前模型预测的概率有多高
似然函数被表示为 \(L(θ)\),它实际上是所有预测结果的连乘积

\(\theta\) 代表所有模型参数,写在一个长的参数向量里,在当前场景下是 d 维向量空间的 V 个词汇。
这里的意思是:
对于每一个中心词 \(w_t\),我们希望预测它周围的上下文词 \(w_{t+j}\)(\(j\) 是上下文的窗口,表示“前后几个词”)。
\(P(w_{t+j} | w_t; \theta)\) 表示给定 \(w_t\),预测 \(w_{t+j}\) 词的概率,即在已知一个特定的中心词的情况下,某个上下文词出现的可能性有多大
目标函数 Objective Function
用来衡量训练的模型好坏的一个数学公式,在 Word2Vec 中,目标函数的目的是最大化模型对词语上下文的预测准确性
为了让优化过程更容易,通常我们会取似然函数的对数,这样乘积变成了求和,计算起来更简单
目标函数 \(J(\theta)\) 就是似然函数的对数平均值
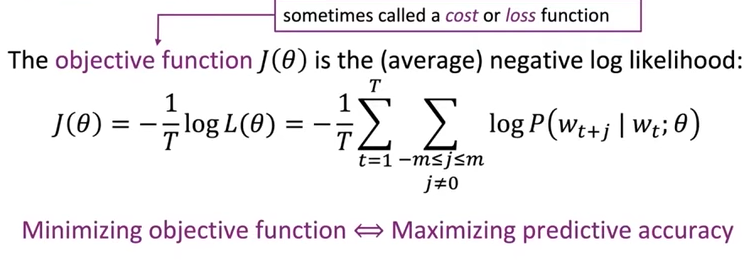
我们要通过调整参数 \(θ\) 来最小化这个目标函数,以此为标准来优化模型
预测函数 Predict Function
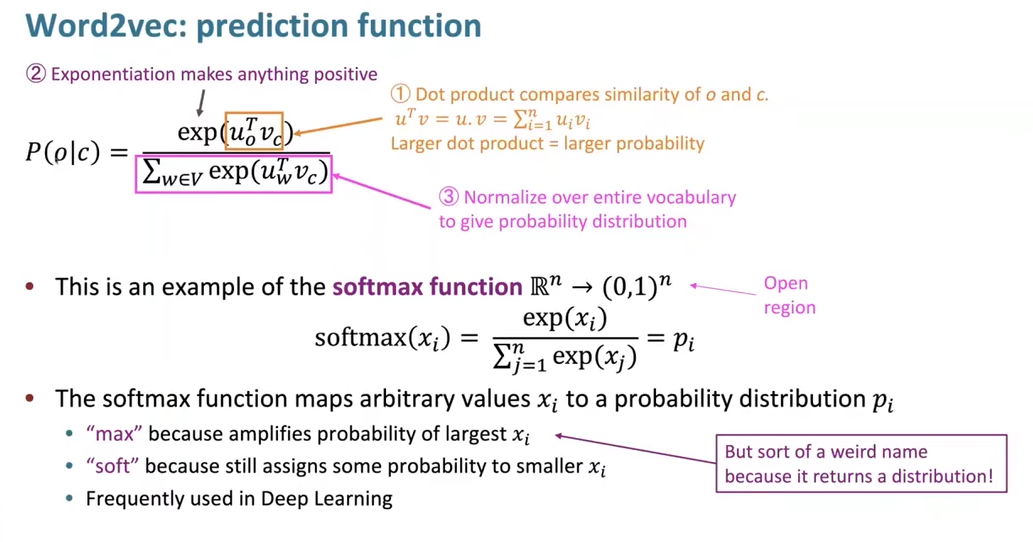
我们通过 softmax 函数计算计算 \(P(o | c)\) $$ \text{softmax}(x_{i})=\frac{\exp(x_{i})}{\sum_{j = 1}^{n} \exp(x_{j})}= p_{i} $$
- “max”:因为它放大了最大的对应的概率。
- “soft”:因为它仍然为较小的分配了一定的概率。
Word2vec 的预测函数: $$ P(o|c)=\frac{\exp(u_{o}^{T}v_{c})}{\sum_{w\in V} \exp(u_{w}^{T}v_{c})} $$
- \(u_o\) 是目标输出词 \(o\) 对应的向量表示。
- 在 Word2vec 模型训练过程中,对于每个输出词,模型都会学习到一个与之对应的向量 \(u_o\),用来衡量该输出词与上下文词的某种关联程度等特征
- \(u_w\) 是词汇表 \(V\) 中所有词对应的向量。
- 这里的 \(w\) 代表词汇表 \(V\) 中的任意一个词,\(u_w\) 就是这些词所对应的向量集合。
梯度下降训练细节推导
现在我们已经有了所有 Word2Vec 训练模型需要的公式了,只需要提供单词库就可以开始训练了
将预测函数代入目标函数,借助微积分化简即可
\(u_o\) 是 \(u_{w=o}\) 的缩写
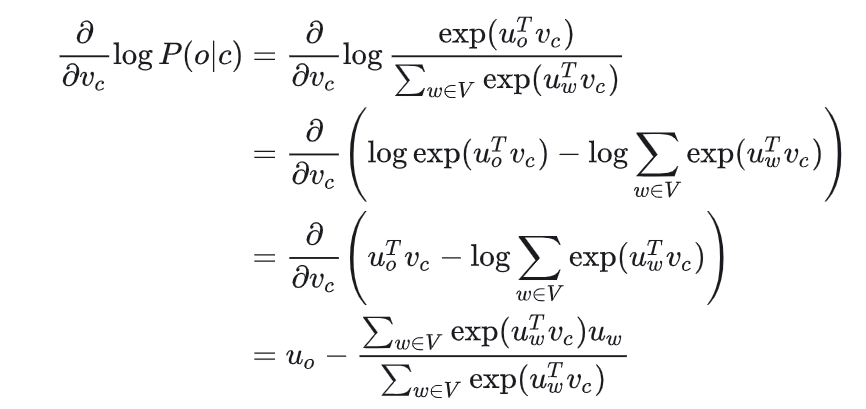
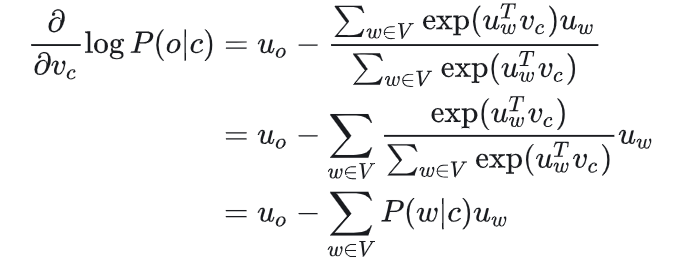
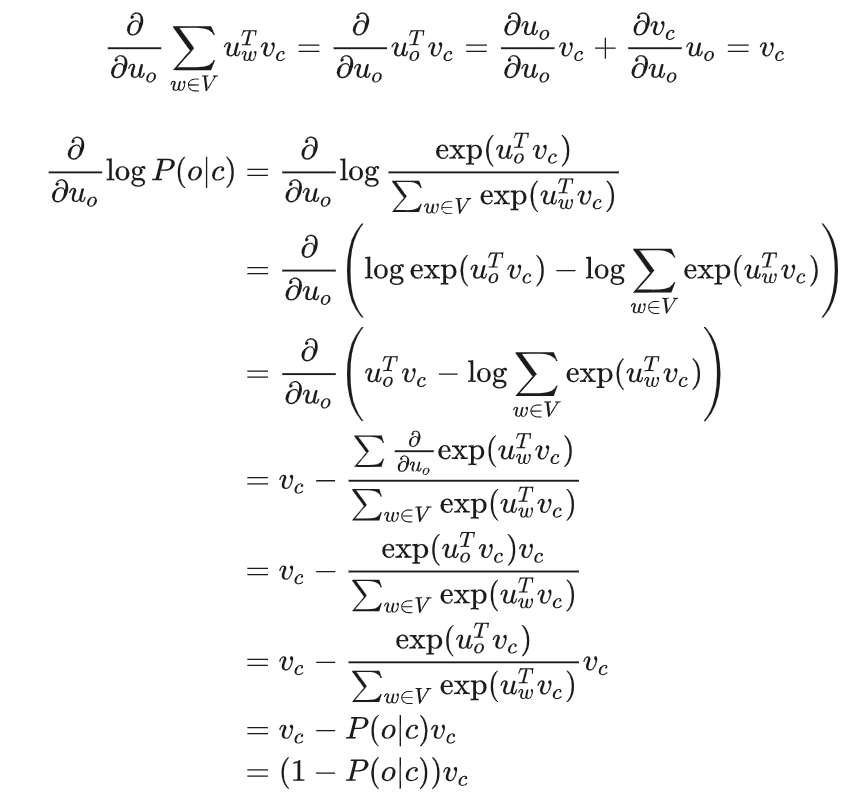
可以理解,当 P(o|c)→1,即通过中心词 c 我们可以正确预测上下文词 o,此时我们不需要调整 uo,反之,则相应调整 uo。
训练模型的过程,实际上是我们在调整参数最小化损失函数。
词向量的组合