Post Training
:material-circle-edit-outline: 约 472 个字 :material-clock-time-two-outline: 预计阅读时间 2 分钟
[11]2024 _ Lecture 10 - Post-training by Archit Sharma.zh_en_哔哩哔哩_bilibili
Zero-shot & Few-shot In-Context Learning
零样本(ZS)学习指,在没有给出例子、没有更新梯度的情况下完成多种任务的能力
比如,给出问题,然后说:Let's think step by step. 然后模型真会自己进行推理
或许模型初始相应并不如预期,但其实际具备所需的能力,关键在于如何激发这些能力
应思考预训练数据的特性,数据如何关联目标行为,等等
Instruction Fine-tuning
我们尝试对输入的指令进行微调,以使模型能达到预期目标
RLHF
优化人类偏好
首先进行 Instruction Fine-tuning,即对预训练模型进行多任务指令微调,使其初步符合用户意图
然后建立某种奖励机制,用于评估给定指令对应回答的人类偏好程度
然后利用这个奖励机制通过优化方法进行训练
建立反映人类偏好的奖励模型
人工标注评分基本不可行,样本需求量太大了,我们需要训练能够预测人类偏好的模型
这就是一个简单的机器学习回归式问题
还有个问题,很多情况下,人类的判断是模糊的,主观的,波动会比较大
解决方法是调整问题设定方式,不再直接预测奖励分数,而是对比多个答案,进行答案排序,再根据排序结果映射为分数

我们可以使用强化学习来优化
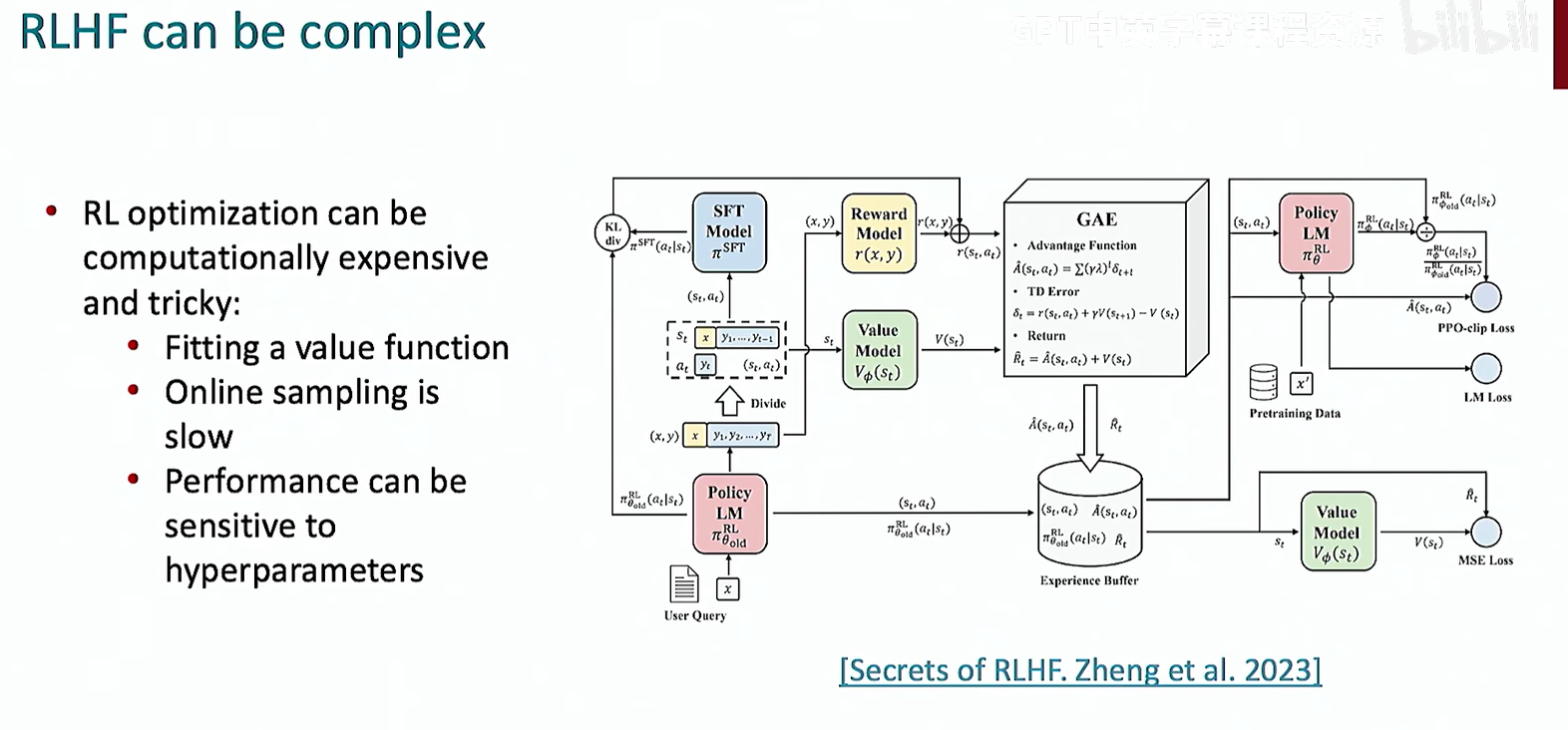
总体下来,RLHF 还是过于复炸了
DPO(直接偏好优化)
RLHF 的简化替代方案
一堆数学推导,没怎么看。。。[11]2024 _ Lecture 10 - Post-training by Archit Sharma.zh_en_哔哩哔哩_bilibili
HF 上 90%的开源模型都是用 DPO 训练的