NLG
:material-circle-edit-outline: 约 401 个字 :material-clock-time-two-outline: 预计阅读时间 1 分钟
机器翻译就是 NLG 的一种
repetition
开放性生成模型会存在输出重复内容的情况,重复次数越多负对数值越低,越可能重复
改变架构无法解决这个问题,LSTM 和 transformers 都有类似情况
改变模型规模也无法解决这个问题
n-gram blocking
基本思路就是避免相同 n 元组重复出现,例如 3-gram blocking,出现了一次 I am happy,那么模型再第二次生成 I am 后,下一次生成会把 happy 概率强制设置为 0
这是直接在解码阶段加以约束,而且太粗暴了
use different training objective
不使用最大似然估计训练,而是使用反似然目标训练,后者训练的模型会因生成已出现的标记而受到惩罚
类似将 n-gram blocking 的思路融入训练阶段
另一种 training objective 是覆盖机制,使用注意力机制来防止重复
decoding
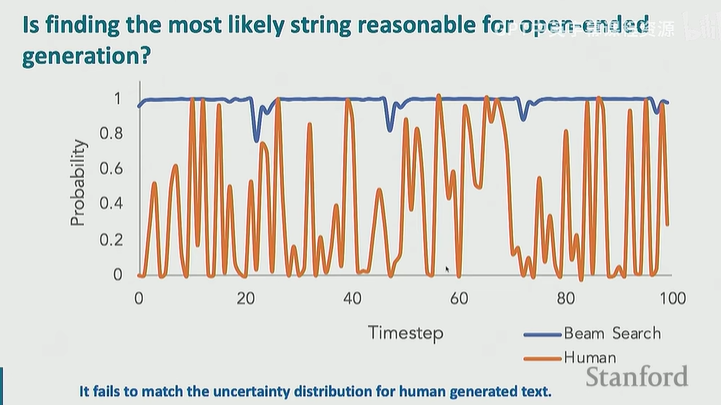
对于开放式文本生成,寻找概率最高的字符串并不合理,因为这不符合人类的模式
top-k sampling
从概率分布中的前 k 个词元进行采样,也不一定是随机采样,可以计算得分
不过这样的话还是无法模拟上图中人类概率很低的地方,人类能很流利地说出比较离谱的词
这或许是可以改进的地方,让机器说话更像人
但是,top-k 也可能选出不合理的词,有些情况下就只有一个词是合理的