Benchmarking
:material-circle-edit-outline: 约 216 个字 :material-clock-time-two-outline: 预计阅读时间 1 分钟
如何评估大模型性能
封闭式任务
问题的答案有限且能列举
不要盲目采用现有方法,不要认为要是有问题早有人发现了,你正身处最前沿,发现问题的那个人可能就是你
开放式评估
问题的答案无法穷举,或者答案不是非对即错的
内容重叠评估(评估/指标 metrics)
直接忽略了语义,BLEU分数很离谱
BLEU BERT BLEURT
BLEU基本没人看了,BERT还在用
基于模型的评估
AlpacaEval
人工评估
对于开放式任务,人工评估才是真正的黄金标准,但是很困难
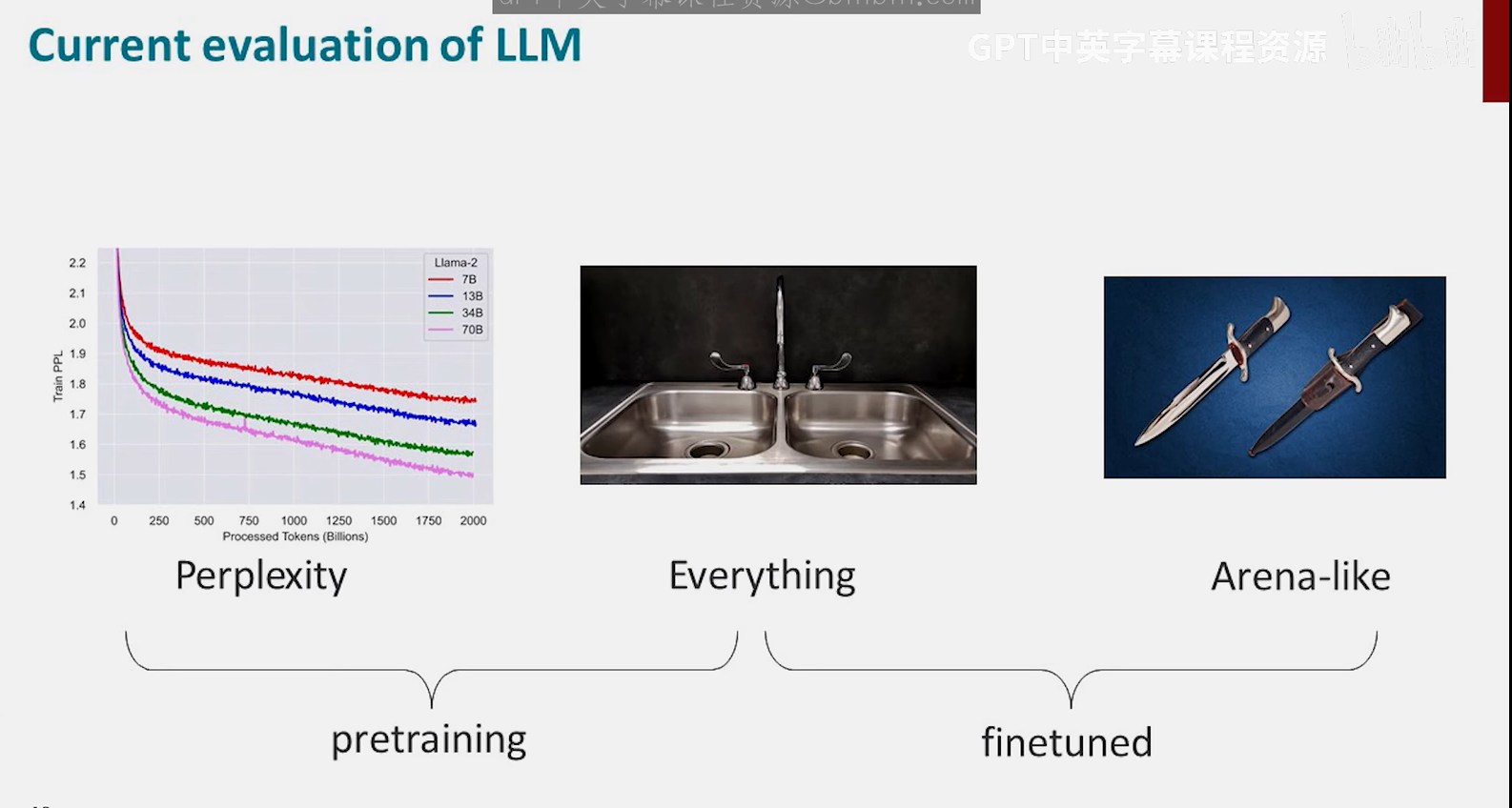
困惑度与任务平均表现高度相关
测试数据集可能已经预训练进模型了,模型被数据污染,导致无法正确评估