RNN
正则化
正则化可以用来防止过拟合
在现代大型神经网络中,只要正则化得当,模型仍能良好泛化到新数据
Dropout
基本思想是,在训练时,每个样本向前传播时,随机屏蔽神经网络中间层的部分输入
实现方式是生成一个 0-1 随机掩码,,而且每次向前传播都会生成新的掩码
如此,模型无法过度依赖某个特定特征,因为该特征随时都会消失,模型就得向着灵活运用各种替代特征推理的方向学习
语言模型
语义模型用于在给定前文语境的情况下,建立对下一个词的 概率 分布


n-gram Language Models
n-gram 语言模型(n-gram LM)会存储大量的 n-元组(n-gram),比如:
- 2-gram(bigram): "The students", "students opened"
- 3-gram(trigram): "The students opened"
将语句库中的样本分为 n 元组作为基本处理单元计算概率,根据条件词计算概率找出最有可能的下一个词
确切说窗口为 n,包括待生成的词,也就是根据前 n-1 个词计算下一个词的概率
这个模型有稀疏性问题,有些语句组合可能样本里没有,概率就为 0,但是确实可能出现的,于是可以设置初始概率为一个很小的值,而不是 0
这个模型能保证语法正确率,但是却容易忽略语义,生成的文段逻辑混乱,没有中心,而且需要存储海量的 n 元组,所以只流行于 2012 年之前
Fixed-Window Neural Language Model
不会有稀疏性问题,不需要存储所有的 n-gram
神经网络语言模型(NLM)通过将单词转换为向量(embedding),然后用神经网络进行学习,而不是直接存储 n-gram 的统计数据
但这个模型只考虑固定数量的前文单词,句子长度是可变的,固定窗口可能无法捕捉足够多的信息
而增加窗口大小会增加参数(Enlarging window enlarges W),且窗口永远不可能足够大(Window can never be large enough)
语言中的依赖关系可能跨越很长的距离,固定窗口始终有限制
输入的单词用不同权重(Weights)处理,没有对称性(No symmetry)
We need a neural architecture that can process any length input
循环神经网络 RNN
我们之前学了 word2vec 架构(CBOW/Skip-gram),feedforward network/全连接层经典神经网络(embedding+Hidden Layer(通常是全连接层)+softmax)
RNN 是我们要学的第三类,之后还要学第四类 transformer
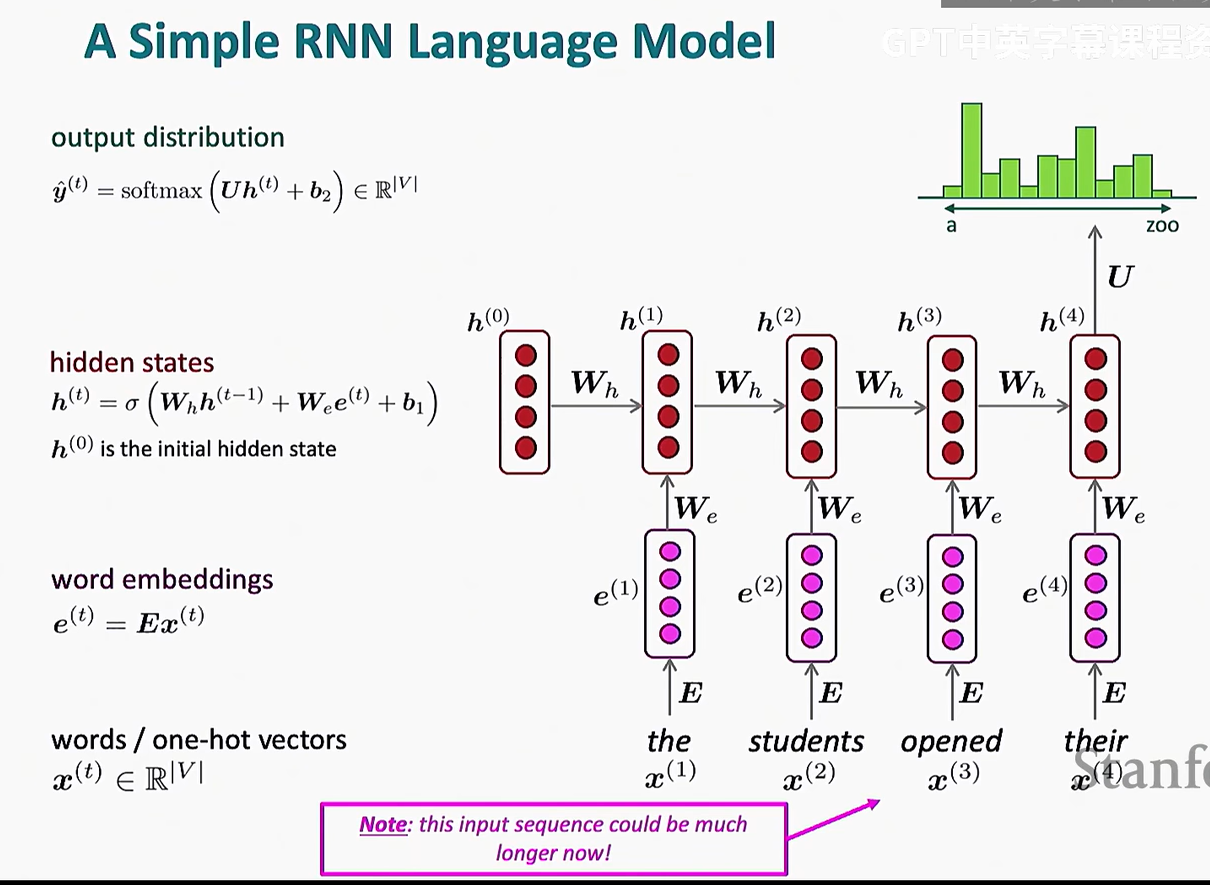
但是实际上这是在做一个for循环,上一层要等下一层的结果才能计算
这也是RNN不受青睐的原因之一

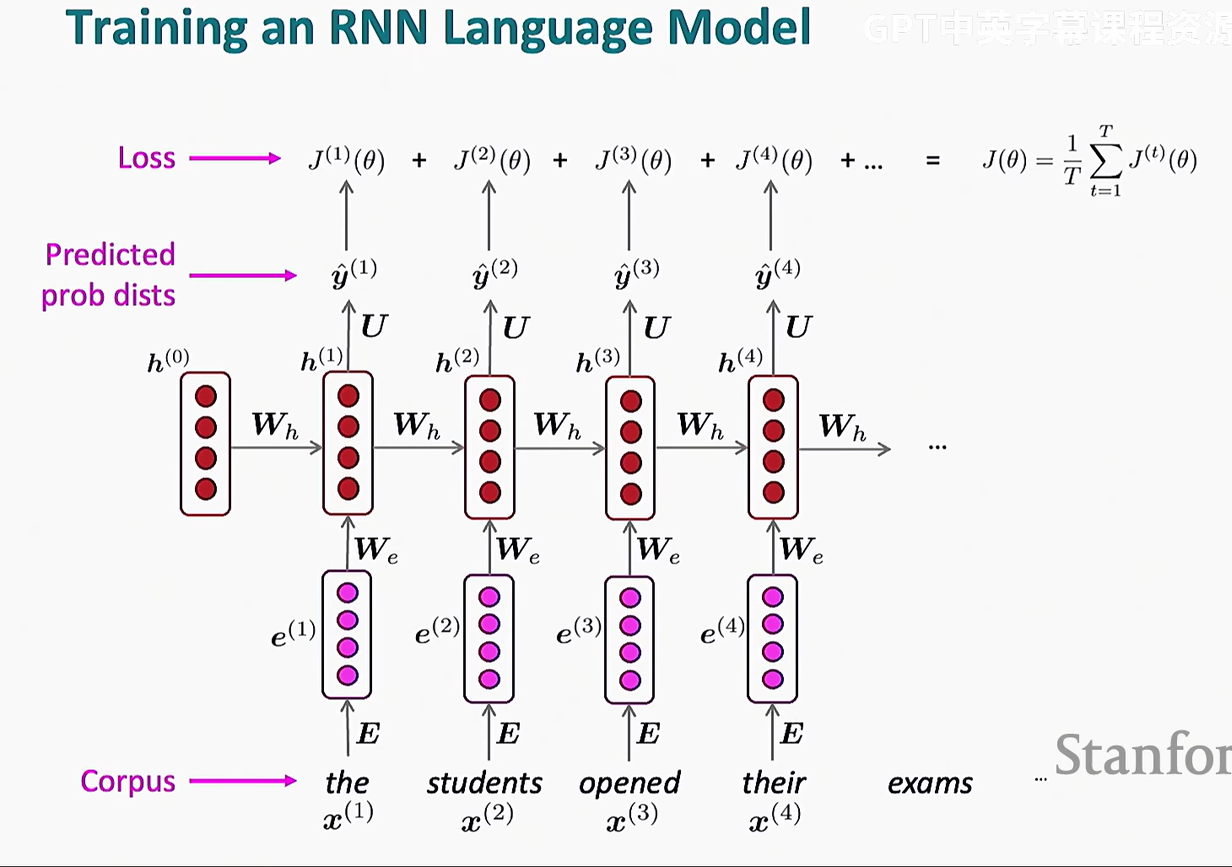
这里引入一个概念叫教师强制(Teacher Forcing),是 训练 RNN 语言模型(或者其他序列模型,如 LSTM、GRU)时的一种加速收敛的方法
在训练过程中,RNN 需要根据前面的单词预测下一个单词,但如果让它用自己生成的单词去预测下一个单词,可能会导致错误不断累积,模型很难学到正确的模式
教师强制的核心思想: 👉 训练时,我们不让 RNN 使用自己预测的单词,而是强制使用真实的训练数据(即实际的正确单词)作为下一步的输入。
也就是上图中最底下一行
当然,缺点是Exposure Bias,测试时 RNN 要用自己的预测结果,可能会导致模型不适应
解决方案之一是 Scheduled Sampling(计划采样),即一开始用真实单词,训练后期逐步让 RNN 用自己的预测结果