Sequence to sequence
评估语言模型
我们主要介绍两个指标,困惑度与交叉熵

LSTMs (Long Short-Term Memory RNNs)
在 RNN 中,我们计算出各个损失值后,也需要分别反向传播来更新参数
但是 RNN 的步数太多了,较远的梯度可能被稀释甚至消失,或被指数级爆炸,而较近的梯度则起到了主导的作用
这里的问题出在时间步没有记忆能力,对于之前隐藏状态是直接乘 W
于是就有了 LSTM 架构,能够实现长距离信息流动
LSTM 内部有两个隐藏状态,一个叫隐藏状态,另一个叫 cell 状态,我们用门控来更新后者
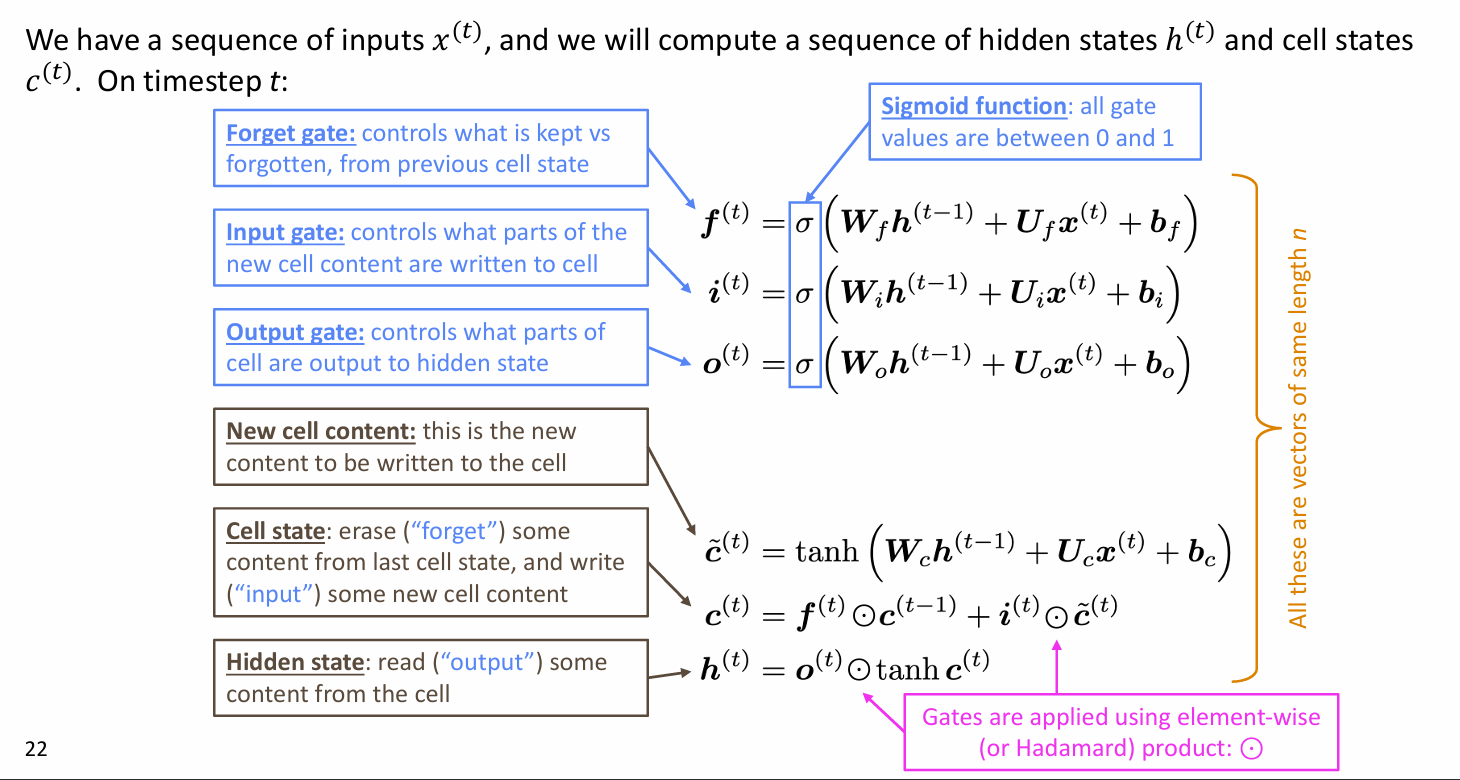
门控向量大小始终保持不变,所以我们可以将几个矩阵合成一个大矩阵一起算
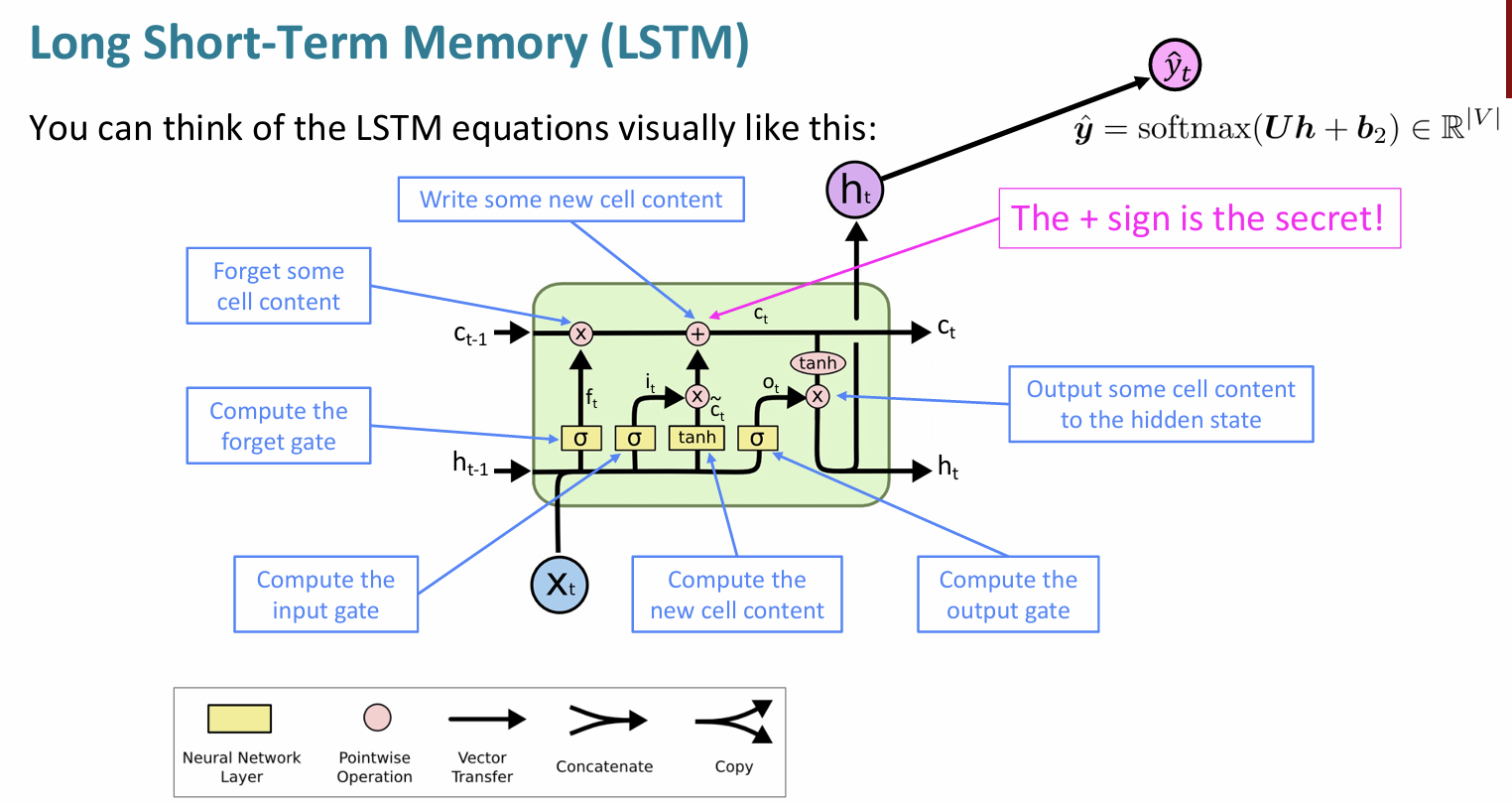
LSTM 保存记忆的关键就是计算 \(c_t\) 的那个 \(+\) 运算,之前我们都是通过乘法传递信息,很容易被抹除或放大,加运算能够很好地保留信息
LSTM 在几年前还是重点,到了 2024 年已经不是重点了
梯度爆炸与消失并不是 RNN 独有的缺点,很多模型都会有,于是有人提出每个时间步直接用恒等映射传递信息,于是就有了 ResNet;又有人提出让每一层的信息都传递给其它所有层,于是就有了 DenseNet
拓展 RNN
理想的表征应同时包含上下文信息,但我们用 RNN 训练时,对于一个词只使用了其之前的信息,其之后的信息都没考虑
我们可以再加一个反方向的 RNN,从后往前训练,然后再加一层隐藏层处理两者的输出即可,这既是双向 LSTM
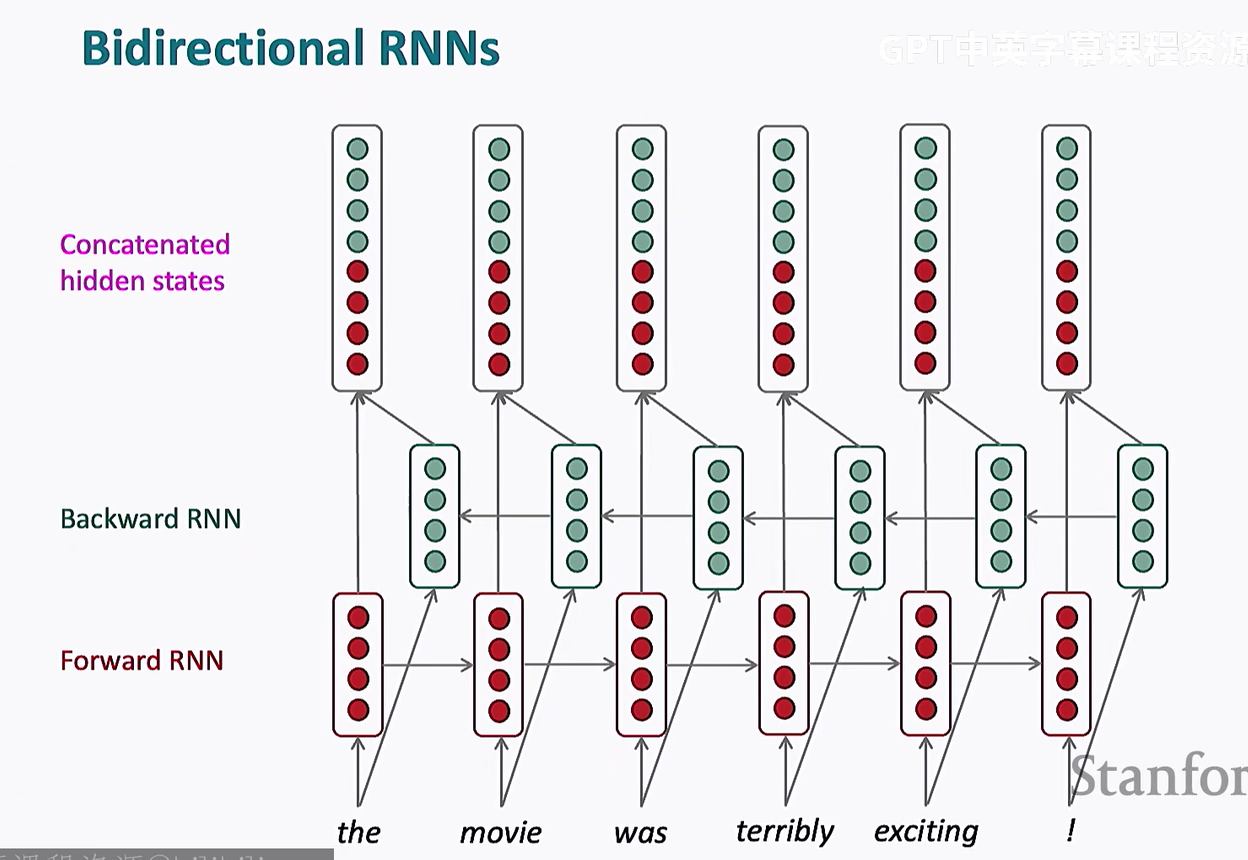
双向 LSTM (BiLSTM)一般不用于文本生成,因为它需要在整个输入序列都可用的情况下才能工作,而文本生成通常是 自回归(autoregressive) 的,即一个词一个词地预测,无法提前看到未来的词
不过已经被 transformer 取代了
此外,还可以通过增加多层隐藏层来增强模型表现
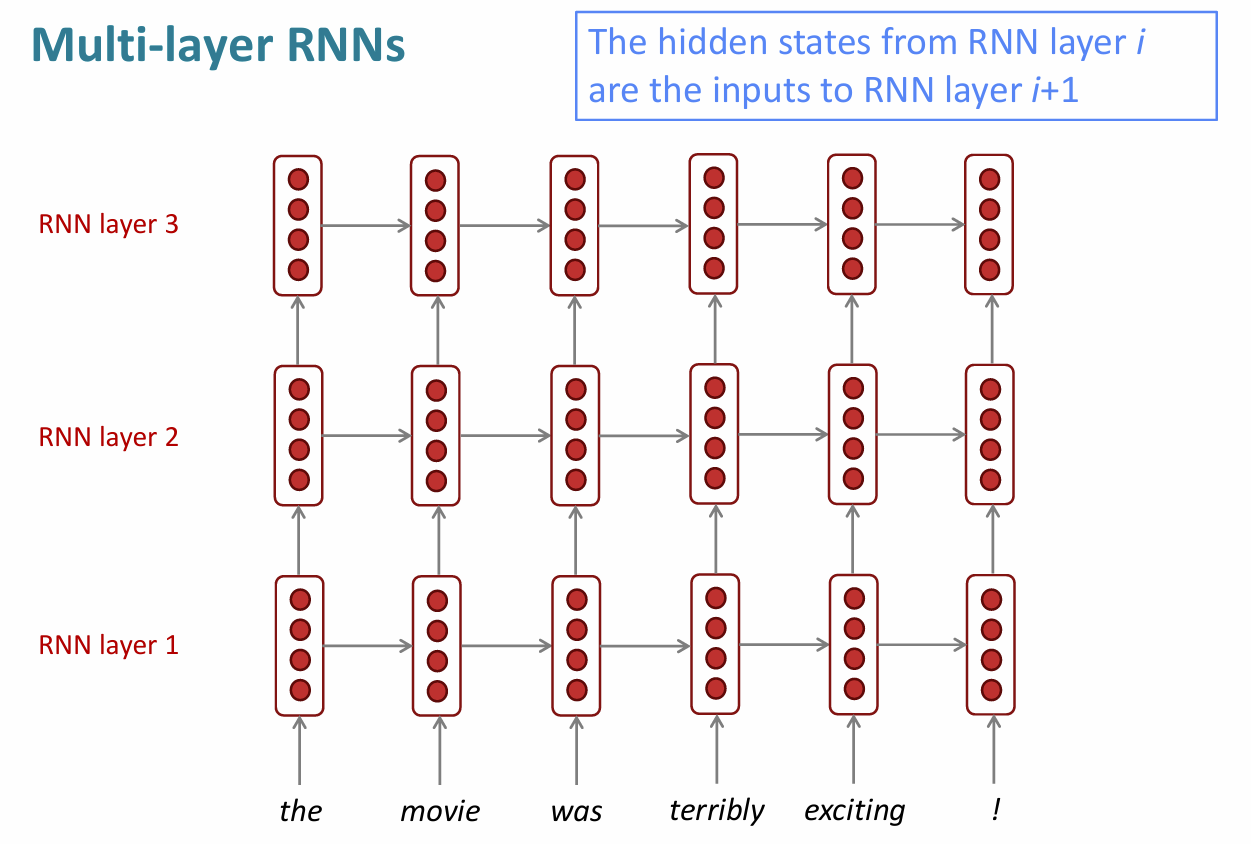
实验证明这样是有益的,但只局限于增加一层,三层、四层存在争议
也被 Transformer 替代了
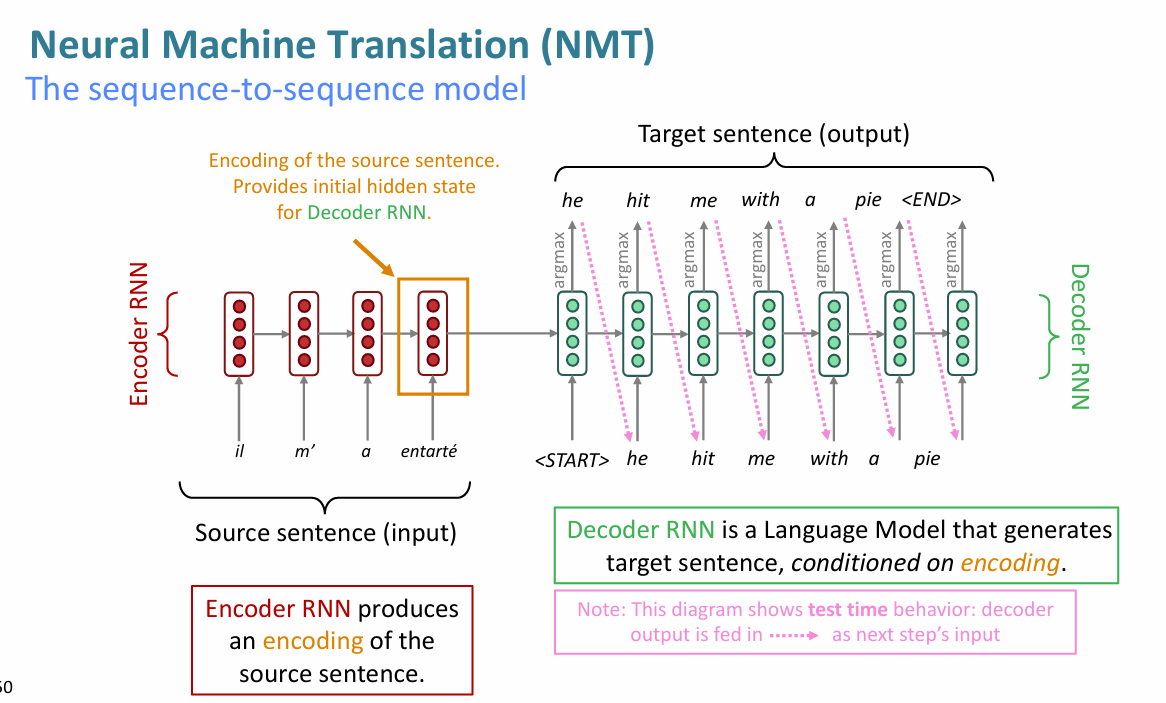
神经机器翻译 Neural Machine Translation(NMT)
RNN 的一种应用
我们在 NMT 使用的一种模型是 seq2seq
seq2seq 的基础是 LSTM,包括两个独立的模块:编码器和译码器
如何评估机器翻译
BLEU 测试,当然这种选取特定例文的评估多少存在不够普遍的问题