Attention
:material-circle-edit-outline: 约 382 个字 :material-clock-time-two-outline: 预计阅读时间 1 分钟
注意力机制
之前我们接触的前馈 NN,LSTM,都是千禧年之前就有的模型,只是在等待足够的数据和算力
注意力机制则是 2014 年提出的革命性创新,极大增强了 NN 的能力
注意力机制诞生于机器翻译,但是是通用技术,任何任务都可以引入注意力机制
人类在翻译句子时,会实时关注句子的(可能)任意一部分,但 seq2seq 是基于 RNN 的,decoder 只能看见 encoder 给的用表征整个语句的单个向量,这是很不合理的
attention 的核心思想就是,让 decoder 的每个时间步都能直接链接 encoder,能够聚焦特定的部分
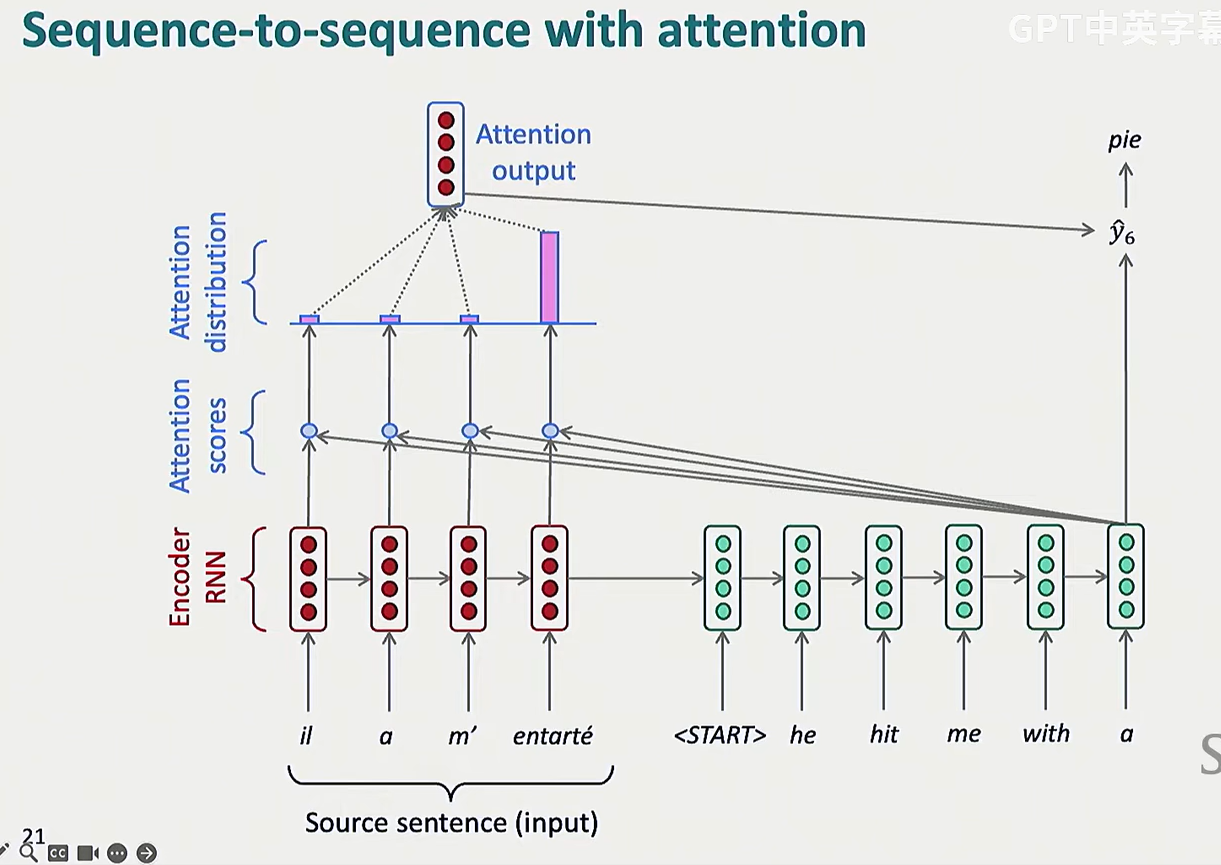


计算 attention 的大致流程就只有下面三步,但计算注意力分数的方式却不止点积一种

LSTM 的隐藏状态是复合性的,蕴含了大量的信息,但 decoder 需要要特定的一些信息
与其直接点乘,可以再加一个中间矩阵,这个矩阵也是由学习得到的

而且不再要求 encoder 与 decoder 的隐藏状态向量对齐了
但很显然,W 的大小是两个向量长度的乘积,太大了,可以进一步优化,大矩阵可以通过两个更小的矩阵相乘得到:
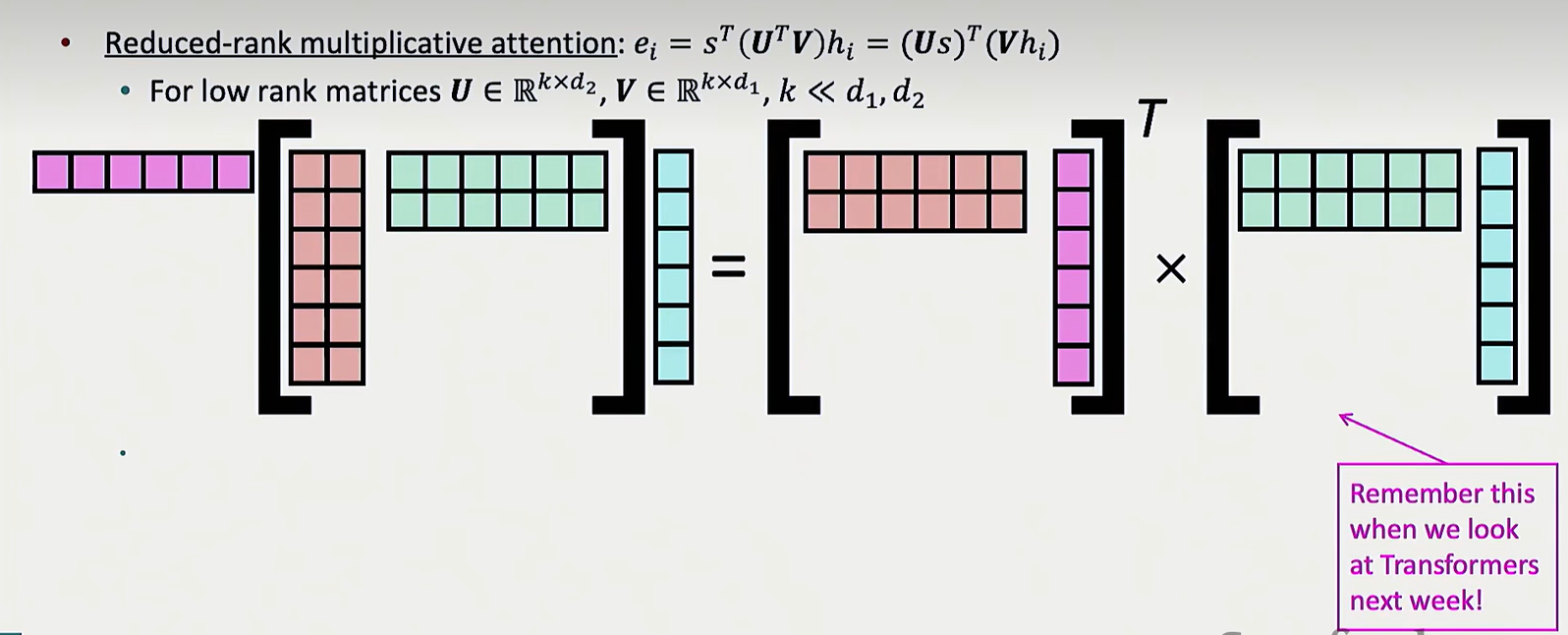
transformer 的一个思路就是将大矩阵映射到小矩阵
还可以用小型神经网络计算注意力分数
