Transformers
:material-circle-edit-outline: 约 628 个字 :material-clock-time-two-outline: 预计阅读时间 2 分钟
自注意力架构
我们可以将 attention 的机制看成一个 soft query
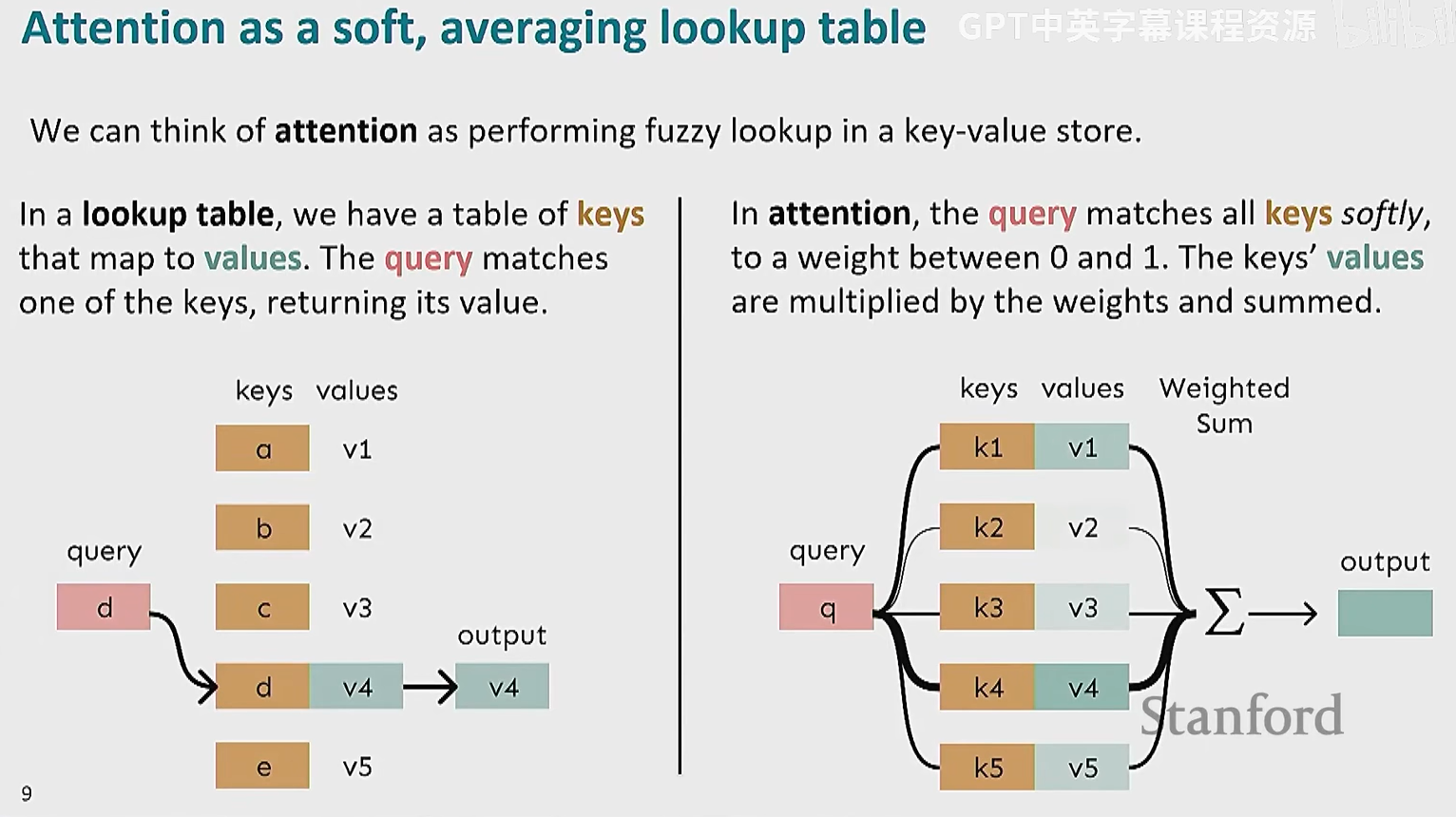

attention 有些问题需要解决,否则不能直接用于模型
一个问题是 attention 处理语句时忽了单词的绝对顺序,集合内单词的任意排列得到的输出是一样的,所以我们需要对词语的位置信息进行编码
我们设计一个向量来表示位置信息,只需在第一层进行编码即可得到

具体向量是什么样子的有很多种,例如正弦表示:
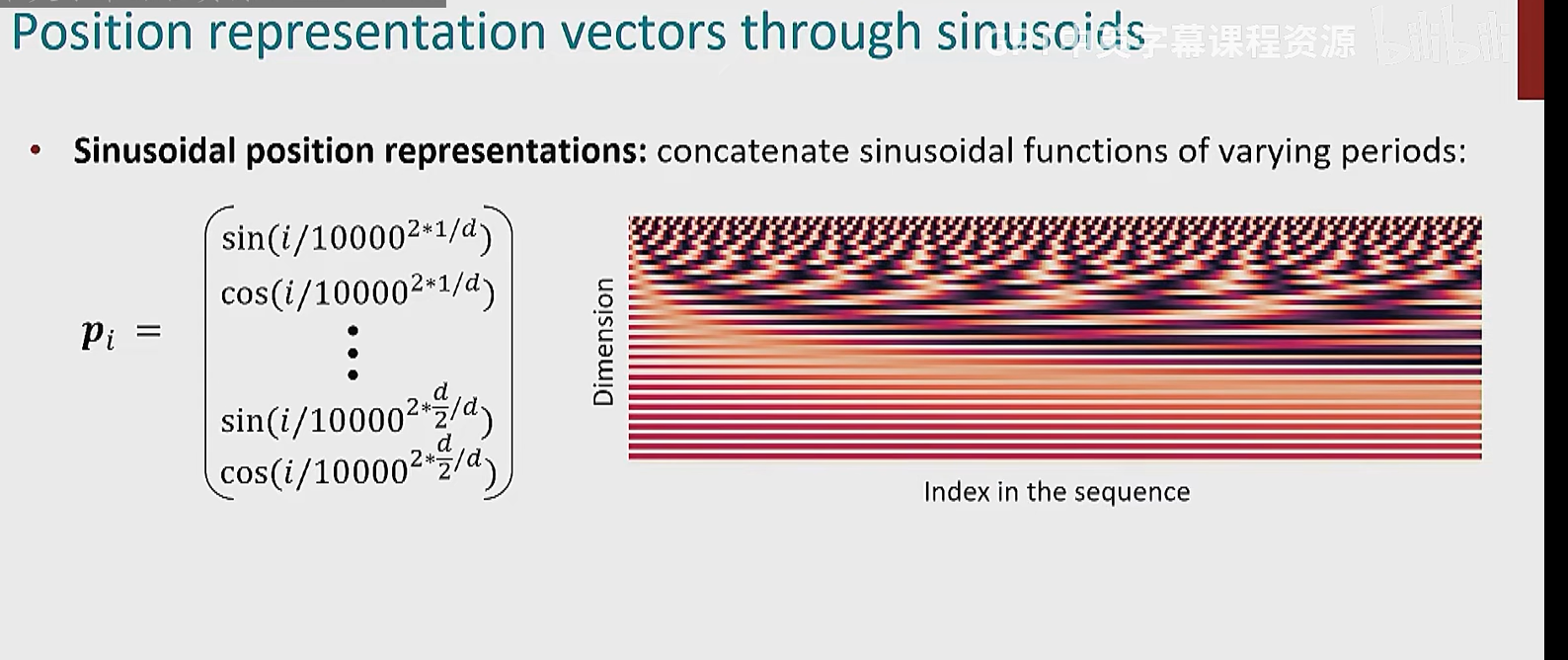
左侧公式
- i 表示当前单词的位置(第 iii 个单词)。
- d 表示嵌入向量的维度(例如 512 维)。
右侧的图
- 横轴是 序列索引(Index in the sequence),表示不同单词在句子中的位置。
- 纵轴是 维度(Dimension),表示嵌入向量的不同维度。
- 颜色表示值的大小(深色 = 低值,浅色 = 高值)。
- 底部是平行的红色条纹:表示低维度的编码变化比较慢,频率较低,编码短距离依赖。
- 上方的黑白交替条纹:表示高维度的编码变化更快,频率更高,编码长期依赖。
当然,实际上我们更加关注相对位置而非绝对位置
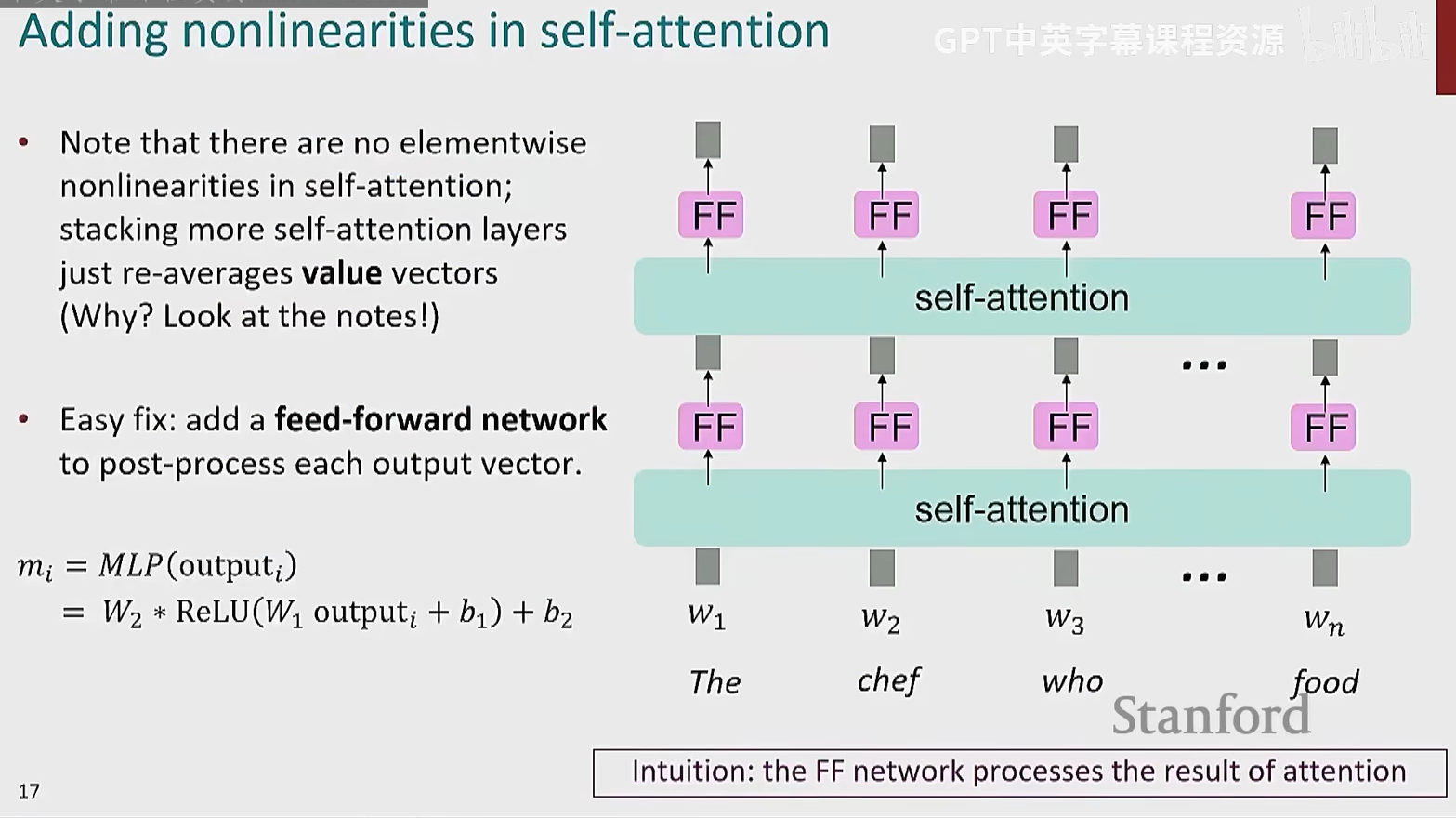
如何我们需要为自注意力机制添加经典深度学习中的非线性元素
然后对于机器翻译或语言建模等选哟定义序列概率分布的任务,我们不能让模型提前查看未来信息,这是一种作弊
没搞明白,训练时提供上下文参数不会更准确?推理时也没办法获得未来信息
哦哦,因为注意力分数是所有 token 都有输出,我们训练时不应该使用后面单词的
实现方式就是设计一个注意力分数矩阵作为输出
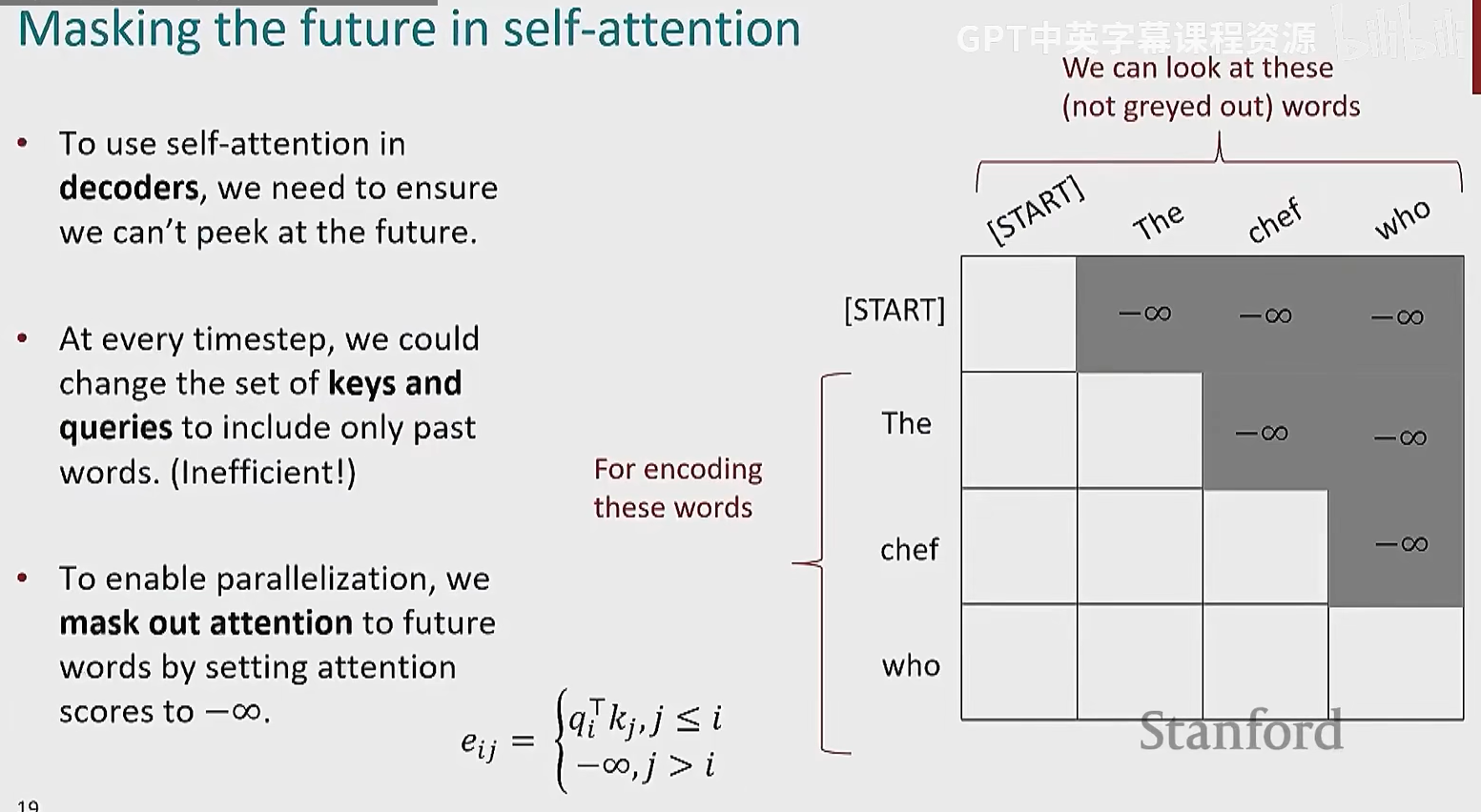
这个只在解码器用,因为会出现计算自回归式概率,即 P(a1)P(a2|a1)P(a3|a2a1)...
编码器还是允许看未来信息的,让元素能互相观察
解决了三个问题后,我们就得到了一个最简单的自注意力架构

但实际上没人会使用这个架构,性能不太够
Transformers
有一部分数学推导没听 [08]2023 _ Lecture 8 - Self-Attention and Transformers.zh_en_哔哩哔哩_bilibili
【超详细】【原理篇&实战篇】一文读懂Transformer-CSDN博客