计算机历史与早期硬件发展——从算盘到电子计算机,从晶体管到CPU
⛵引入
正如课程标题所说的——计算机科学速成课
本部分从计算机的底层开始,从硬件往上串联讲到高级编程
至于内容的深度,个人体验下来讲的都比较浅显,高中生也能够听明白。实际上性质更类似科普视频。
但是对于不熟悉的同学是很适合的。
早期计算机历史
计算机(computer)正如其名,起源于人类对于计算的需求。
不过计算机(computer)这一词最早并非指代计算的工具,而是计算的人——毕竟在现代意义上的计算机发明前,计算的事情还是基本依赖于人脑。早期的计算工具包括算盘、星盘等等。
早期的计算工具中值得一提的是 步进计算器。这是一种机械计算器,利用了齿轮实现十进制数的表示,每一个齿轮代表一位十进制位数,通过齿轮的传动实现了加减法。由于乘法于除法实际上是多个加法于减法的组合,所以该计算器是能够进行加减乘除的。 步进计算器也是世界上第一台能够进行加减乘除四种运算的机器。
关于步进
在计算器中,步进通常表示按下某个按钮或执行某个操作后,显示屏上的数字会以特定的增量进行变化。这个增量通常是预先设定好的。
由于机械计算器工艺复杂,价格昂贵,人们使用更多的是计算表。类似于概率论里查各种分布的分位数。
之后人们又提出了差分机、分析机的概念与设计。
在美国人口普查的需求中,类似答题卡模式的机器也被设计了出来,拉开了电子计算机的发展历程。
电子计算机
随着人口膨胀,经济发展,数据量急剧上升,人们对计算有了更大的要求,传统的机械计算机随着计算量的增大,体积、价格急剧上升,寿命也因损耗减少。于是电子计算机诞生了。
电子计算机的电子元件随着科技发展而变化,下面按时间顺序介绍主要的电子元件。
机械继电器
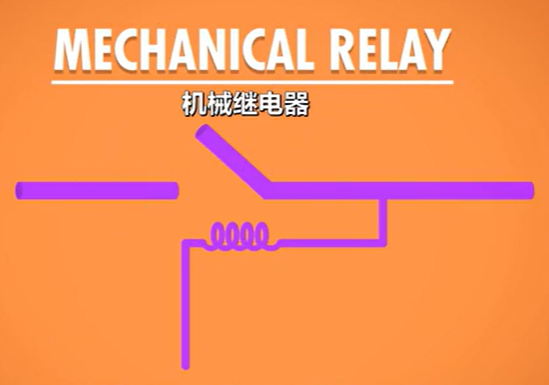
最早的电子计算机用的是机械继电器作为基本元件。机械继电器的原理是通过感应线圈产生的磁场将断开的接线“拉”过来以形成闭合导线。
这种继电器最好的频率也只有50Hz左右,计算速度以秒计。同时由于其机械结构,也会有传统的磨损损耗。
"bug"一词的来源
由机械继电器组成的计算器十分巨大,内部黑暗且温暖,会吸引昆虫,进而造成故障。久而久之,当机器遇到故障,人们就会说有害虫(bug)来了。
真空管
用于组成电子计算机的真空管改造于热电极管。
热电极管是一个含有两个电机的气密的玻璃灯泡,是世界上第一个真空管。工作时,一个电极通电被加热,从而发射电子,这一现象即 热电子发射(Therminoic Emission);另一个电极则吸引电子,形成单向电流。
这种电流只能单向流动的电子部件被称为”二极管
在热电极管上增加控制电极,即可得到与继电器类似的功能的 三级真空管 。很明显,真空管优势在于没有会动的组件,即无磨损。真空管的频率可达数千。真空管的使用标志计算机从机电发展到了电子。
但是,真空管昂贵而易碎
晶体管
晶体管的物理内容牵扯到量子力学,故我们只讲基础。
晶体管利用了半导体的性质,通过一个控制线路控制半导体以实现继电器的功能。
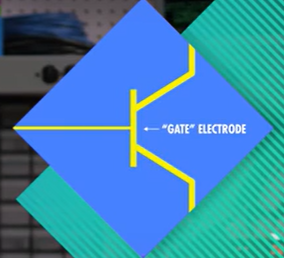
世界上第一个晶体管的频率就达到了10000Hz,好的可达上百万,而且体积小,坚固可靠。
逻辑门的晶体管实现
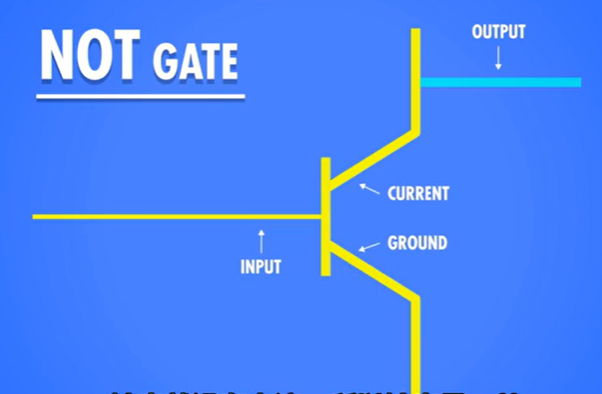
非门(NOT)
将晶体管一头接地,另一头通电,并作为输出,控制线路作为输入。
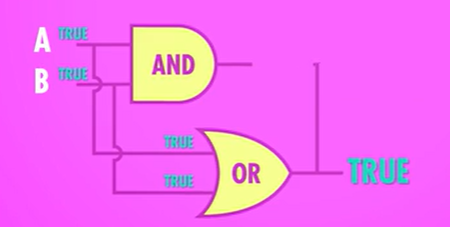
与门(AND)
将两个晶体管串联,一头通电,另一头作为输出,两个控制线路为输入。

或门(OR)
将两个晶体管并联,两者同一端通电,另一端合并作为输出,两个控制线路为输入。

异或门(XOR)
用AND和OR组成
二进制
算术逻辑单元(ALU)
寄存器&内存
这三部分这部分比较简单,日后再补
中央处理器(CPU)
这一部分我们将从微体系架构的角度介绍CPU,并使用一个很简单的例子进行讲解。
微体系架构是一种高层次视角,指设计的时候重点关注功能模块之间的搭配,暂时忽略模块之间具体的连线,而是将连线化简为抽象的连接。
我们的栗子里使用了一个简单的CPU,其组件如下:
- 六个8bit寄存器(Reg):
- 四个操作寄存器(编号A,B,C,D),用于指令操作,具体为临时存储、数据操作;
- 一个指令地址寄存器(Instruction Address Register/IAR),用于追踪程序运行到哪了,即存储当前指令的内存地址;
- 一个指令寄存器(Instruction Register/IR),用于存储当前指令。
- 一个ALU
而该CPU的操作对象为:
-
一个8bit宽的足够大的RAM
- 这个RAM里面存储着一个程序,表现为每个地址存着一串按顺序设计好的指令/数据。数据前四位为opcode,后四位为相应的指令所需操作的数据的地址。
- 程序功能为:将RAM里面储存的两个数字传输给A,B/将这两个数字相加,并将结果输送给C。
该CPU微架构如下
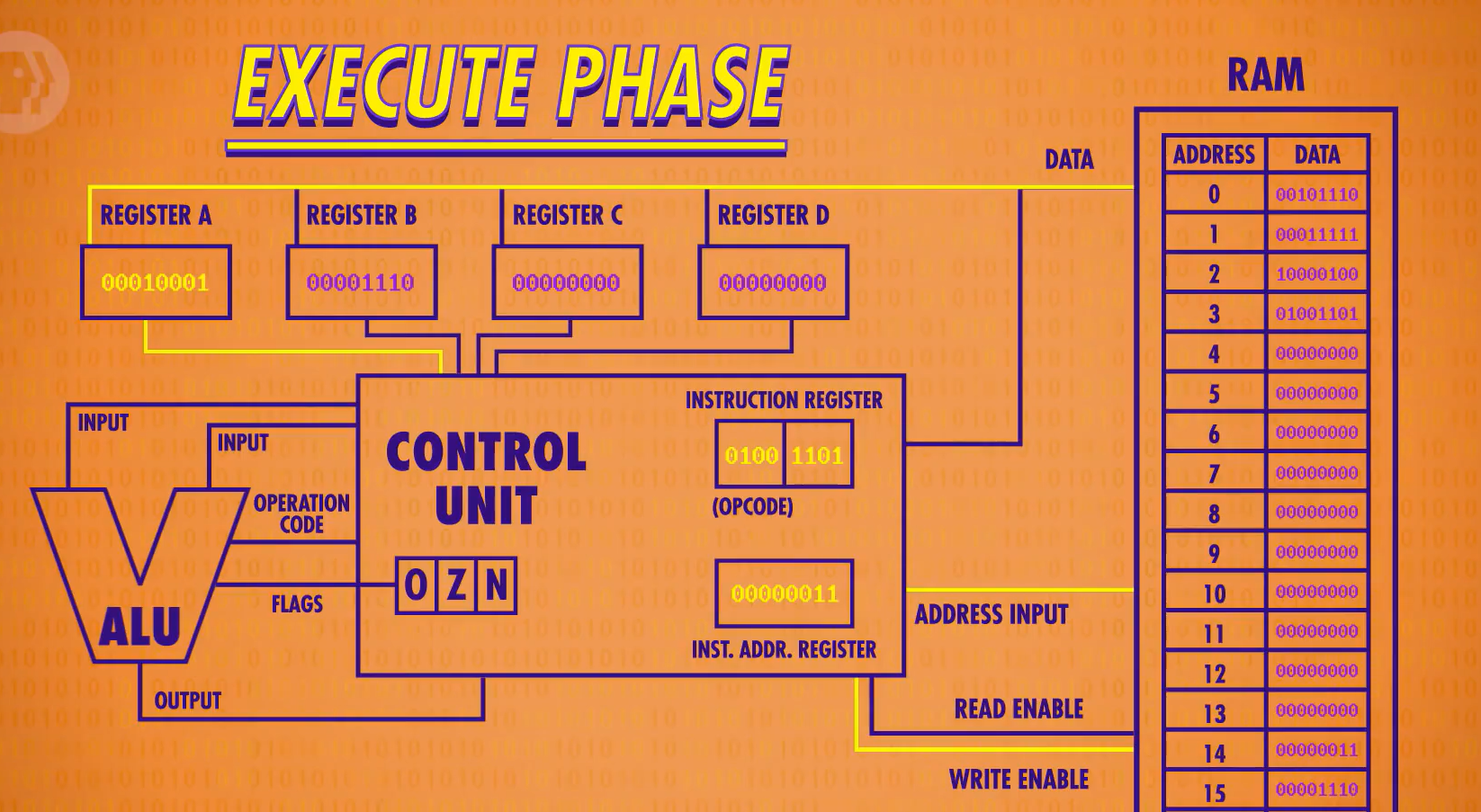
指令表(Instruction Table)
众所周知,计算机是一个工具,而CPU是这个工具的核心。CPU执行的操作的名称被叫做 指令(insruction),显然计算机的指令很多,而我们告诉计算机该进行何种指令的“语言”就是 操作码(operation code/opcode)。
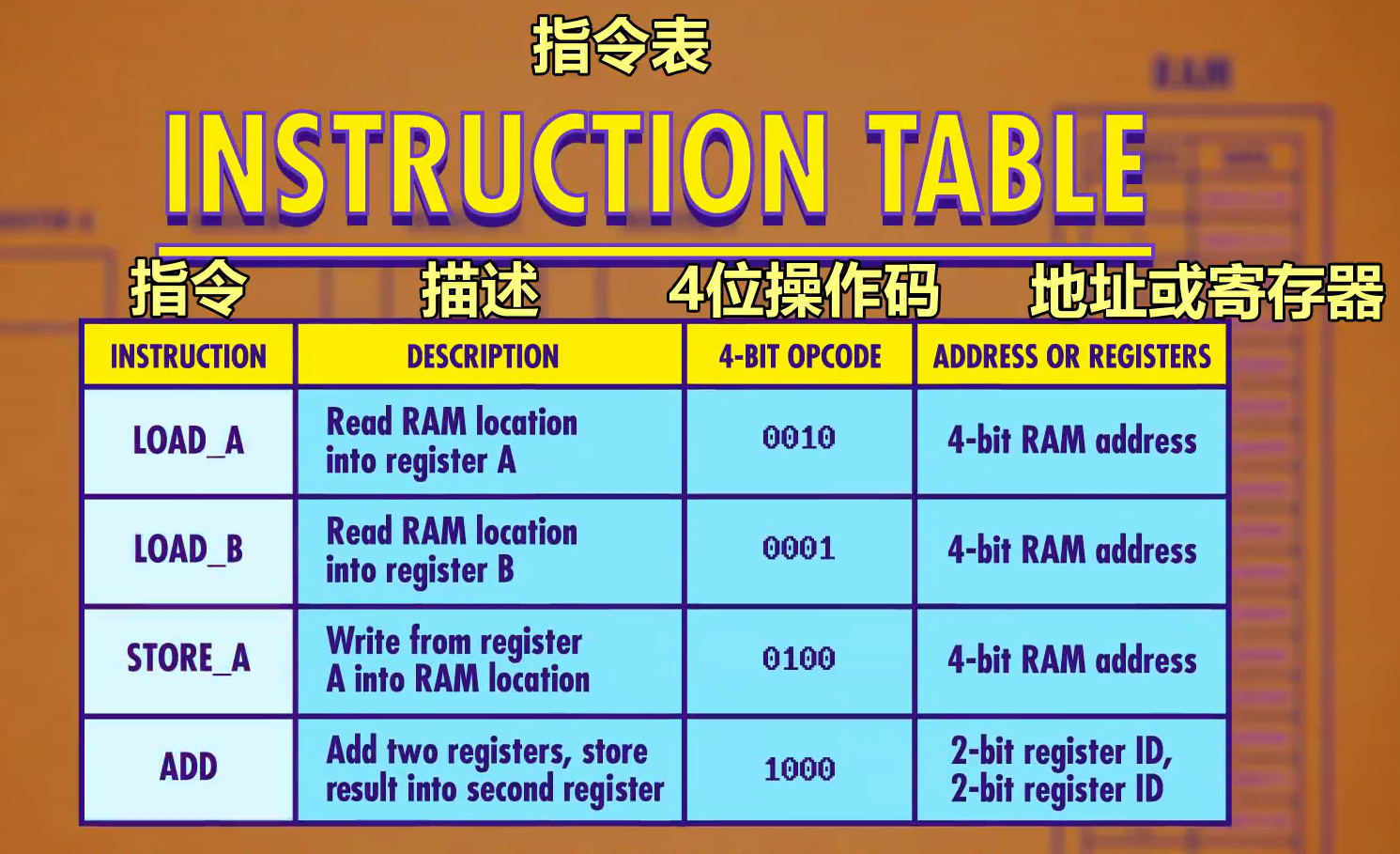
下图为我们栗子里的指令表
CPU的工作阶段
CPU是按序处理的模式,重复执行“\(取址\rightarrow 解码\rightarrow 执行\)”,这三个阶段用到CPU的不同部位。
程序启动后,所有Reg被初始化为8‘b0,然后进入第一个阶段。
取指令阶段(Fetch Phase)
IAR连接RAM,由于初始时IAR为8'b0,故会取出地址为0的数据并复制给IR。注意该阶段IAR不变。
解码阶段(Decode Phase)
我们需要识别IR里面前四位的opcode,而这通过简单的纯逻辑门电路即可实现,例如目前需要识别的0010:
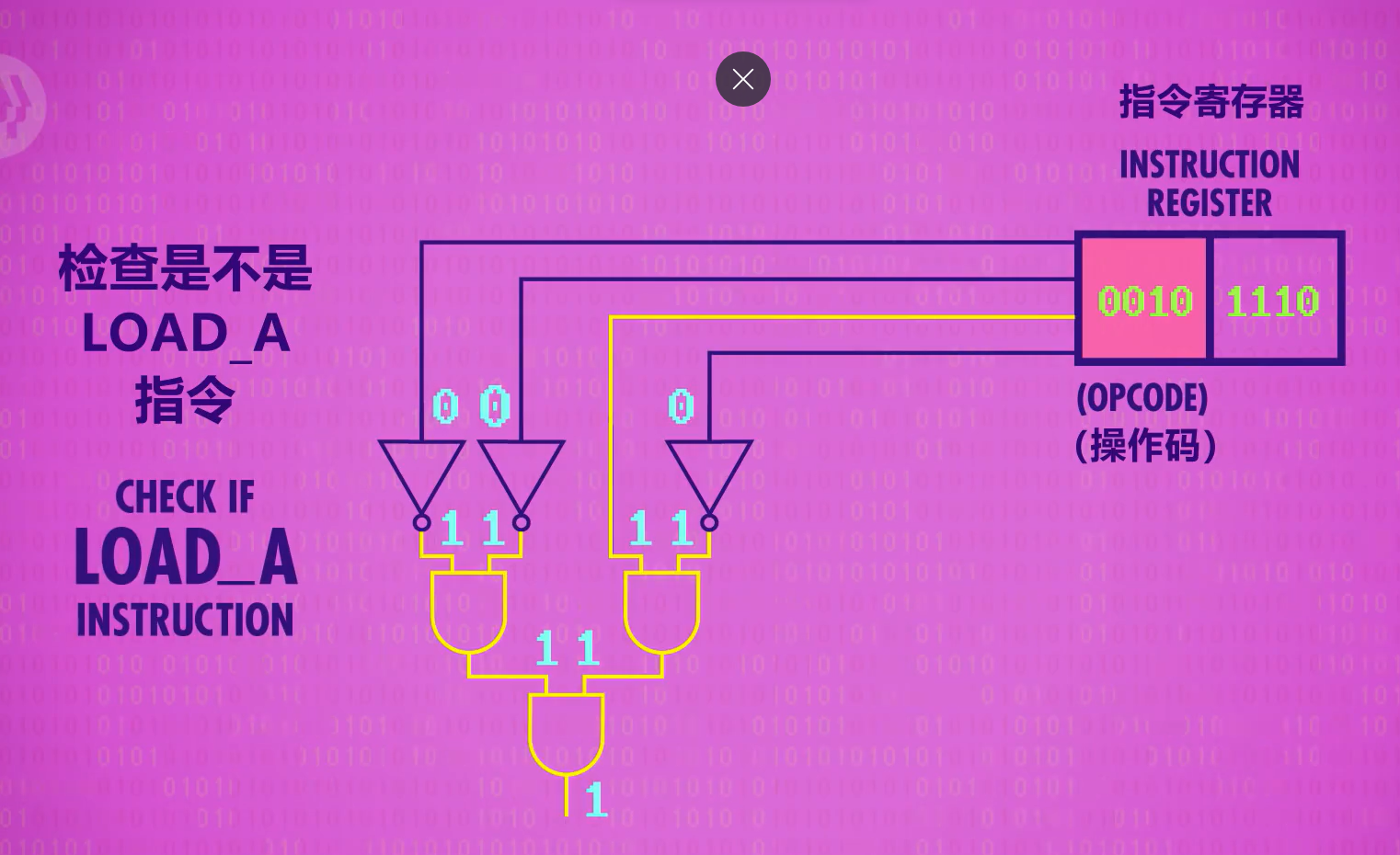
执行阶段(Execute Phase)
将后四位地址对应的数据存入RegA
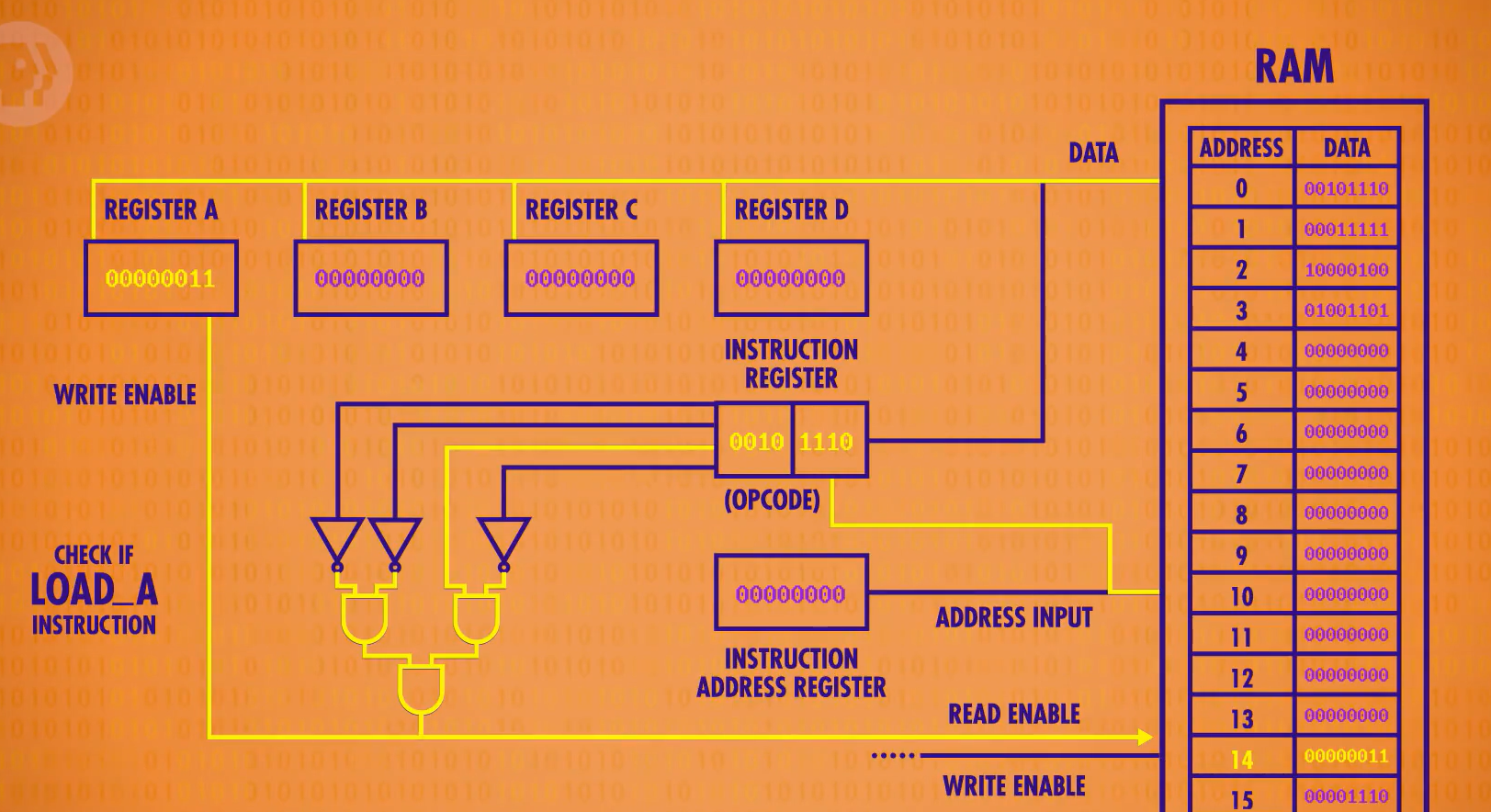
执行结束后我们即可关闭所有线路,同时让OAE执行一次increment,以准备下一个循环。
下图为RAM里的程序全部执行后的状态。
以上,我们能看到CPU的基本运作流程的三个阶段。
时钟速度(Clock Speed)
时钟速度指CPU进行三个阶段的速度(\(取址\rightarrow 解码\rightarrow 执行\)),单位为Hz,即CPU的时钟信号。时钟速度可作为CPU性能指标。
因电信号的固有延迟,时钟速度有相应的上限。超频即指时钟速度过快,一般的芯片都能接受稍微的超频(overclocking),但过度的超频会导致,电信号跟不上时钟,进而造成CPU过热,产生乱码;降频则相反,将CPU速度降下来,可以省电。很多现代处理器支持动态调整频率,可以按照需求进行超频和降频
最早的CPU为1971年的Intel4004,为4bitCPU,时钟速度可达740kHz。微架构与上面栗子中的CPU类似。如今常见的CPU一般为100MHz~1GHz。
完整的CPU应当包含一个时钟速度的发生器,故我们上面栗子中的CPU还不是完整的其缺少一个时钟。
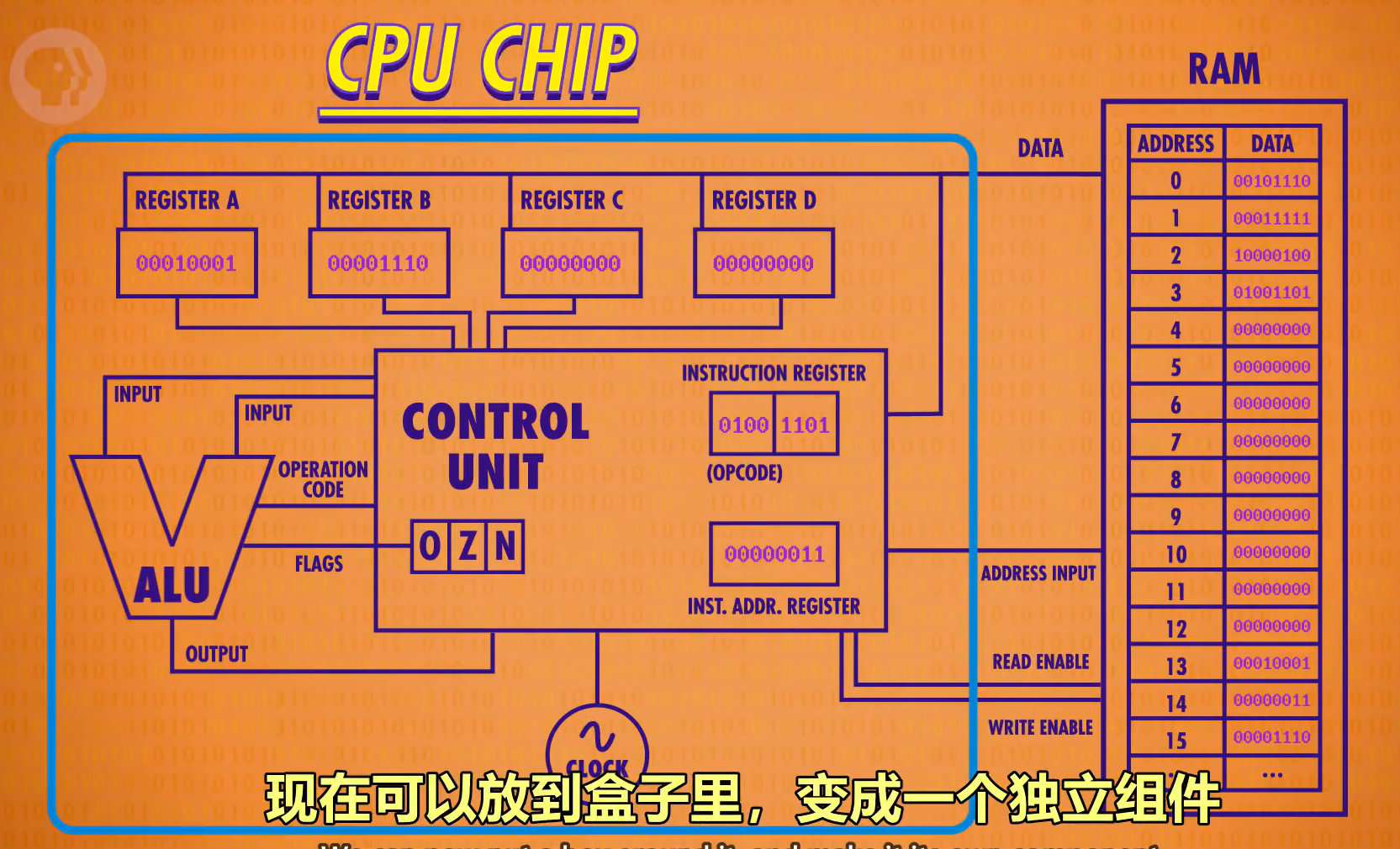
CPU与RAM的连接
注意,上面的栗子中,CPU与RAM的连接并不是一条线,而是通过数据线、地址线、允许读/写线进行通信。
指令与程序
这里介绍两个CPU常用的指令。
- JUMP:正常来说,指令是按照顺序执行(IAG的increment操作),而该指令将会跳入相应位置的指令。例如
jump 0表示跳回开头。其底层实现方式为将相应的指令后四位用于覆盖IAG - HALT:设置指令执行到哪一步指令停止。
储存在内存中的一连串设计好的指令即可被视为一个软件程序。通过巧妙的设计可以让ALU通过加减法实现乘除法。
回到之前提到的栗子。之前的栗子中我们能发现,CPU和RAM都是8bit的,前四位为opcode,后四位为address,这意味着我们最多只能处理16个指令和16个地址。最直接的办法就是增加更多的位来代表指令,例如32bit/64bit,这被称为 指令长度(instruction length)。
另一种策略是 ”可变指令长度“,针对不同的指令,对地址位进行处理。例如,HALT不需要地址为,那么其地址位可以去除;JUMP指导需要地址位,那么就即时加上地址位,这种即时加上的数据被称为 立即值(immediately value)。
Intel4004有44种指令,包括
jump,add,sub,load等等,采用的即为”可变指令长度“策略。现代CPU,例如Intel Core i7,包含上千个指令,长度为1~15bit。
可变指令长度
building
高级CPU设计
CPU的发展伴随着复杂度与速度的矛盾。
速度的提高要求RAM的速度也要跟上,而RAM读取数据往往需要多个操作。下面介绍两个提升性能的方法:
缓存(cache)
一种解决方法是在CPU里面加一点RAM,即 缓存(cache)。CPU从RAM取数据便不用一个一个拿,而是一批一批拿,而CPU依旧是一个一个处理,这样即便读取时间增长了,依旧能让RAM跟上CPU的速度。
CPU想要的数据已经在缓存中,那么就叫 缓存命中(cache hit),否则叫 缓存未命中(cache miss)。
缓存也可以作为临时空间,供CPU的中间数据或结果值存放,以此优化复杂运算。但是这样会造成缓存与RAM产生不一致的地方,为了方便同步,缓存的每一块空间会有特殊标记叫做 脏位(dirty bit)。
同步一般发生在缓存满了而CPU又需要缓存的时候。同步时首先会检查脏位,如果是脏的,那么在加载新内容前会将缓存的数据写回RAM。
缓存一般只有KB或MB大小。而RAM一般是GB起步。
指令流水线(instruction pipelining)
CPU的每个阶段用的是CPU的不同部分,这意味着我们可以并行处理。在解码的时候,我们可以进行新的取址操作,而不是等到执行操作结束后。以此类推。原本每3个时钟周期执行1个指令,现在1个时钟周期执行1个指令。
但是这样可能会遇到两个问题:
- 数据依赖性:数据依赖性是指一些指令的操作可能会改变内存里的某些数据。这意味着当你在读取某个数据,而此时并行的执行操作可能会修改你读取的数据。所以这种流水线处理器需要弄清楚数据的依赖性,在必要时停止流水线,避免出现问题。
- 笔记本和手机里的高端CPU能够更进一步地动态排序有依赖关系的指令,最小化流水线的停工时间,这叫 乱序执行(out-of-order execution)。当然这种CPU的电路十分复杂。
- 条件跳转:
jump一类的指令会改变程序的执行流。针对地,简单的处理器会等待这类指令给出结果后再继续执行,这样会造成延迟;而高端处理器则有更高级的技巧。- 将这类指令当作“岔路口”,让CPU去猜测哪条路的可能性更大,然后提前将指令放入流水线,以避免相应的延迟,这叫 推测执行。当这类指令的结果出了,如果CPU猜对了,那么就可以直接运行已经放好正确指令的流水线,否则就得清空流水线重新填充,就像分岔口走错路需要退回来(Pipeline Flush)。为减少清空流水线的情况(pipeline flush),人们开发了 分支预测(branch prediction) 用于更精确地预测分支。现代CPU的分支预测正确率可达90%以上。
超标量处理器(superscalar)
常规CPU正常是一个时钟周期完成一条指令。而超标量处理器能一个时钟周期完成多条指令。这类CPU有两种提升性能的方法:
- 充分利用CPU闲置部分:流水线设计下的执行阶段,CPU依旧有些可能会空闲的部分,例如读取内存时ALU会闲置,而且很多现代CPU里面相同的ALU远远不止一个,所以能够一次性处理多条使用后CPU不同部分的指令。这就有了超标量处理器。
- 同时运行多个指令流:之前一直都在讨论一条指令流的情况。多核处理器意识是CPU芯片里有多个独立处理单元,可以看成是多个独立的、但是整合紧密的、由此可以共享一些资源(例如缓存)的CPU,一些资源的共享使得他们能够合作运算。
当然,从应用角度来说,可以直接大量使用CPU。例如大型服务器、超级计算机(supercomputer)。CPU的一种指标为FLOPS(floating point math operations per second),即 每秒浮点运算次数。