计算机网络学
《无线网络应用》
计算机网络这部分具体可前往我的 ZJU_Coure->其它有趣的课程->《无线网络应用》的笔记深入地学习计算机网络的基础知识。
计算机网络
局域网与以太网
第一个计算机网络出现于上世纪50~60年代,属于 局域网(local area network/LAN),当时被称为 球鞋网络(sneaker net)。早期网络可以共享 I/O 和内存。
LAN技术中比较成功的是70年代的 以太网(Ethernet)。计算机之间用以太网线连接,为了让数据的传输想RAM一样精确传输,我们需要类似地址的东西,于是每台电脑为方便以太网传输设置了世界上独一无二的 媒体访问控制地址(media access control address/MAC address)。这东西被放入了数据帧的帧头。
这种多台电脑共享一个传输媒介的形式叫 载波侦听多路访问(carrier sense multiple access/CSMA),载体(carrier)指的是共享媒介,如以太网的载体是铜线,WiFi的载体是空气。这种模式下是多台电脑同时侦听载体,故为侦听、多路。
载体传输数据的速度叫做 带宽(bandwidth)。
CSMA模式下,会出现两台电脑同时发出数据的 冲突(collision)情况,而且如果不适当处置可能会导致冲突越来越多。一种解决办法是每台电脑发数据时都检测是否有冲突,如果有,就等待一段时间,这段时间每台电脑每次都是随机的——当然会依概率收敛;如果等了之后还是有冲突,就增加等待时间继续等,依此类推。等待时间的增加被设置为指数级增长,于是这种方法叫 指数退避(exponential backoff)。以太网和WiFi等很多传输协议都用这种方法。
会参与冲突的设备组成的网络叫 冲突域(collision domain)。显然我们也应当减少一个冲突域里的设备。于是有了沟通各个冲突域的东西 交换机(switch)。
分组交换
直接用一条专用线缆用于通信的方式叫 电路交换(circuit switching)。这种方式昂贵且不灵活,但十分安全,能够专用。军队等机构目前也会用这种方式,如国防光缆。
另一种方式是 报文交换(message switching),模式类似邮政系统。不同于专用线路,信息会经过多个中转站。这种方式好处是可以使用不同的 路由(route),可靠且更加 容错(fault-tolerant)。这种模式下,信息沿着路由跳转的次数叫做 跳数(hop count)。如果某个信息的跳数很高,就知道肯定出问题了,这种debug方式叫 跳数限制(hop limit),相应的有 生存时间(time to live/TTL) 的概念。
这种模式的坏处是如果有大文件,那么可能会阻塞一整条路。解决方法是将大文件拆分为多个小的 数据包(packet)。数据包具体的格式由出现在70年代的 互联网协议(Internet protocol/IP协议) 规定。同时,每台联网的计算机需要一个 IP地址,让数据包知道目的地。
此外,为了平衡各条线路的负载,各个路由器与·1其它路由器都会进行平衡,这叫 阻塞控制(congestion control)。
还有个问题是,同一个文件是按顺序拆分为多个数据包是分开运输的,到达顺序不同可能会出现问题,于是在IP协议之上出现了 TCP/IP协议 用于解决到达顺序的问题。
这种数据包拆分后按照报文交换进行运输的方式叫 分组交换(packet switching)。
如今,全球的路由器协同工作,以找出最高效的线路,并使用各种标准协议来运输数据,如 因特网控制消息协议(ICMP),边界网关协议(BGP)。
互联网
WAN
LAN会连接到 广域网(wide area network/WAN),WAN的路由器由 互联网服务提供商(Internet service provider/ISP)提供。
UDP
数据包在互联网上传输,需要符合IP协议的标准。
IP是非常底层的协议。IP负责指定数据包送到哪台电脑,需要更高级的协议指定数据包送给哪个程序,这类协议中常用的是 用户数据报协议(user datagram protocol/UDP),UDP header包含一个 端口号(port number)。
每个想访问网络的程序都需向OS申请一个端口号,且对于一个程序,申请的端口号一般是固定的。计算机通过读取UDP头部的端口号来确定数据包该给哪个程序。
UDP头部还有 校验和(checksum),用于通过将数据包的数据加在一起看是否等于校验和来判断数据是否正确。校验和只有16bit。UDP不提供数据修复、数据重发的机制,所以数据损坏只能扔掉。UDP也不能让 发送方(sender) 和 接收方(receiver) 知道数据包是否成功发送或接收。不过UDP简单且快速。
需要保证所有数据包都能到达,就用 传输控制协议(transmission control protocol/TCP)。
TCP
IP+TCP的协议组合被称为 TCP/IP。TCP也有UDP中的端口号和校验和,不过还有很多更高级的功能,例如:
- TCP数据包包含 序号(sequential number) 以保证数据包接收后按序号重新排好序号
- TCP要求发送方一点一点发送数据包。接收方收到数据包并检查校验和后给会发送方发一个 确认码(acknowledgement/ACK) ,表示收到了正确的数据包。收到ACK后发送方才会发出下一个数据包。
- 如果一段时间后还没收到ACK,发送方会重新发出数据包。
- 如果未收到ACK是因为ACK路上丢失,也不用担心重复的数据包,接收方会根据序列号来排列数据包,重复的就丢弃。
- ACK码的成功率和来回时间还可以推测网络拥堵程度
实际上TCP并不是一个一个发送数据包,也可以一组一组发,ACK也一组一组地接受。
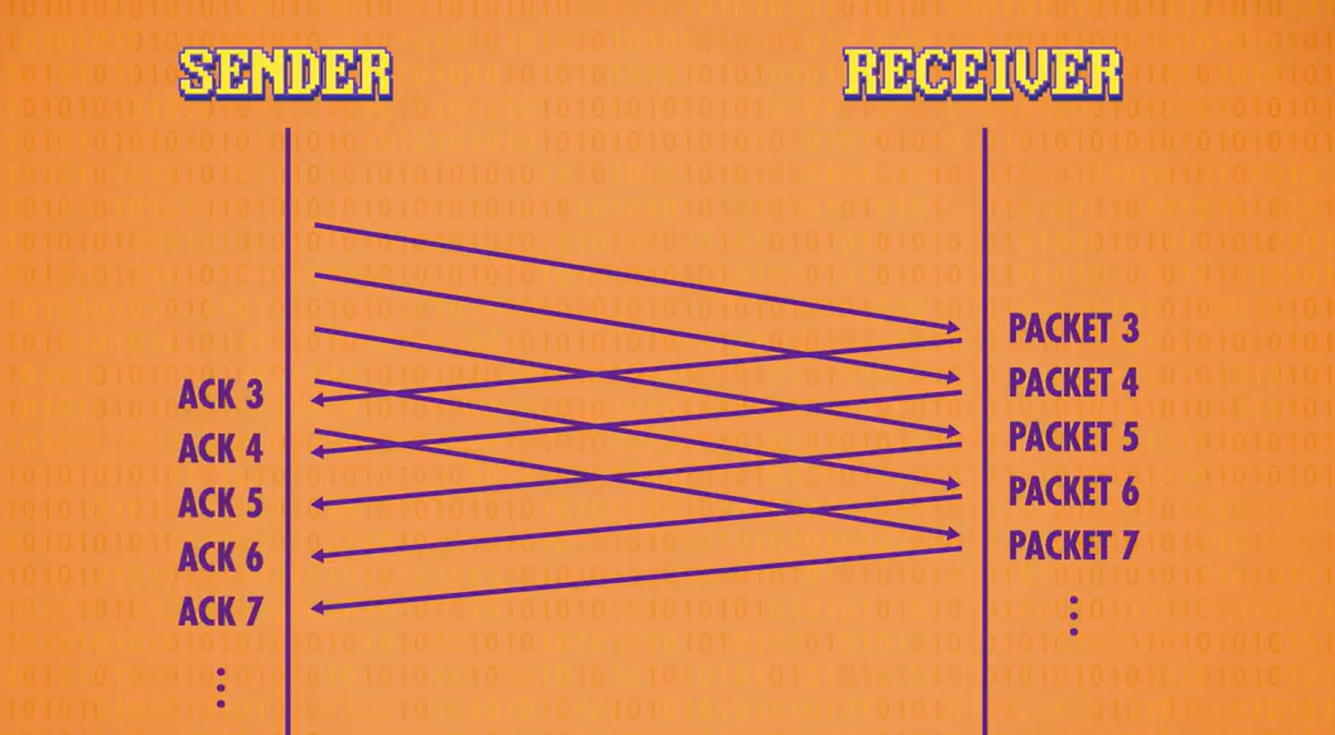
综上,TCP可以处理乱序、丢包,并根据拥挤情况调整传输率。
TCP vs UDP
看起来TCP功能上完全碾压UDP,但是TCP的缺点是ACK的存在,这让传输量和传输时间翻倍了,这对那些对时间有要求的程序是不值得的、无法接受的,如线上游戏。而UDP简单且快速。
域名
DNS
计算机访问网站需要两个东西:IP地址和端口号。但是一串数字比较难记。于是有了与IP地址一一对应的域名。负责处理这个映射的系统叫 域名系统(domain name system/DNS)。用域名访问网站时,域名会先交给DNS服务器返回相应的IP地址,然后才真正去访问这个网站。
域名结构
域名太多了,为了方便管理,域名采用了树形结构:
- 顶级域名(top level domain/TLD)在最顶部,如
.com,.gov - 下一层是 二级域名(second level domain),如
google.com,edu.cn - 第三层为 子域名(subdomain),如
images.google.com,zju.edu.cn,
一般说有多少个域名是指二级域名,如2018年有三千万个(二级)域名
现实中,处理一个域名一般会交给很多个DNS服务器,不同服务器负责树的不同部分
网络层级
最底层是,物理层(physical layer)。,包括以太网用的电信号、无线网络用的无线信号等等。
往上一层是数据链路层(data link layer) ,负责操控物理层,包括:MAC地址、碰撞检测、指数退避,以及一些其它的底层协议。
再上一层是 网络层(network layer),负责各种报文交换和路由。
再往上是 传输层(transport layer),包括上面讲的UDP、TCP这类协议,负责在计算机之间进行点到点的传输、错误检测与修复。
再往上是 会话层(session layer),这一层使用TCP和UDO等协议进行 会话(session)——创建连接、来回传递信息、关闭连接。例如与DNS服务器会话、与网页会话。
此外还有 表示层(presentation layer) 和 应用程序层 (application layer)。
以上是 开放式系统互联通信参考模型(open system interconnection model/OSI模型)。
OSI模型一个概念性框架,将网络通信划分成多层,每一层处理各自的问题,方便分工与改进,是一种隐藏复杂度的办法。

万维网
互联网 vs 万维网
互联网(The Internet) \(\neq\) 万维网(The World Wide Web)
不过人们经常混用两者。万维网在互联网的基础上运行,两者不是一个概念的。
互联网是传递数据的管道,各个程序都会用到,其中传输最多数据的程序就是万维网。万维网是一个程序,这个程序分布在全球数百万个服务器上,可以用浏览器来访问这个程序。
万维网(World Wide Web/web)是一个程序,其基本单位是单个 页面(page)。为了使网页相互连接,每个网页需要一个唯一确定的地址,被叫做 统一资源定位器(uniform resource locator/URL)。
请求流程
下面我们举个例子,访问 www.bilibili.com/user这个页面。
我们的计算机通过域名www.bilibili.com从DNS服务器获取到网页的ip地址148.153.34.154。而web服务器标准端口是80,我们的计算机通过端口80连接到这个ip地址对应的web服务器。也就是说域名对应的是web服务器地址。web服务器里面有很多页面。
下一步是 请求(ask) 服务器里面的一个页面。这用到了 超文本传输协议(hypertext transfer protocol/HTTP)。最早的HTTP是1991年出现的HTTP0.9,只有一个指令 GET。计算机连接上服务器后,通过端口向服务器发出指令 GET/user,该指令通过ascii编码发送到服务器,进而返回对应的页面,浏览器会将其渲染在屏幕上。不过这样可以轻松被破译,于是有了带价加密的https协议。
之后的HTTP加入了 状态码(state code),比如404。
超文本的储存和发送都是以文本形式,意思是是编码方式为ascii或utf-8之类的。为了表明不同文本的作用,人们在1990年开发了 超文本标记语言(hypertext markup language/HTML)。其它相关的介绍有 层叠样式表(cascading style sheet/CSS)。
!!!"前端笔记" 我之前闲着没事学了一点点前端的东西,主要是html+css+javascript,感兴趣的话可以前往 技术积累-->网页前端 看看。
浏览器
浏览器(web browser) 负责与web服务器建立连接,获取网页并负责显示。
搜索引擎
随着万维网发展,网站越来越多,单纯一个目录网站负责罗列所有的域名已经不够用了,于是搜索引擎来了。