机器学习三大方法
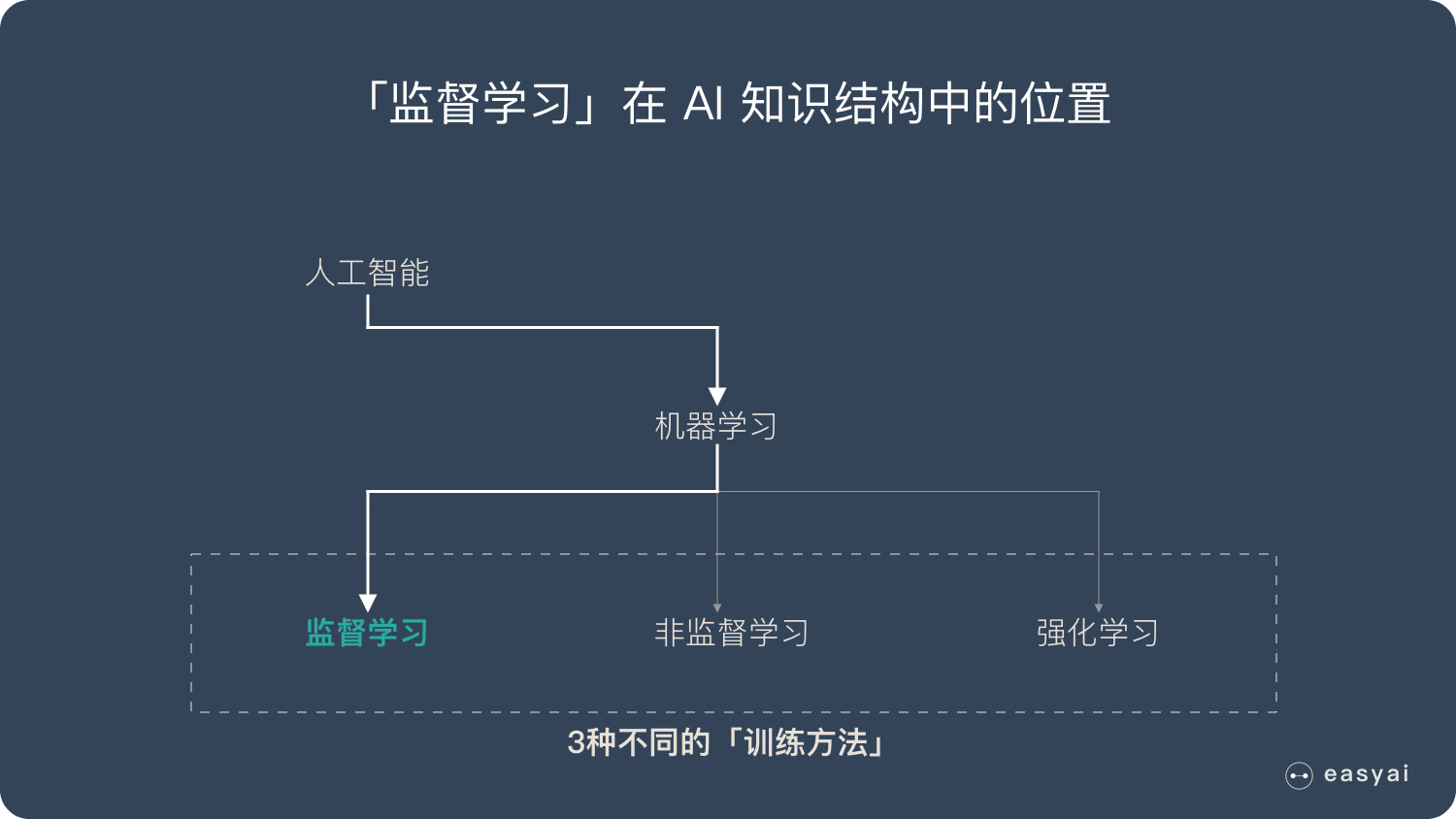
监督学习 – Supervised learning
监督学习需要有明确的目标,很清楚自己想要什么结果。
比如:按照“既定规则”来分类、预测某个具体的值…
监督并不是指人站在机器旁边看机器做的对不对,而是下面的流程:
- 选择一个适合的数学模型
- 先把一部分已知的“问题和答案”(训练集)给机器去学习
- 监督体现在这,提供的训练数据是人类处理过的
- 机器总结出了自己的“方法论”
- 人类把”新的问题”(测试集)给机器,让他去解答
监督学习的2个任务:回归、分类
- 回归:预测连续的、具体的数值。
- 分类:对各种事物分门别类,用于离散型预测。

回归案例有:芝麻信用分
分类安陆有:人格预测
主流的监督学习算法
| 算法 | 类型 | 简介 |
|---|---|---|
| 朴素贝叶斯 | 分类 | 贝叶斯分类法是基于贝叶斯定定理的统计学分类方法。它通过预测一个给定的元组属于一个特定类的概率,来进行分类。朴素贝叶斯分类法假定一个属性值在给定类的影响独立于其他属性的 —— 类条件独立性。 |
| 决策树 | 分类 | 决策树是一种简单但广泛使用的分类器,它通过训练数据构建决策树,对未知的数据进行分类。 |
| SVM | 分类 | 支持向量机把分类问题转化为寻找分类平面的问题,并通过最大化分类边界点距离分类平面的距离来实现分类。 |
| 逻辑回归 | 分类 | 逻辑回归是用于处理因变量为分类变量的回归问题,常见的是二分类或二项分布问题,也可以处理多分类问题,它实际上是属于一种分类方法。 |
| 线性回归 | 回归 | 线性回归是处理回归任务最常用的算法之一。该算法的形式十分简单,它期望使用一个超平面拟合数据集(只有两个变量的时候就是一条直线)。 |
| 回归树 | 回归 | 回归树(决策树的一种)通过将数据集重复分割为不同的分支而实现分层学习,分割的标准是最大化每一次分离的信息增益。这种分支结构让回归树很自然地学习到非线性关系。 |
| K邻近 | 分类+回归 | 通过搜索K个最相似的实例(邻居)的整个训练集并总结那些K个实例的输出变量,对新数据点进行预测。 |
| Adaboosting | 分类+回归 | Adaboost目的就是从训练数据中学习一系列的弱分类器或基本分类器,然后将这些弱分类器组合成一个强分类器。 |
| 神经网络 | 分类+回归 | 它从信息处理角度对人脑神经元网络进行抽象, 建立某种简单模型,按不同的连接方式组成不同的网络。 |
无监督学习 – Unsupervised learning | UL
监督学习 vs 无监督学习
- 监督学习是一种目的明确的训练方式,你知道得到的是什么;而无监督学习则是没有明确目的的训练方式,你无法提前知道结果是什么。
- 监督学习需要给数据打标签;而无监督学习不需要给数据打标签。
- 监督学习由于目标明确,所以可以衡量效果;而无监督学习几乎无法量化效果如何。
无监督学习本质上是一个统计手段,在没有标签的数据里可以发现潜在的一些结构的一种训练方式。
说白了就是让机器去训练集里找相同与不同,进行分类
常见的2类无监督学习算法
- 聚类:一种自动分类的方法
- 降维:看上去很像压缩,在尽可能保存相关的结构的同时降低数据的复杂度。

「聚类算法」K均值聚类
K均值聚类 就是制定分组的数量为K,自动进行分组。
步骤如下:
- 定义 K 个重心。一开始这些重心是随机的。
- 寻找最近的重心并且更新聚类分配。
- 将每个数据点都分配给这 K 个聚类中的一个。
- 每个数据点都被分配给离它们最近的重心的聚类。
- 这里的「接近程度」的度量是一个超参数——通常是欧几里得距离。
- 将重心移动到它们的聚类的中心。
- 每个聚类的重心的新位置是通过计算该聚类中所有数据点的平均位置得到的。
重复第 2 和 3 步,直到每次迭代时重心的位置不再显著变化(即直到该算法收敛)。
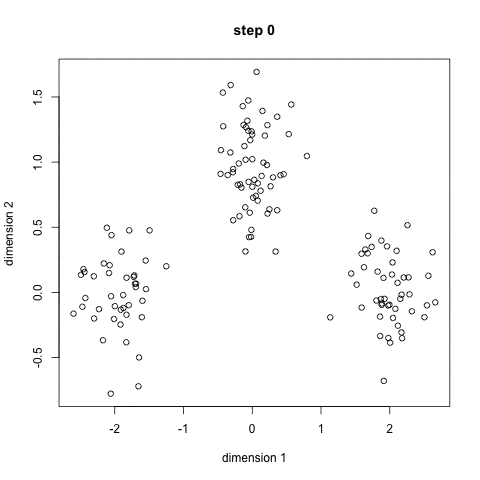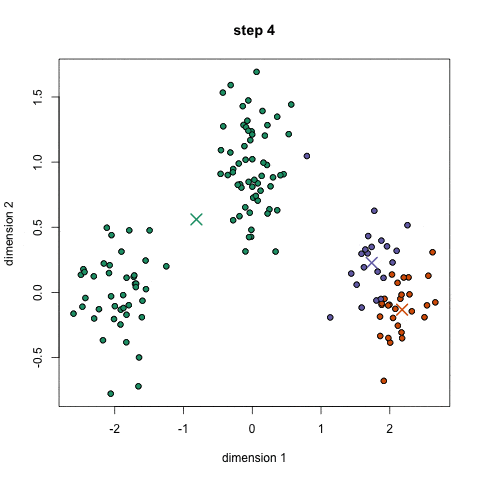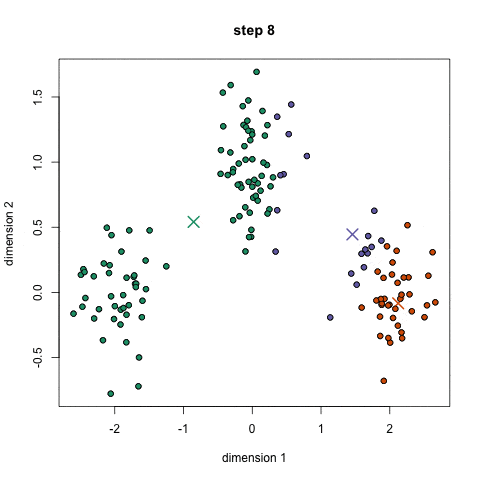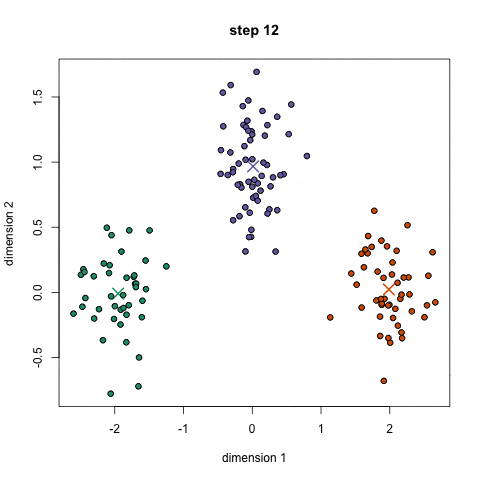
「聚类算法」层次聚类
如果不知道应该分为几类,那么层次聚类就比较适合了。
层次聚类会构建一个多层嵌套的分类,类似一个树状结构。
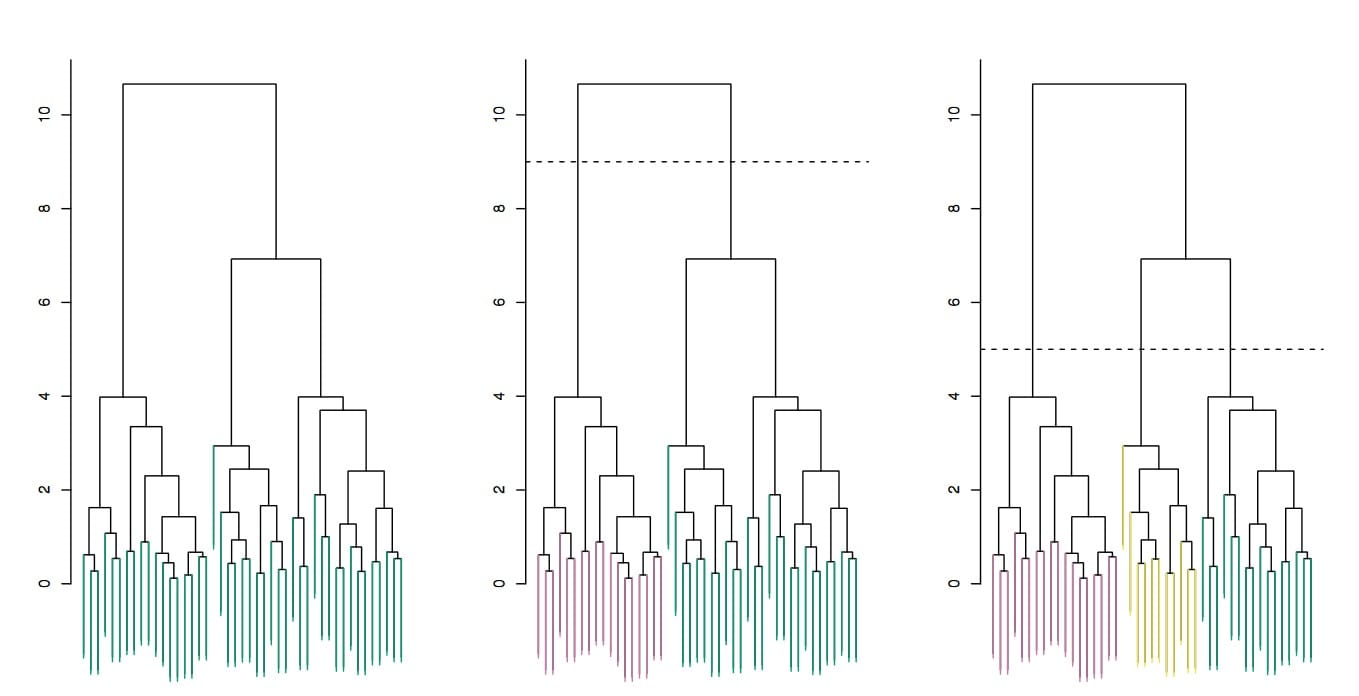
步骤如下:
- 首先从 N 个聚类开始,每个数据点一个聚类。
- 将彼此靠得最近的两个聚类融合为一个。现在你有 N-1 个聚类。
- 重新计算这些聚类之间的距离。
- 重复第 2 和 3 步,直到你得到包含 N 个数据点的一个聚类。
- 选择一个聚类数量,然后在这个树状图中划一条水平线。
「降维算法」主成分分析 – PCA
主成分分析是把多指标转化为少数几个综合指标。
常用于减少数据集的维数,同时保持数据集的对方差贡献最大的特征。
这是通过保留低阶主成分,忽略高阶主成分做到的。这样低阶成分往往能够保留住数据的最重要方面。
变换的步骤:
- 第一步计算矩阵 X 的样本的协方差矩阵 S(此为不标准PCA,标准PCA计算相关系数矩阵C)
- 第二步计算协方差矩阵S(或C)的特征向量 e1,e2,…,eN和特征值 , t = 1,2,…,N
- 第三步投影数据到特征向量张成的空间之中。利用下面公式,其中BV值是原样本中对应维度的值。
强化学习-Reinforcement learning | RL
引入
Flappy bird 就是一个典型的强化学习场景:
- 机器有一个明确的小鸟角色——代理
- 需要控制小鸟飞的更远——目标
- 整个游戏过程中需要躲避各种水管——环境
- 躲避水管的方法是让小鸟用力飞一下——行动
- 飞的越远,就会获得越多的积分——奖励
强化学习和监督学习、无监督学习 最大的不同就是 不需要大量的“数据喂养”。
而是通过机器自己不停的尝试来学会某些技能。
强化学习的主流算法
免模型学习(Model-Free) vs 有模型学习(Model-Based)
这2个分类的重要差异是:智能体是否能完整了解或学习到所在环境的模型
有模型学习(Model-Based)对环境有提前的认知,可以提前考虑规划,但是缺点是如果模型跟真实世界不一致,那么在实际使用场景下会表现的不好。
免模型学习(Model-Free)放弃了模型学习,在效率上不如前者,但是这种方式更加容易实现,也容易在真实场景下调整到很好的状态。
所以免模型学习方法更受欢迎,得到更加广泛的开发和测试。
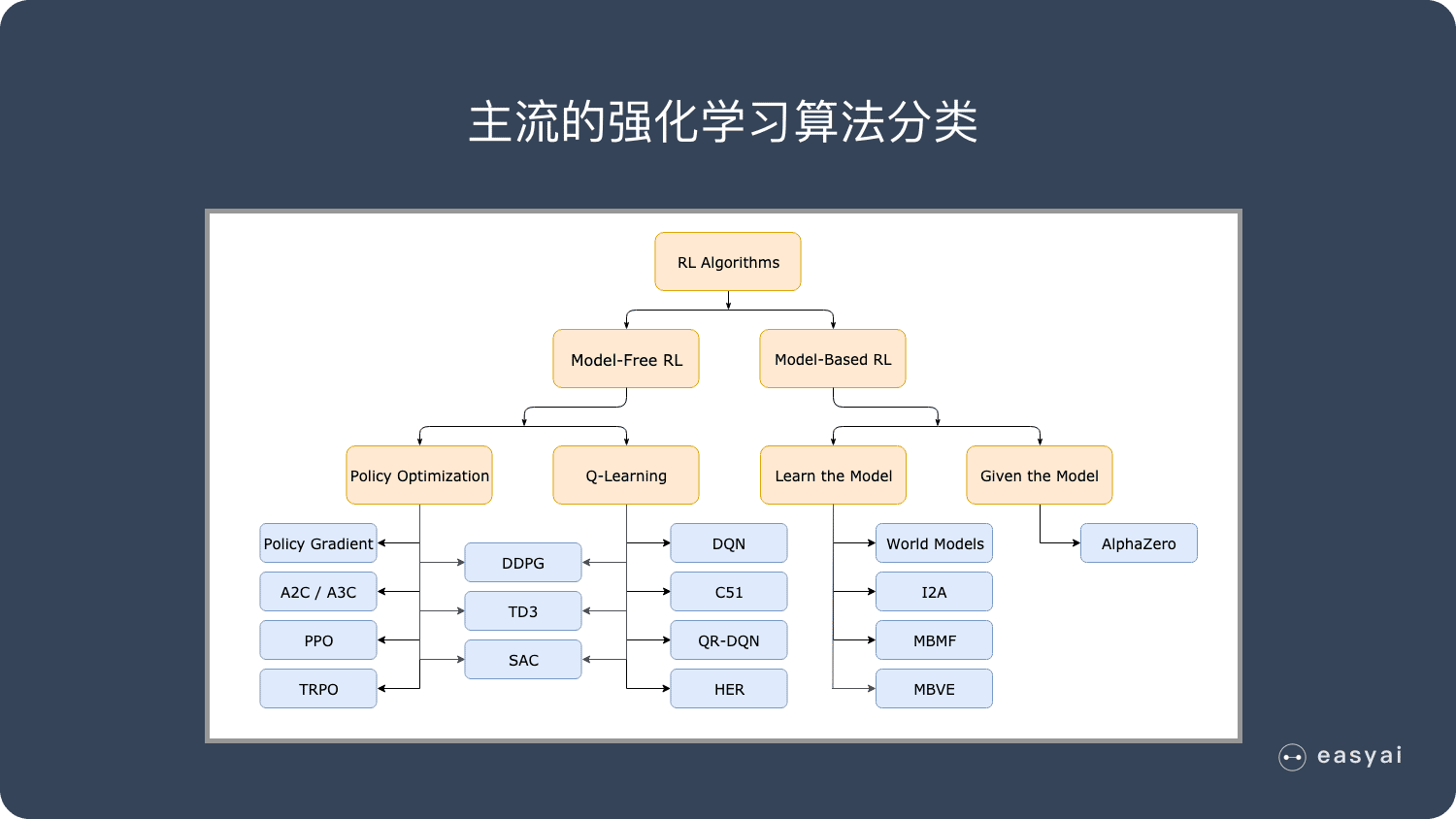
免模型学习 – 策略优化系列(Policy Optimization)
这个系列的方法将策略显示表示为:\(\pi_{\theta}(a|s)\)
它们直接对性能目标 \(J(\pi_{\theta})\) 进行梯度下降,或间接地对性能目标的局部近似函数进行优化。
优化基本都是基于 同策略 的,即每一步更新只会用最新的 策略执行时采集到的数据。
策略优化通常还包括学习出 $V_{\phi}(s) $ ,作为 $V^{\pi}(s) $ 的近似,该函数用于确定如何更新策略。
免模型学习 – Q-Learning
这个系列的算法学习最优行动值函数 \(Q^*(s,a)\) 的近似函数: \(Q_{\theta}(s,a)\) 。
它们通常使用基于 贝尔曼方程 的目标函数。
优化过程属于 异策略 系列,这意味着每次更新可以使用任意时间点的训练数据,不管获取数据时智能体选择如何探索环境。
对应的策略是通过 \(Q^*\)and \(\pi^*\) 之间的联系得到的。
智能体的行动由下面的式子给出:
\(a(s) = \arg \max_a Q_{\theta}(s,a)\)
有模型学习 – 纯规划
这种最基础的方法,从来不显示的表示策略,而是纯使用规划技术来选择行动,例如 模型预测控制 (model-predictive control, MPC)。
在模型预测控制中,智能体每次观察环境的时候,都会计算得到一个对于当前模型最优的规划,这里的规划指的是未来一个固定时间段内,智能体会采取的所有行动(通过学习值函数,规划算法可能会考虑到超出范围的未来奖励)。
智能体先执行规划的第一个行动,然后立即舍弃规划的剩余部分。
每次准备和环境进行互动时,它会计算出一个新的规划,从而避免执行小于规划范围的规划给出的行动。
有模型学习 – Expert Iteration
纯规划的后来之作,使用、学习策略的显示表示形式: \(\pi_{\theta}(a|s)\) 。
智能体在模型中应用了一种规划算法,类似蒙特卡洛树搜索(Monte Carlo Tree Search),通过对当前策略进行采样生成规划的候选行为。
这种算法得到的行动比策略本身生成的要好,所以相对于策略来说,它是“专家”。
随后更新策略,以产生更类似于规划算法输出的行动。
除了免模型学习和有模型学习的分类外,强化学习还有其他几种分类方式:
- 基于概率 VS 基于价值
- 回合更新 VS 单步更新
- 在线学习 VS 离线学习
详细请查看