基于 Mindspore 的 Prompt Tuning 实验
2025 年 5 月 8 日 lab3.pdf
姓名:俞仲炜 学号:3220104929
Project Introduction
选题
本项目选题为提示词学习(Prompt Learning),旨在对比硬提示与软提示在情感分类任务中的效果差异,探索软提示调优(Soft Prompt Tuning)在小样本学习和参数高效微调中的潜力。
开发环境及系统运行要求
编程语言:Python
深度学习框架:MindSpore 2.4.0
平台镜像:mindspore_2.4.0-cann_8.0.rc3-py_3.9-euler1̇0-aarch64-snt9b
主要依赖库:mindspore, mindnlp, datasets, peft
硬件要求:Ascend
Technical Details
工程实践当中所用到的理论知识
本次实验主要基于 Prompt Learning 理论,利用预训练模型 Roberta 进行下游任务调优
Prompt Learning 是利用提示词引导预训练语言模型完成特定下游任务的技术,分为两类:
- 硬提示(Hard Prompt):添加固定的自然语言片段,如“这个句子的情感是:”。
- 软提示(Soft Prompt):引入可训练的嵌入向量,无需更改模型结构,只对少量参数进行学习,效率更高。
硬提示学习首先将预定义的标记添加到模型的输入中,然后直接使用预训练模型对输入进行分类预测;软提示学习首先为预训练模型增加一串可训练的嵌入向量,然后在训练过程中根据下游任务的需求优化和更新模型
具体算法概述
本实验中,软训练的核心流程为,对于每一轮 epoch 先调用反向传播函数 grad_fn 得到当前 batch 的损失和梯度,然后用 optimizer.step(grads) 更新 soft prompt 向量参数,最后执行 lr_scheduler.step() 调整当前学习率。一轮训练结束后进入评估阶段,该阶段会先遍历验证集,对每一个 batch 进行模型预测,取预测结果的最大概率类别作为最终分类结果,这里使用了 metric.add_batch() 累计预测与标签,用于后续计算评估指标。最终我们通过 metric.compute() 得到综合性能评价指标,结束当前 epoch。
硬训练的流程则十分简单,首先将原始输入句子转换为带有自然语言提示的格式,并对整个数据集进行预处理和批量填充,形成可供模型推理的数据迭代器,然后交给预训练模型进行推理。
重要的技术细节
本次实验使用到了 MindSpore.peft 模块,通过该模块提供的 get_peft_model 函数,我们十分便利地为预训练模型添加了可学习的 soft prompt。由于其 mindnlp 中的源码无法访问,这里以 Transformers 库中的 peft 模块为例进行进行分析,相关代码位于 src/peft/mapping_func.py 中。
get_peft_model 首先解析传入的 peft_config,确定所使用的 PEFT 方法,然后根据配置,将基础模型包装为对应的 PeftModel 子类。在包装过程中,模块会根据配置将适配器模块注入到基础模型的指定位置。为了实现参数高效的微调,该模块会冻结基础模型中除适配器模块外的所有参数,仅允许适配器模块的参数在训练中更新。最终,get_peft_model 返回一个包含适配器模块的 PeftModel 实例。
此外,本次实验中用到的关键函数有:
value_and_grad(forward_fn, None, model.trainable_params()):用于构造同时计算 loss 与梯度的高阶函数optimizer.step(grads):在每个训练 batch 后执行,用于更新 soft prompt 向量参数(主模型参数被冻结,不被更新)。lr_scheduler.step():动态调整学习率,增强训练稳定性
Experiment Results
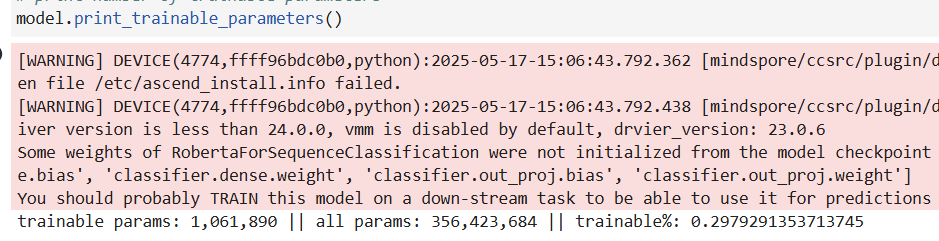
加载模型并打印微调参数量,可以看到仅有你不到 0.3%的参数参与了微调:
检查预处理后的数据集,已得到正确处理:

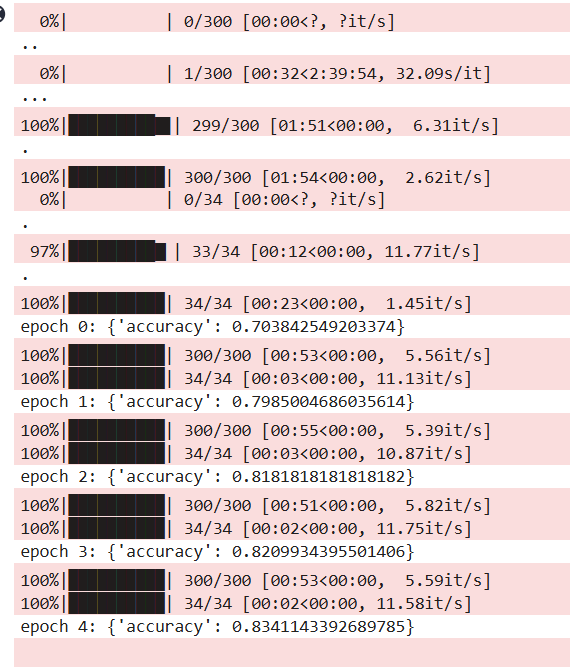
进行软提示训练,此处可以看到软训练模型最终的精确度是 83.41%:
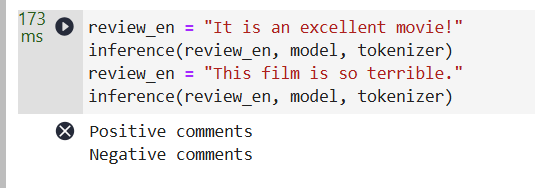
采样测试,均正确:
硬提示训练评估结果,准确率为 49.95%:

采样测试,一对一错:

References
- MindSpore 官方文档
- Transformers 官方仓库