基于 Mindspore 的 CoT 实验
2025 年 5 月 23 日 lab4.pdf
姓名:俞仲炜 学号:3220104929
Project Introduction
选题
本项目选题为 Chain-of-Thought(CoT)推理方法,旨在探索大语言模型在需要中间推理步骤的问题上的表现与能力提升。
开发环境及系统运行要求
编程语言:Python
深度学习框架:MindSpore 2.4.0
平台镜像:mindspore_2.4.0-cann_8.0.rc3-py_3.9-euler1̇0-aarch64-snt9b
硬件要求:Ascend
开源模型:Qwen-2.5-3B
Technical Details
工程实践当中所用到的理论知识
Chain-of-Thought 推理的核心思想是通过促使语言模型生成一系列中间思考步骤来增强其在复杂任务上的表现,尤其适用于那些需要多步逻辑推演的任务。其理论基础在于,将一个复杂问题的求解过程显式地分解为多个更小、更易于处理的子步骤(即“思考链”),模型通过生成这些步骤来模拟人类的思考过程,从而提高最终答案的逻辑性和准确性。
具体算法概述
CoT 推理过程主要分为以下几个步骤:
- Step 1:构建初始提示 X₀:模板形式为:
Q: [问题内容] A: Let's think step by step. - Step 2:生成中间步骤 Z:将 X₀ 输入到 LLM,输出为思维链内容 Z。
- Step 3:构造最终提示:合并 X₀ 与 Z,形成新的提示:
- 算术题用:
[X₀] [Z] Therefore, the answer (arabic numerals) is - 常识题用:
[X₀] [Z] Therefore, among A through E, the answer is
- 算术题用:
- Step 4:获取模型输出 ŷ:输入最终提示到模型,获取模型的预测句子。
- Step 5:准确率评估
- 对 GSM8K,提取 ŷ 中的数字进行比对;
- 对 CommonsenseQA,提取首个大写字母作为选择结果。
重要的技术细节
使用的重要函数与模块:
MindFormersModel.from_pretrained:加载 Qwen 模型AutoTokenizer.from_pretrained:加载相应 tokenizertokenizer.encode,tokenizer.decode:文本编码与解码model.generate:进行文本生成推理
特别的,在数据处理部分:
- 使用 pandas 加载 parquet 格式数据,并提取前 50 条数据进行实验;
- GSM8K:从“question”列获取输入,从“answer”字段提取标准答案;
- CommonsenseQA:拼接“question”、“choices”和“text”字段作为输入。
Experiment Results
基础测试
首先进行了一个简单的测试,仅向模型提供系统提示词(System Prompt),以验证基础环境和模型能否正常工作。

结果表明,系统提示词机制和 Qwen-2.5-3B 模型能够正常交互并生成符合预期的回复。
默认双阶段 CoT 推理
使用默认的二阶段 cot 推理处理算术数据部分(GSM8K)
下图展示了其中一个样本的推理过程及结果,可以看到模型生成了详细的思考步骤,并得到了正确的答案。

在测试 50 个样本后,GSM8K 数据集的准确率约为 60%。对于 Qwen-2.5-3B 这样规模的模型,在小样本量(50 条)的 GSM8K 测试中达到 60% 的准确率,表明 CoT 方法确实能够引导模型进行有效的算术推理。但仍需使用更大规模模型或经过特定指令微调的模型进行比较,实验仍有提升空间。

同样采用默认的双阶段 CoT 推理流程处理 CommonsenseQA 数据集。下图展示了其中一个样本的推理过程及结果,该样本推理正确。

然而,在测试的 50 个样本中,大部分样本的推理结果是错误的。CommonsenseQA 数据集的准确率仅约为 24%。

24% 的准确率甚至接近随机选择。可能是因为模型能力局限,Qwen-2.5-3B 模型较小,在常识推理方面的能力可能相对较弱。此外, "Let's think step by step." 这种通用提示可能不足以激发模型在常识问答任务上进行有效的、结构化的思考,因为常识问题的思考链可能不如算术题那样明确和线性。
实验探究:不同 CoT 提示模板的效果
为探究不同 CoT 实现方式对模型性能的影响,尝试了两种不同的提示模板。
模板一:单阶段 CoT
将原始双阶段 CoT(CoT 触发句和答案提取触发句分离)合并为一个单阶段提示,以此探究双阶段与单阶段的效果差异。核心思想是减少与模型的交互次数,看是否会影响推理的连贯性或最终结果的准确性。
messages_step1 = [
[
{'role': 'system', 'content': "You are a helpful assistant."},
{'role': 'user', 'content': f"{q} Let's think step by step. Therefore, the answer (arabic numerals) is"}
]
for q in batch_q
]
实验结果:
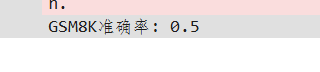
- GSM8K: 准确率为 50%,相较于双阶段 CoT 的 60%,下降了 10%。
对于算术推理任务,将思考过程的生成和答案的提取明确地分为两个阶段,可能更有利于模型分别专注于生成推理步骤和总结最终答案,从而提高准确性。单阶段提示可能导致模型在生成思考链的同时过早地关注最终答案的格式,从而干扰了推理过程。
- CommonsenseQA: 准确率依旧是 14%,下降了 10%。
原因推测同 GSM8K。

模板二:引入 Few-shot 示例
参考 Few-shot 的思路,尝试从数据集中选取数个样本(问题、CoT 提示语引导的思考链、最终答案),将其组织后作为上下文信息提供给模型,以此探究 Few-shot 示例对 CoT 推理是否有帮助。其原理是让模型通过具体的例子学习如何进行思考和作答。
FEW_SHOT_EXAMPLES = [
{
'question': "What gets wetter the more it dries?",
'choices': "A) towel B) sponge C) cloth D) shirt E) rag",
'cot_answer': "A towel gets wetter as it is used to dry things, absorbing moisture. Therefore, the answer is A.",
'final_answer': "A"
},
...
]
实验结果:
- GSM8K: 准确率为 64%,相较于双阶段 Zero-shot CoT 的 60%,相较于默认双阶段 CoT 的 56% 提升了 4%。
准确率的提升符合预期,尽管幅度不大。Few-shot 示例为模型提供了具体的解题范式,帮助其更好地理解任务要求和期望的思考链格式,从而在算术推理上表现更好。

- CommonsenseQA: 准确率为 30%,相较于默认双阶段 CoT 的 24% 提升了 6%。
虽然提升幅度有限,但仍表明提供解题范例对常识推理任务具有一定的积极作用。

References
- MindSpore 官方文档