Transformer
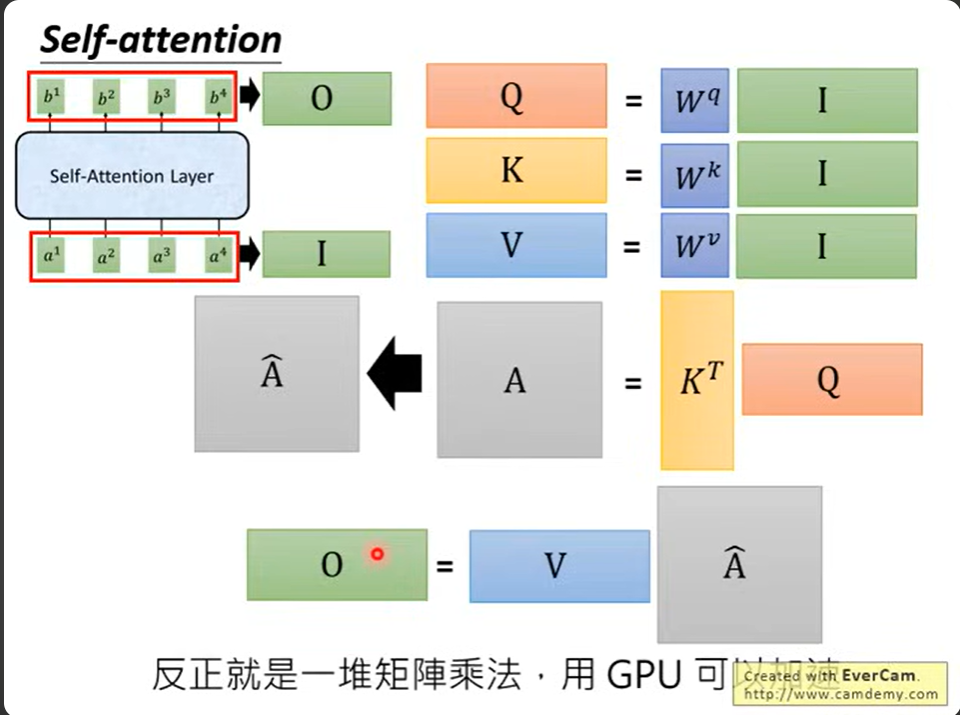
自注意力机制
自注意力机制是一种在同一个序列内部建立依赖关系的方法,它可以让模型在处理每一个词时,根据该词与其他词的相关程度动态地调整关注重点。
“自”注意力的意思是:序列中每个位置都在关注同一个序列的其他位置。
比如处理句子
"I love deep learning", “deep” 这个词可以自动学会关注 “learning” 或 “love” 等词,以构建更丰富的语义表示。
🧠 一、为什么需要自注意力?
传统的 RNN 在处理长句子时容易遗忘前面的信息。
而自注意力机制可以让模型 在每一个位置上关注到句子中所有其他位置的信息,捕捉 长距离依赖。
📐 二、自注意力机制的基本输入和输出
输入:一组向量(通常是词向量)
假设输入是一个句子的表示:
我们希望输出一个新的向量序列:
🔄 三、自注意力机制的三个核心向量:Q、K、V
每个输入 \(x_i\) 会映射出三个向量:
- Query(Q):我要问别人什么
- Key(K):我能回答哪些问题(我的身份)
- Value(V):我能提供什么信息
句子:“The animal didn't cross the road because it was too tired.”
我们要判断 “it” 指的是谁?
- “it” 发出 query:我是谁?
- 所有词(包括 “animal”)都有 key 和 value。
- 模型通过比较 “it” 的 query 和所有词的 key,判断它应该关注谁(谁最相似)。
- 如果 “animal” 的 key 和 “it” 的 query 最接近,注意力分数高,就用它的 value 更多地参与输出。
我们用线性变换得到它们:
\(Q = XW^Q,\quad K = XW^K,\quad V = XW^V\)
🧮 四、计算注意力权重
Step 1:算 Q 和 K 的点积
每个词的 query 和所有词的 key 计算相似度:
\(\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V\)
解释:
- \(QK^T\):计算每个 query 和每个 key 的相关性(打分)
- \(\sqrt{d_k}\):防止数值太大,影响梯度
- softmax:归一化,得到注意力分数(权重)
- 最后乘 V:加权求和,得到输出
假设句子是:“The animal didn't cross the road because it was too tired.”
词 “it” 的 query 会对整个句子中所有词的 key 打分。 如果模型注意到了 “animal” 是 it 的指代对象,就会给 “animal” 更高的权重。
🧮 五、矩阵形式
完整的自注意力写成矩阵形式:
\(\text{SelfAttention}(X) = \text{softmax} \left( \frac{XW^Q (XW^K)^T}{\sqrt{d_k}} \right) XW^V\)
这样可以 并行化计算,适合 GPU 处理。
🎯 六、Multi-Head Attention 多头注意力
不是只做一次注意力,而是做 h 次(多个头),每个头关注不同方面的信息:
MultiHead(Q, K, V)= Concat(head1,..., headh)WO\text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1,...,\text{head}_h)W^O
每个 head:
headi = Attention(QWiQ, KWiK, VWiV)\text{head}_i = \text{Attention}(QW_i^Q, KW_i^K, VW_i^V)
好处:
- 提升模型表示能力
- 各个头可以学到不同类型的关系(语法/语义)
✅ 总结一张表:
| 元素 | 含义 |
|---|---|
| Q(Query) | 查询者(当前词想问的问题) |
| K(Key) | 每个词的特征键(它能被问到什么) |
| V(Value) | 每个词携带的信息(最终输出) |
| Score | Q 和 K 的相似度,用来衡量关注程度 |
| Softmax | 转成概率分布 |
| Attention | 得到每个位置的加权值 |
📌 图示辅助(文字版)
输入序列 X: x₁ x₂ x₃ ...
↓ ↓ ↓
生成 Q、K、V: Q₁ Q₂ Q₃
K₁ K₂ K₃
V₁ V₂ V₃
Q₁·K₁ → 得分1
Q₁·K₂ → 得分2
Q₁·K₃ → 得分3
→ softmax → [α₁, α₂, α₃]
→ 输出 z₁ = α₁·V₁ + α₂·V₂ + α₃·V₃
🧪 PyTorch 代码示例
import torch
import torch.nn.functional as F
def scaled_dot_product_attention(Q, K, V):
d_k = Q.size(-1)
scores = torch.matmul(Q, K.transpose(-2, -1)) / d_k**0.5
weights = F.softmax(scores, dim=-1)
return torch.matmul(weights, V)
# 输入 (batch_size, seq_len, dim)
X = torch.randn(1, 5, 64)
W_Q = torch.nn.Linear(64, 64)
W_K = torch.nn.Linear(64, 64)
W_V = torch.nn.Linear(64, 64)
Q = W_Q(X)
K = W_K(X)
V = W_V(X)
output = scaled_dot_product_attention(Q, K, V)
print(output.shape) # torch.Size([1, 5, 64])
如果你想用图的方式直观理解注意力机制,我可以为你画一张图解释每一步。你想试试看吗?