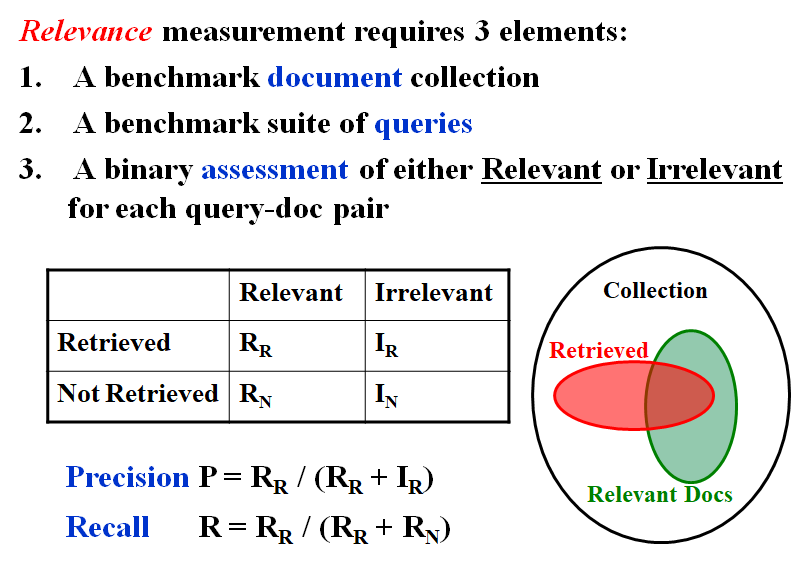
REVIEW 3 | Inverted File Index
看原笔记+PPT
智云已看
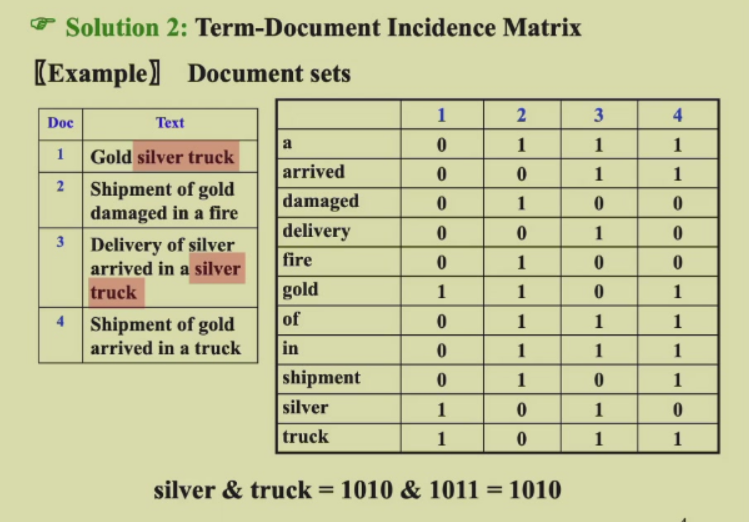
矩阵法
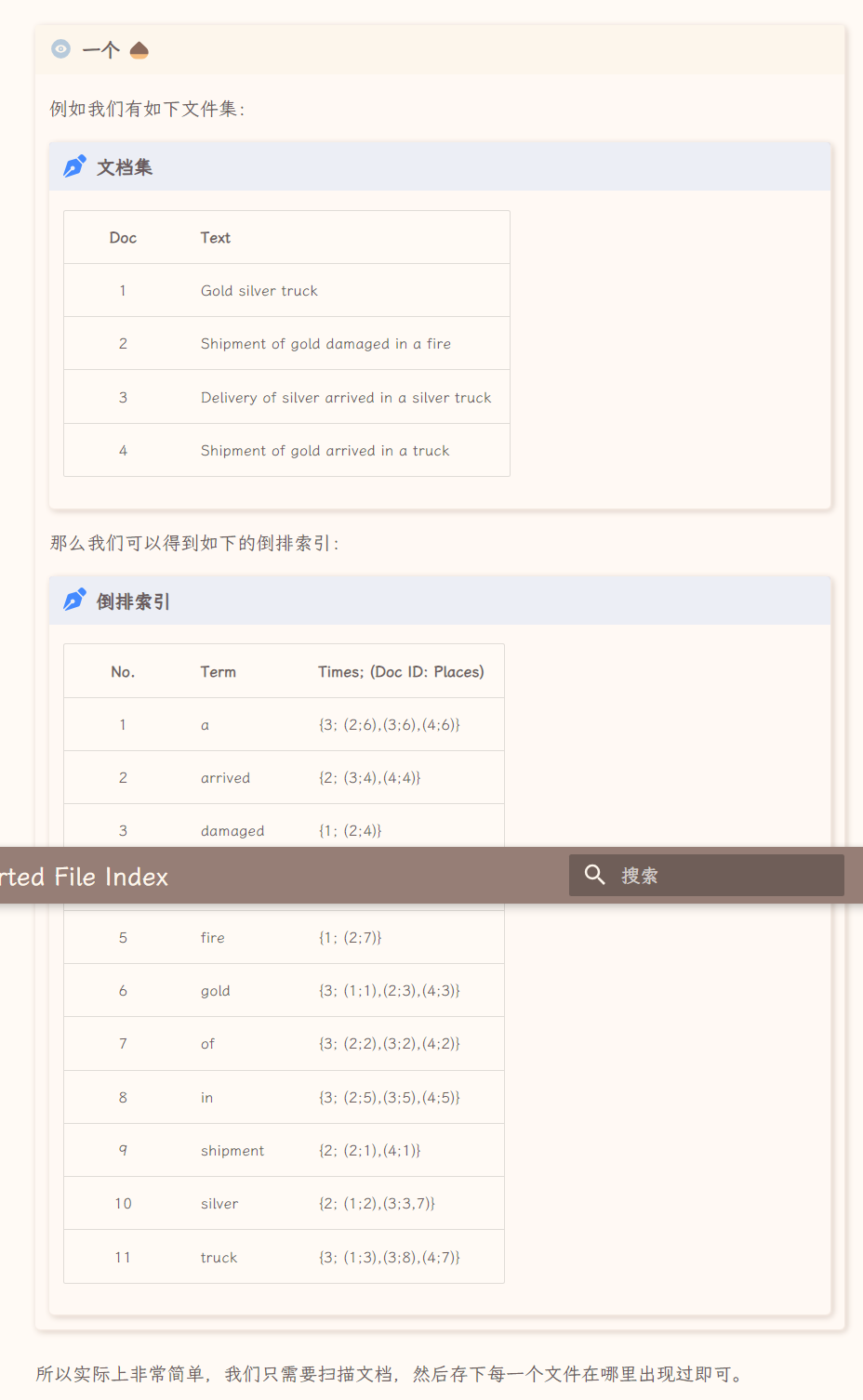
倒排索引
倒排索引(inverted file index)是一种常见的文本检索技术,用于快速查找包含特定单词或短语的文档。
它通过将单词或短语作为关键字,并将它们出现在文档中的位置记录在一个索引中,从而支持快速的文本检索。
在搜索过程中,系统可以快速地定位包含指定单词或短语的文档,并返回它们的相关信息。
所谓的倒排索引,所有的思想都凝结在了“倒”,也就是 inverted。
用“逆”更合适。
这里的索引对象指的是“文档”和“单词”之间的关系,而倒排索引的意思是,对于每一个单词,我们记录它出现在哪些文档中,以及记录他们出现的次数(频率)。
搜索引擎是一个非常常见的,倒排索引的应用案例,我们通过输入我们关注的词语,来索引包含这个词的所有文档。 当然,在这里我们考虑的是英文。
实现
我们可以用一个字典来描述一类关系,其主键为单词,键值为这个单词出现的所有位置。
最朴素的版本就是让键值为单词出现过的文档的序号序列。
如果我们还需要知道词汇出现的位置,则可以让键值是一个二元组的序列,其中第一个元素是文档的序号,第二个元素是单词在文档中出现的位置。
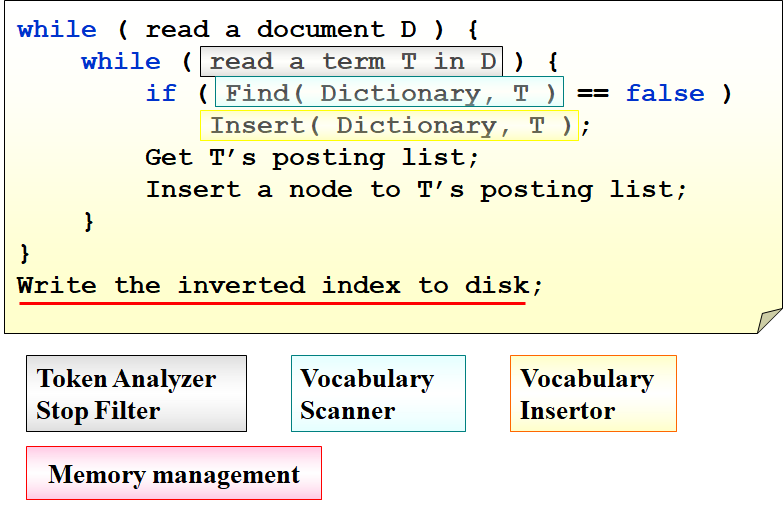
改进
倘若毫无节制的将所有词都存到倒排索引中,倒排索引就会变得非常大,其中必然有很多冗余信息存在。
停用词
有一些东西频繁地出现在所有文档中,在特定情况下,这些词可能并不会成为一个索引,例如正常的英文文章中的 a,the 等。
这一类词我们称之为停用词(stop words),不需要将他们存下。

词干分析
词干分析(word stemming)是一种将单词转换为其词干的技术。
例如,词干分析可以将单词 trouble,troubled,troubles,troubling 都转换为 trouble(甚至是 troubl,核心目的是让它们变成同一个单词)。
相同词干的词有着类似的含义,在检索 troubled 的时候,当然也可能想找到包含 trouble 的文档。
分布式
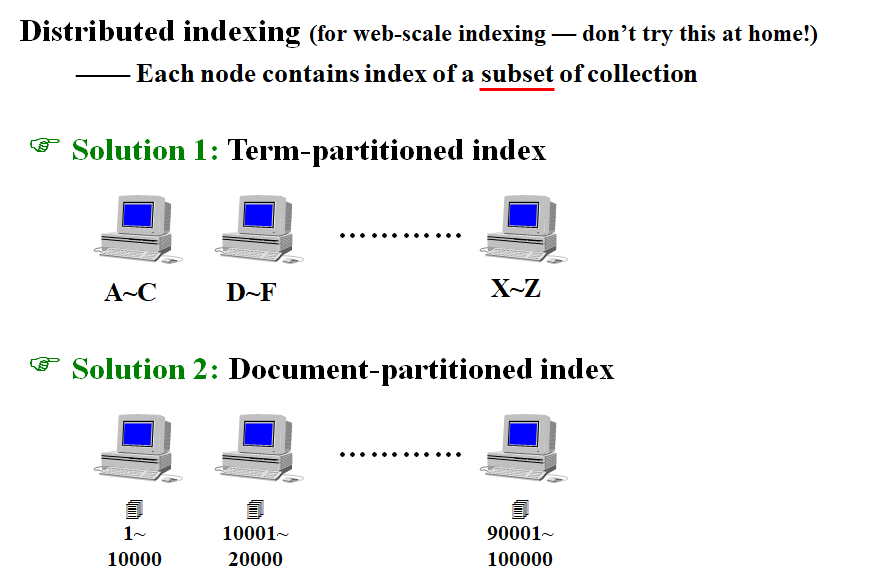
对于一个搜索引擎来说,它所需要索引的文料是非常庞大的,所以我们通常需要将其分布式地存储和索引。
有两种分布式的策略,其一是根据单词的字典序进行分布式,其二是根据文档进行分布式。
根据单词的内容进行分布式,能够提高索引效率,但是这样的话,我们就需要将所有形式接近的单词都存储在一个地方,这样就会造成单点故障,容灾能力很差,所以这种方式并不是很好。
第二种办法则有较强的容灾性能。即使一台机器无法工作,也不会剧烈影响到整个系统的工作。
dynamic index
main index库负责主要的检索,定时接受auxiliary index进行更新
auxiliary index负责接受爬虫的数据进行实时更新,当然也参与检索