Lecture 3 B+树和检索
:material-circle-edit-outline: 约 422 个字 :material-clock-time-two-outline: 预计阅读时间 1 分钟
B+树
定义
m阶B+数每个结点最多有m个子树,有m-1个数值
3阶B+数又称2-3树
4阶又称2-3-4树
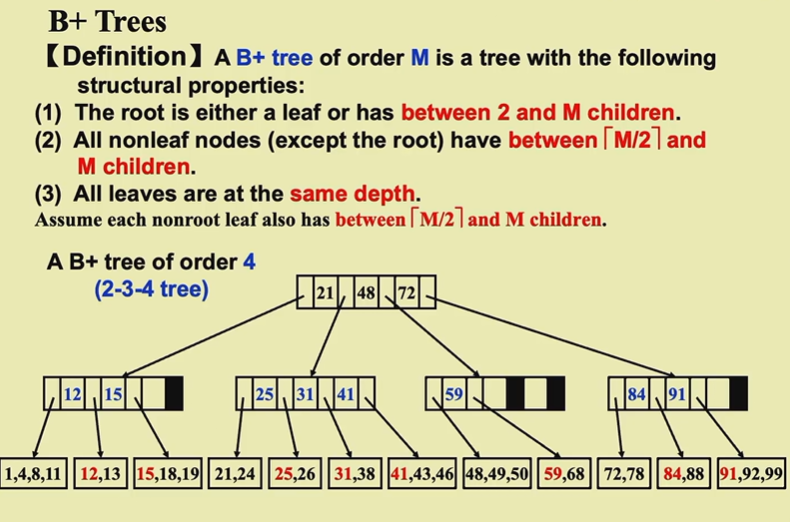

根节点性质比较特殊,子树数量下限是2,为什么(90min)
去看一下删除(90min)
Inverted File Index
学信息检索,做一个搜索引擎
矩阵法
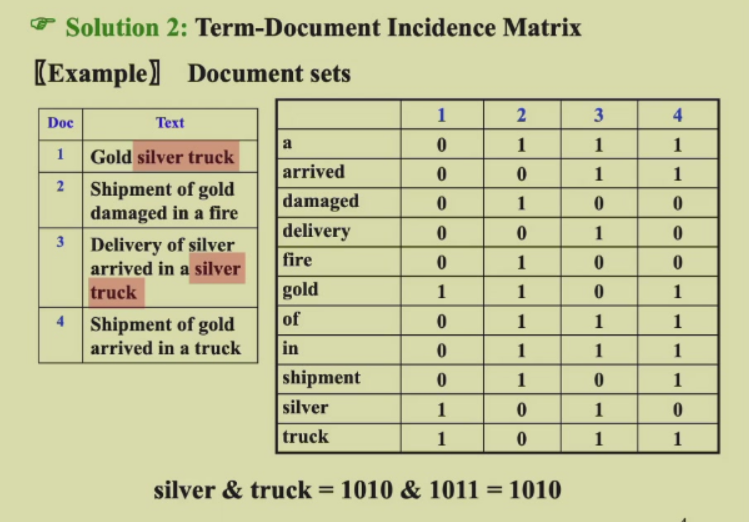
这个办法好用,但实际得到的矩阵太大了
然后可以将这个矩阵看成邻接矩阵,转化为图
现实中节点数和边数相似,故将图用邻接表表示更好
倒排表
这里没听见为什么是倒排

倒排表不仅记录在哪出现,还记录了度数/频率
记录度数是为了加快检索速度。当用户输入多个词的时候,先交度数少的就能减少交的运算量
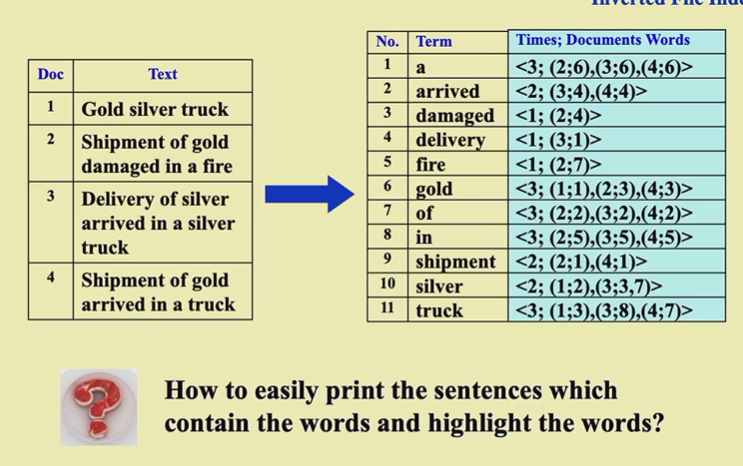
再记录词出现的位置
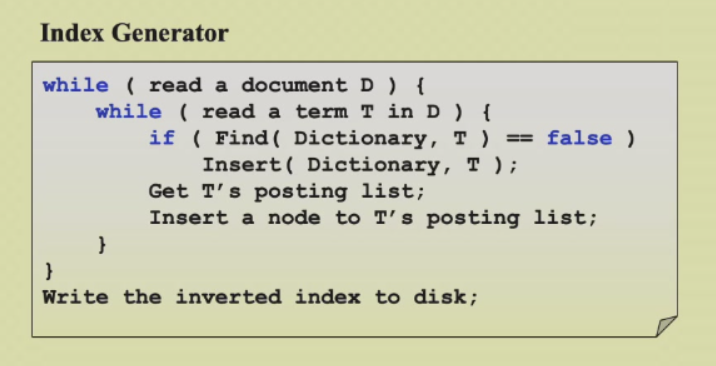
这里已经能写出一个搜索引擎框架了,但是想应用还有很多问题
下面给出一些解决策略
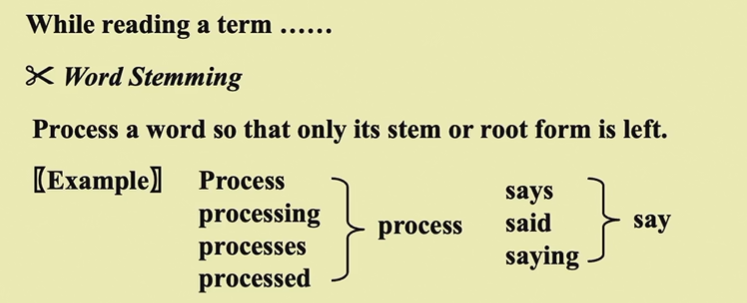

比如有些词每个文档都有,那就不要维护这个词了

字典树课后学一下,什么try树,hash函数
那个什么内存爆炸的地方重新听一下11:14
为了应对变化(网页更新等等),我们可以准备两个倒排表,一个稳定的主表,一个不断更新的小表,小表接受爬虫的折磨。检索时两个表都检索。
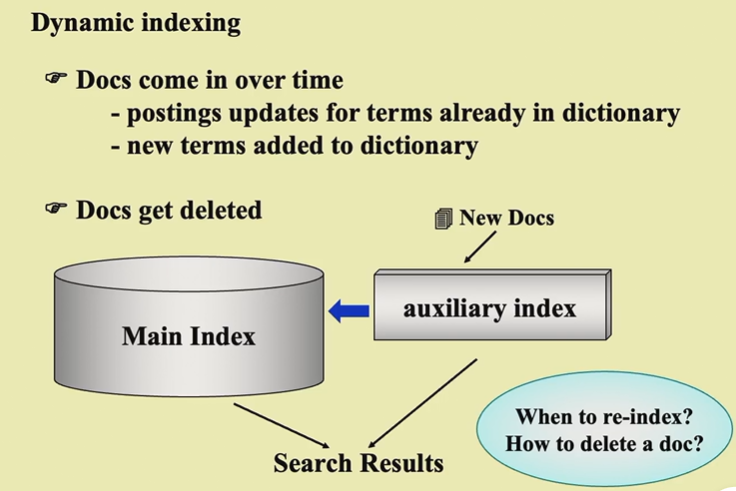
至于网站过时可以打一个mark,但不删除,检索时给最新的就好。

课后重新听,看钉钉群材料
第二节课后面没听