4.3
Hazards
冒险
Hazards 指的是阻止下一个指令在下一个时钟周期完成的一些情况。主要分为三种:
- Structure hazards
- 一个被请求的资源仍处于忙碌状态
- 一个组件不能被同时被两个指令同时利用
- Data hazards
- 需要等待上一个指令完成数据读写
- Control hazards
- 一些控制取决于上一条指令的结果
Structure hazards
比如,前一个指令在 ID 阶段的时候,会使用到其在 IF 阶段读出的指令的内容;但与此同时后一个指令已经运行到 IF 阶段并读出了新的指令,那么前一个指令就没的用了!
因此我们实际上会在每两个 stage 之间用一些寄存器保存这些内容:
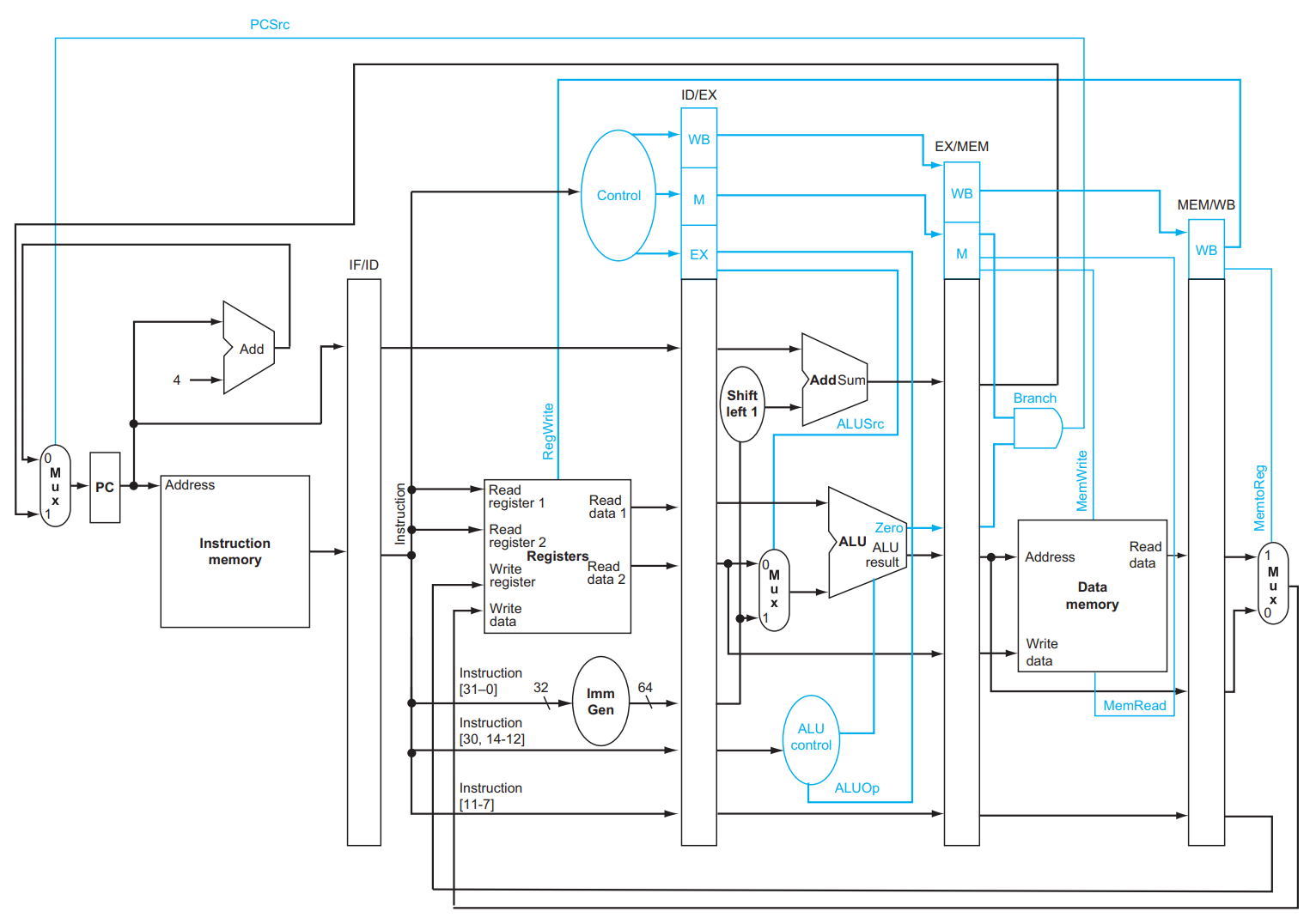
除了加了一些竖条条以外和之前没有流水线的时候几乎没什么差别。这些竖条条就是 pipeline registers,例如
IF/ID就是IF和ID阶段之间的一些寄存器。
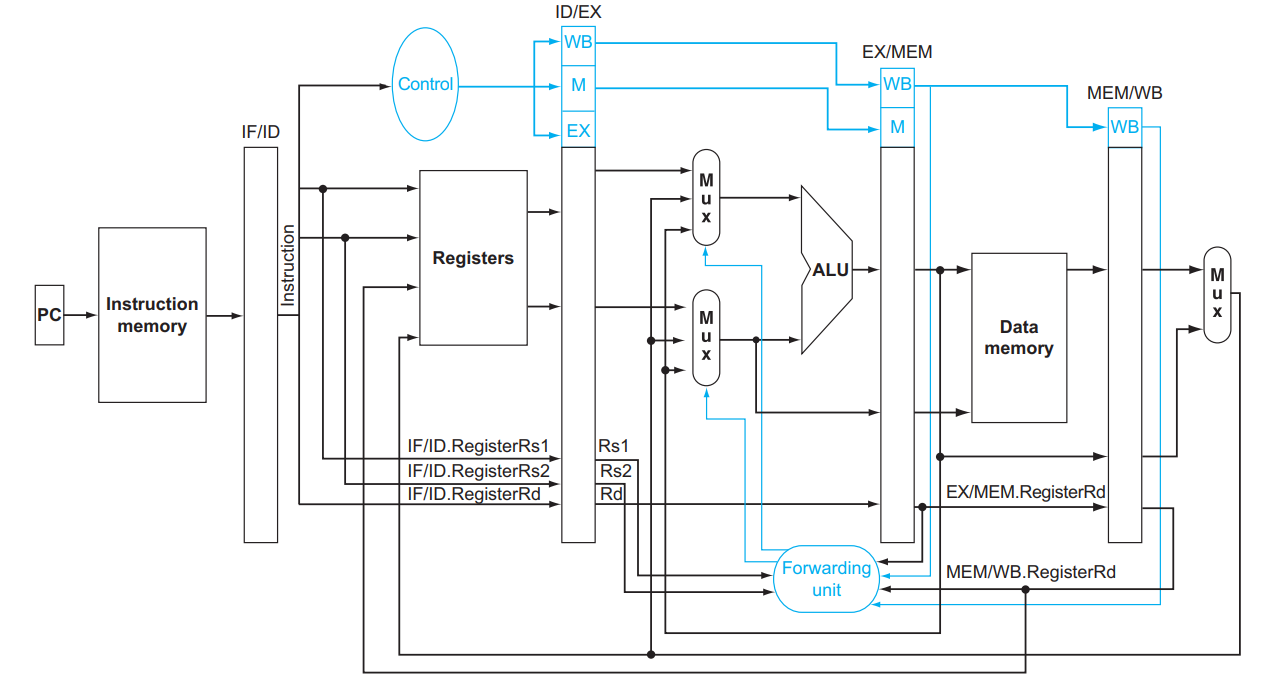
我们关注 datapath 中两个从右往左传东西的情况!一个是 WB 阶段写回数据,一个是 MEM 阶段判断是否发生跳转:
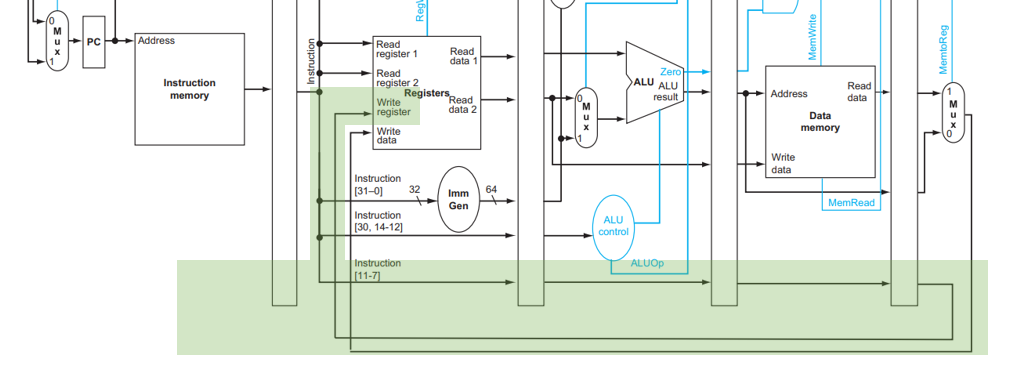
对于 WB 来说,我们写回时需要记录写到哪个 register 中,这个信息是 ID 阶段从 Instruction 中 [11:7] 的位置取出的,但是直到 WB 阶段才被用到,因此这个信息被存到了 ID/EX ,下一个周期存到了 EX/MEM ,下一个周期存到了 MEM/WB ,然后下一个周期被使用。
MEM 判断是否发生跳转的逻辑类似,略。
另外,由于在流水线中 IF 和 MEM 都有可能用到内存,为了不出现结构竞争,我们将数据和指令放在不同的地方,以避免同时出现要访问内存而导致的结构竞争。
这就是为什么会有独立的inst mem
以及独立的branch加法器
Data Hazards
就是下一条指令要用的数据上一条还没算出来
考虑下面的指令
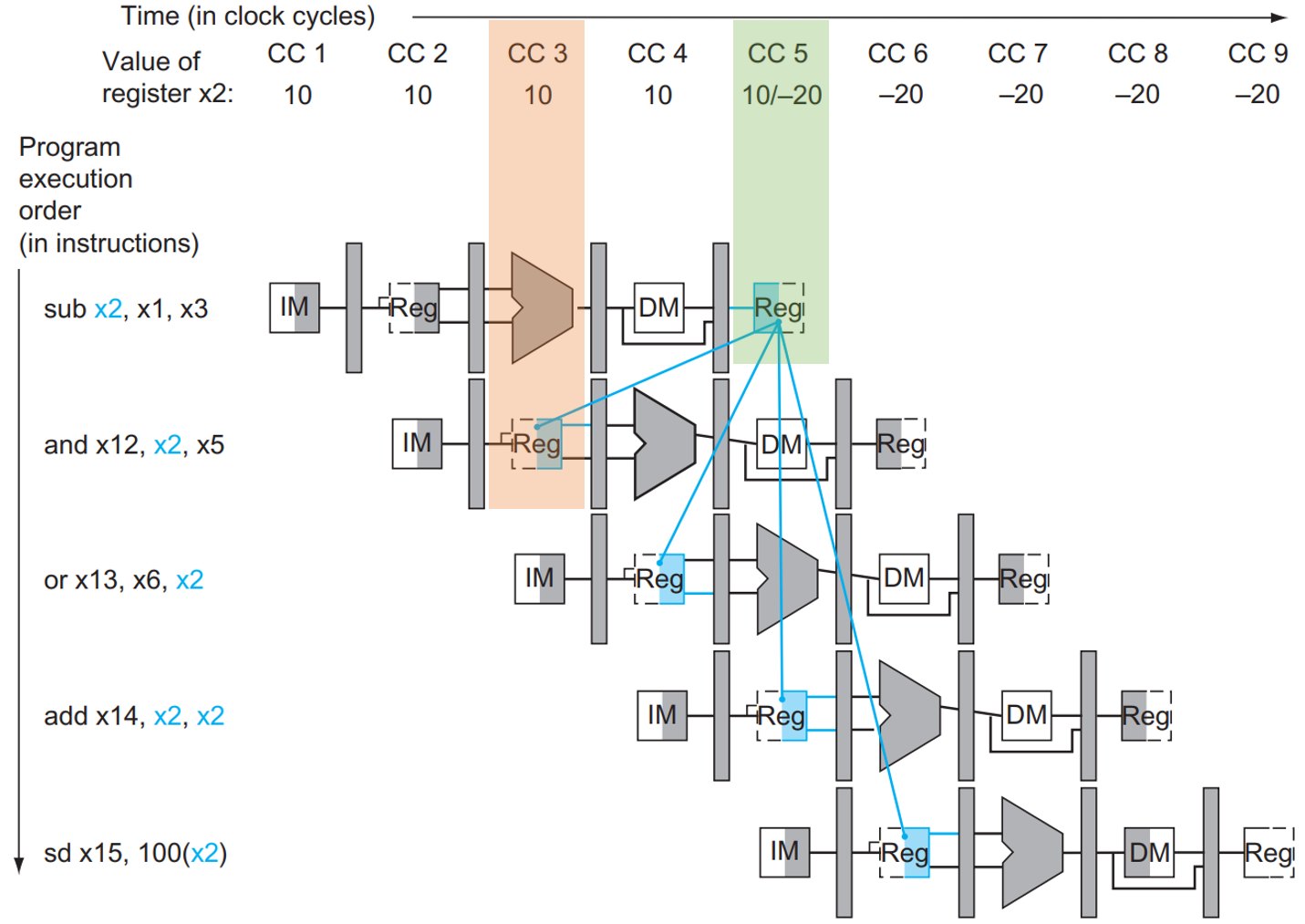
CC 代表 Clock Cycle
IM就是 inst mem,对应IFstage;Reg就是 reg file,对应IDstage;- 长得像 ALU 的就是 ALU,对应
EXstage;DM就是 data mem,对应MEMstage;- 最后面的
Reg也是 reg file,对应WBstage。
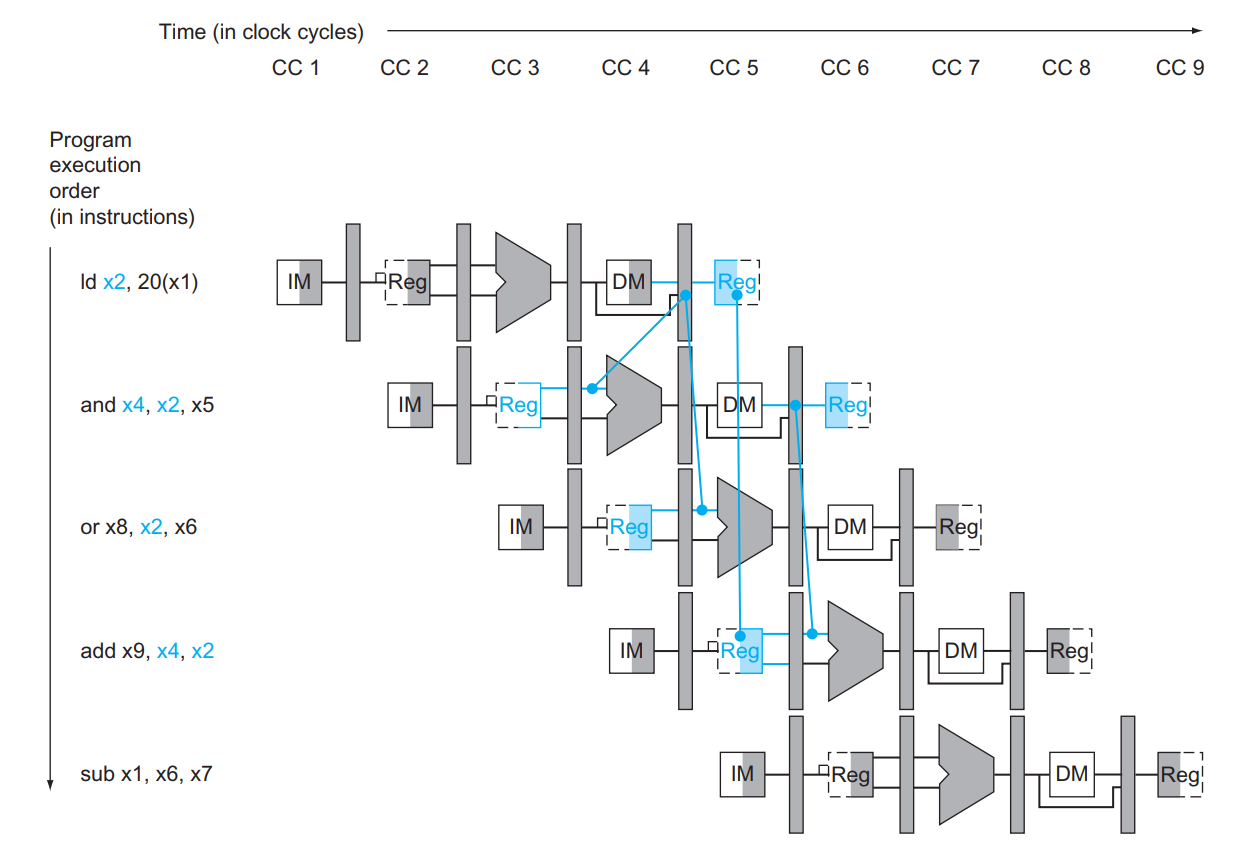
也就是说,由于指令所需的数据依赖于前面一条尚未完成的指令,因此指令不能在预期的时钟周期内执行,这种情况我们称之为 data hazard。
注意到,虽然 sub x2, x1, x3 在第 5 个时钟周期的 WB 阶段才将结果写回,但是在第 3 个时钟周期的 EX 阶段其实就算出来了!
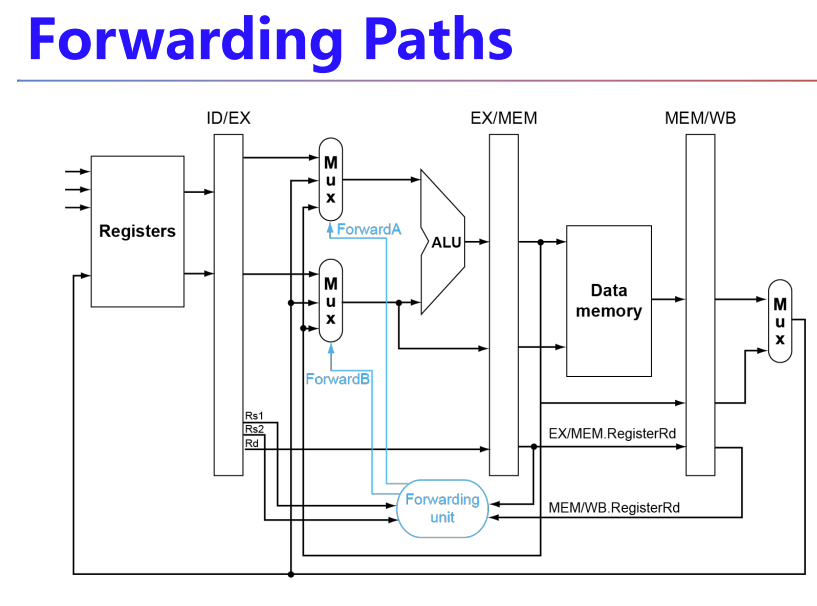
所以我们可以增加额外的硬件结构,使得 ALU 的输入不仅可以来源于寄存器或 ID/EX ,还可以来源于 EX/MEM 或 MEM/WB ,它们分别对应前一条和再前一条指令的 ALU 的计算结果。
这个解决方法叫 Forwarding (aka Bypassing):
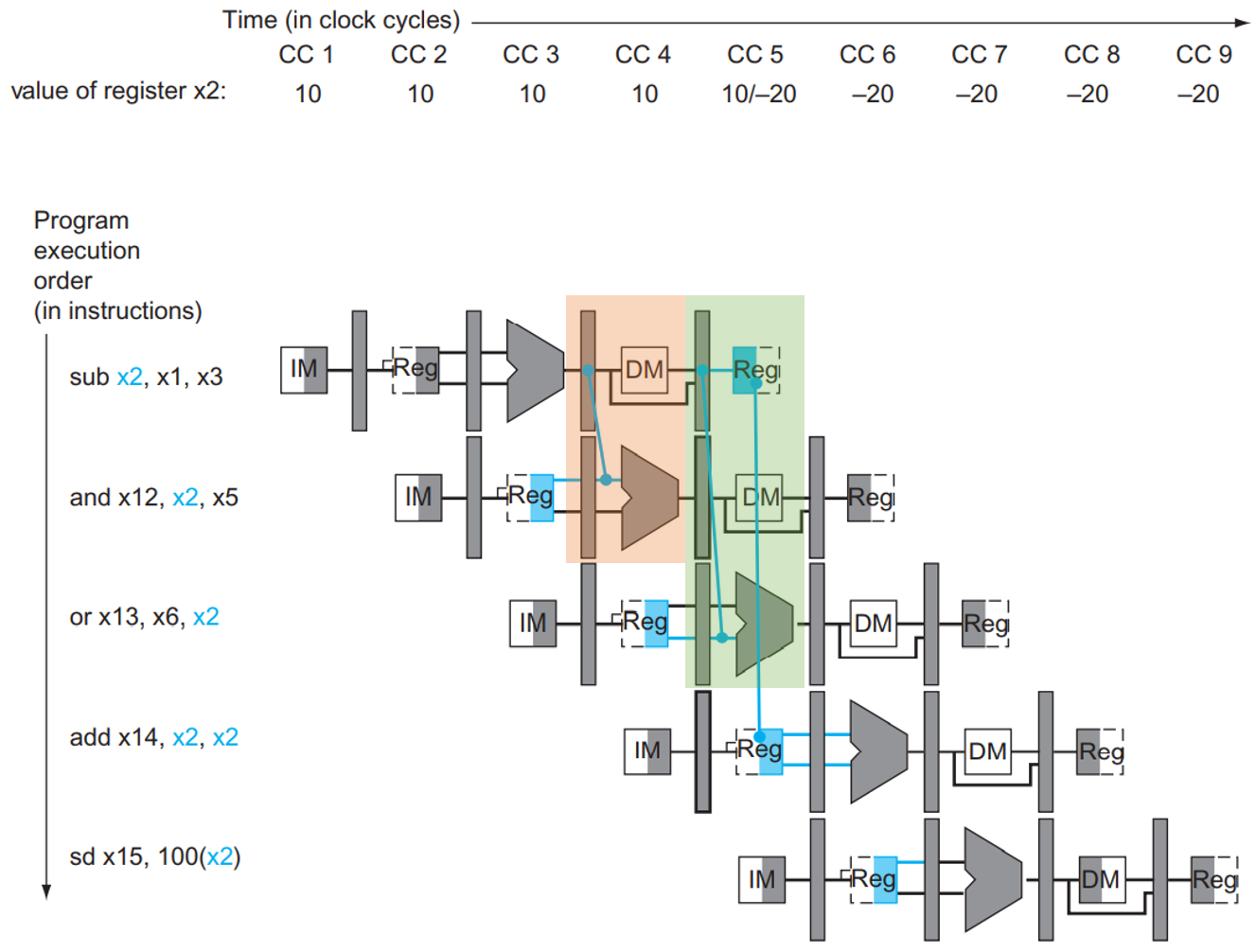
大意就是 X = 1, 2 = if (MEM.Rd != x0 && EX.RsX == MEM.Rd) ForwardX = 10; else if (WB.Rd != x0 && EX.RsX == WB.Rd) ForwardX = 01; else ForwardX = 00; :
但是遇到 load 指令不得不 stall,刚刚是因为 EX 和 ID 就差了一轮,但是 load 的数据要到 MEM 才有,所以如果下一条指令要用,上一条也拿不出来,只能要 stall 等才行:
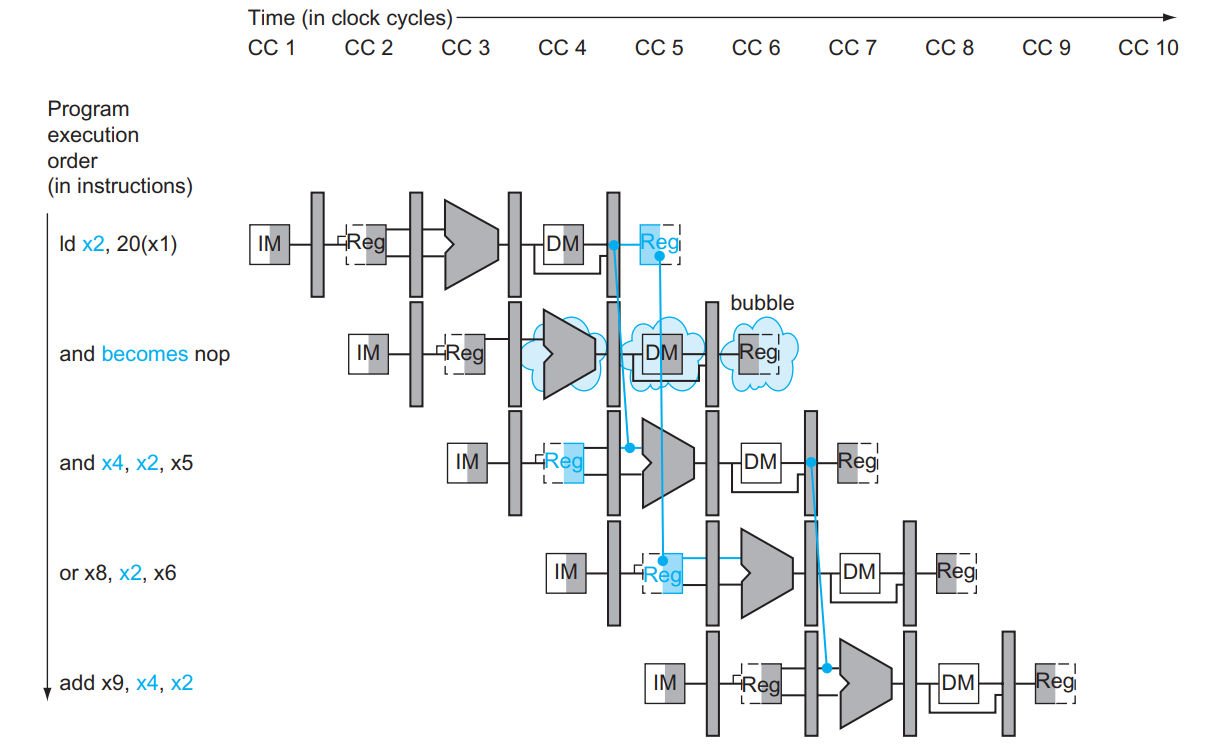
在 ID 阶段可以判定 hazard: if (EX.MemRead && EX.Rd == ID.RsX) Hazard();
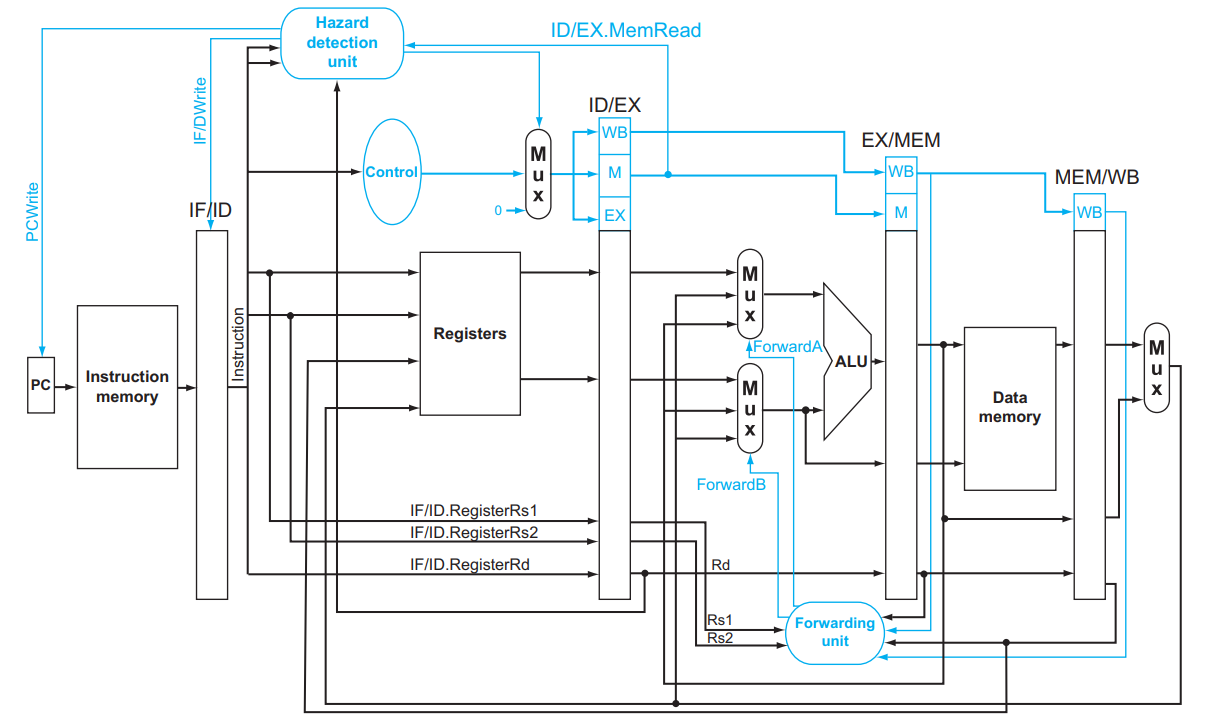
如何 stall 呢?两个任务:让当前指令不要产生效果 (清空 RegWrite 和 MemWrite )、让后面的语句不要受到影响 (保留 PC 和 IF/ID 一周期不改):

下面举例子
MEM hazard
必须掌握怎么写
not开始和下一句and这部分和外面一层基本一致
if (MEM/WB.RegWrite
and (MEM/WB.RegisterRd ≠ 0)
and not(EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs1))
and (MEM/WB.RegisterRd = ID/EX.RegisterRs1))
ForwardA = 01
if (MEM/WB.RegWrite
and (MEM/WB.RegisterRd ≠ 0)
and not(EX/MEM.RegWrite and (EX/MEM.RegisterRd ≠ 0)
and (EX/MEM.RegisterRd = ID/EX.RegisterRs2))
and (MEM/WB.RegisterRd = ID/EX.RegisterRs2))
ForwardB = 01
Load-Use Hazard Detection
load下一条指令就要用load的数据的情况
这是最常见的数据冒险,而且是硬件上无法解决的
Check when using instruction is decoded in ID stage
ALU operand register numbers in ID stage are given by IF/ID.RegisterRs1, IF/ID.RegisterRs2
ID/EX.MemRead
and(
(ID/EX.RegisterRd = IF/ID.RegisterRs1)
or
(ID/EX.RegisterRd = IF/ID.RegisterRs2)
)
If detected, stall and insert bubble

Load-Use Hazard必须停一个周期,操作是两部分呢
一个是ID/EX级控制信号全部清零,这样所有的Write信号就没了,避免误操作
具体实现方式是加一个mux,引入0信号
一个是下一周期需要运行原来的指令的,具体实现方式是锁住PC,避免变成PC+4
还有是把IF/ID给锁住,避免从inst mem读入
How to Stall the Pipeline
- Force control values in ID/EX register to 0, EX, MEM and WB do nop (no-operation)
- Prevent update of PC and IF/ID register
- Using instruction is decoded again
- Following instruction is fetched again
还有一种办法是对指令进行等价换序,让某些指令尽量晚一点执行,以避免数据竞争。这种方法叫 code scheduling。

考试会考,让你判断是否有hazard,哪里有hazard,怎么避免hazard
下面还有几张图,不太清楚什么意思


Double Data Hazard
Only fwd if EX hazard condition isn’t true
Control Hazards / Branch Hazards
比如,beq要等算完,到了mem级才能确认是否要跳转,才能确认下一条指令是跳转地址还是PC+4,但是这期间PC会继续读入PC+4,而且已经读入三条了,如果要跳转就完了,我们得保证读进来的三条指令不会完成写入操作,这样会损失三个指令
Fetching next instruction depends on branch outcome
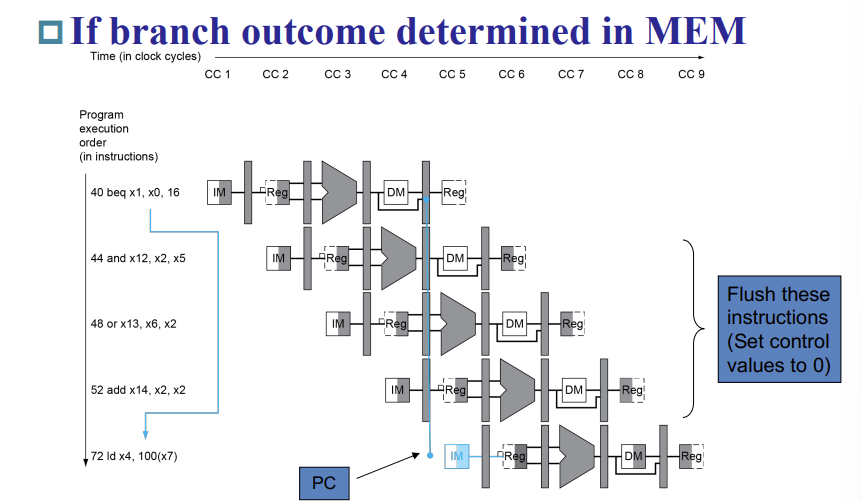
我们下面讲怎么减少损失
Ahead
branch就做了两件事,计算目标地址,判断是否要跳,我们就将这两件事提前:
36: sub x10, x4, x8
40: beq x1, x3, 32 // PC-relative branch
// to 40+32=72
44: and x12, x2, x5
48: orr x13, x2, x6
52: add x14, x4, x2
56: sub x15, x6, x7
...
72: ld x4, 50(x7)
因为branch计算目标地址本来就是用的额外的加法器而非ALU,所以我们就将这个adder移动到ID级即可,不能再往前了,ID级才知道这是什么指令
然后判断是否跳转,我们可以通过一些简单的电路实现(按位与、按位或啥的),就也前置到ID即,放在reg出口那
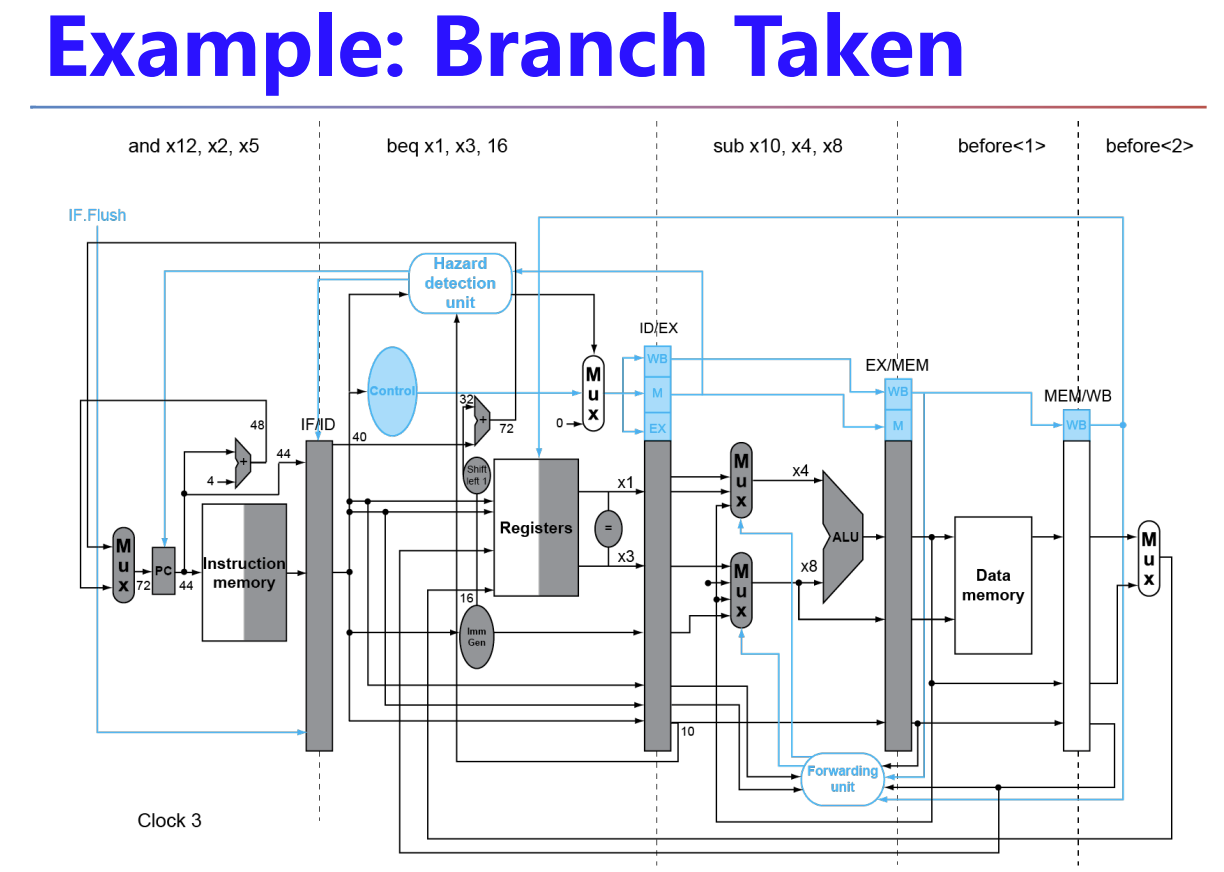
这样最多一次stall,具体操作时将下一级取的操作(IF级)清零
这里是预测错误的情况,预测正确就不要bubble了
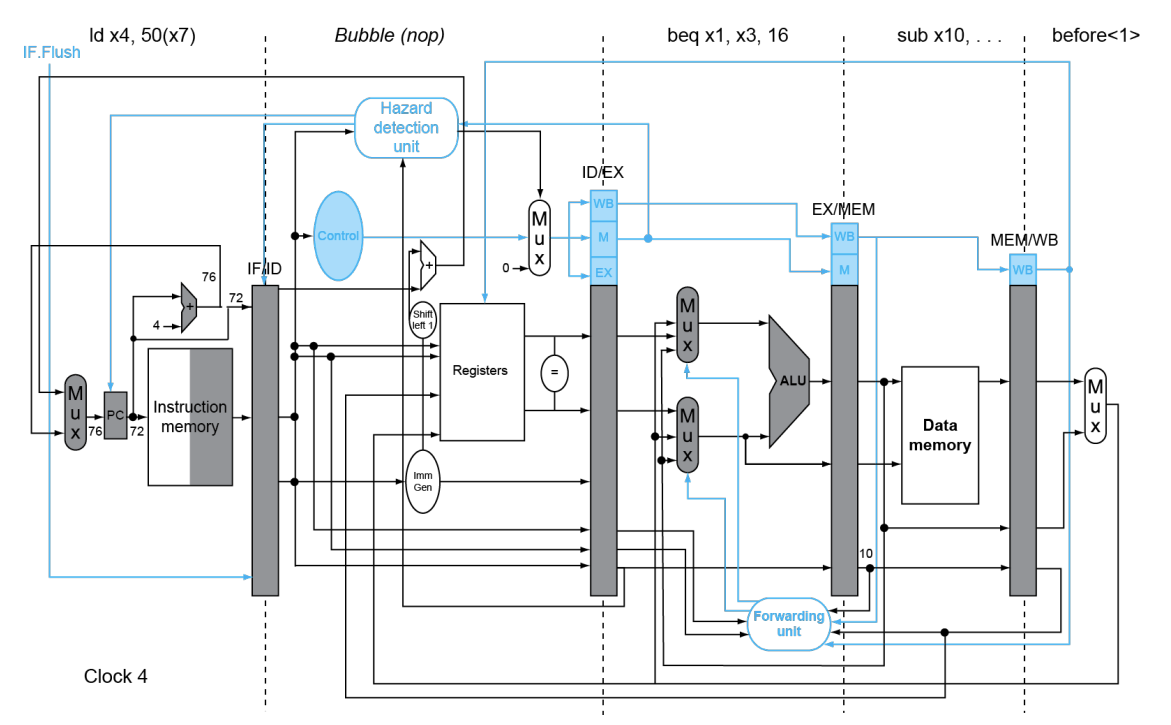
这种属于静态预测法,即规则是死的
Dynamic Branch Prediction
我们用一个buffer储存上一次branch
比如储存上一次branch情况,如果上一次跳了,这次branch也跳
这部分需要重新学一下计算机组成2024-04-23第6-8节 (zju.edu.cn)
-
Branch prediction buffer (aka branch history table)
-
Indexed by recent branch instruction addresses (lower part)
pc是64bit,太大了,我们只取低的几位
可能会低几位有正好重复的,导致准确率降低,但是同时减少了reg的s/l开销
- Stores outcome (taken/not taken)
To execute a branch
- Check table, expect the same outcome
- Start fetching from fall-through or target
- If wrong, flush pipeline and flip prediction
Branch prediction buffer
注意下面buffer记录的是某个特定branch的状态,一般用PC或PC尾数标记
1-Bit Predictor
1-Bit Predictor 就只记上一次是否有branch,上一次跳了这次也跳
对于loop挺有用的,但是刚调用的时候以及跳出去的时候会分别出错一次
2-Bit Predictor
分为了4分态,连续两次没错进入深层状态,连错两次才改变决策,
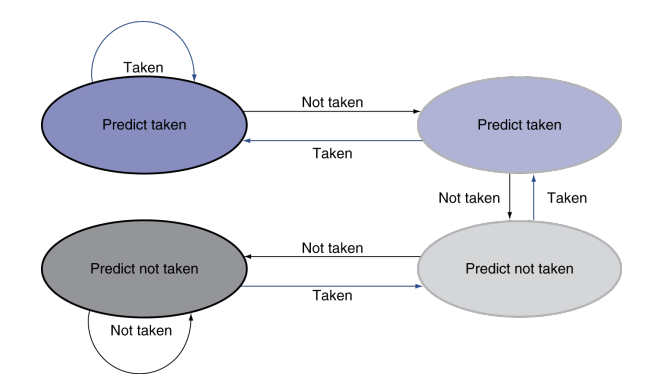
Branch target buffer
Branch prediction buffer 存的是跳转行为,决定是否要跳转
这个直接存的上一级要去的的pc地址,predict对了直接用