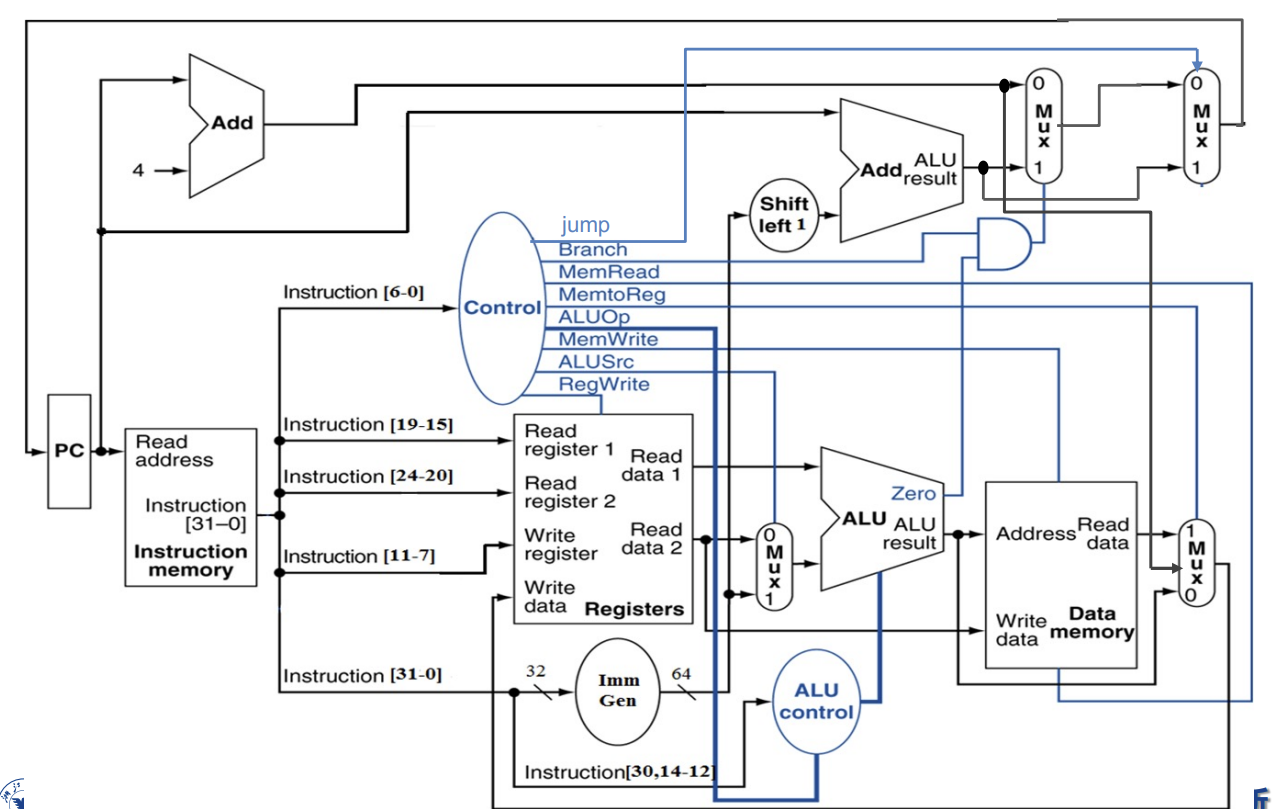
mid
塞满了考前查漏补缺出来的内容,都是没整理的,留着考完整合进REVIEW
布斯乘法算法
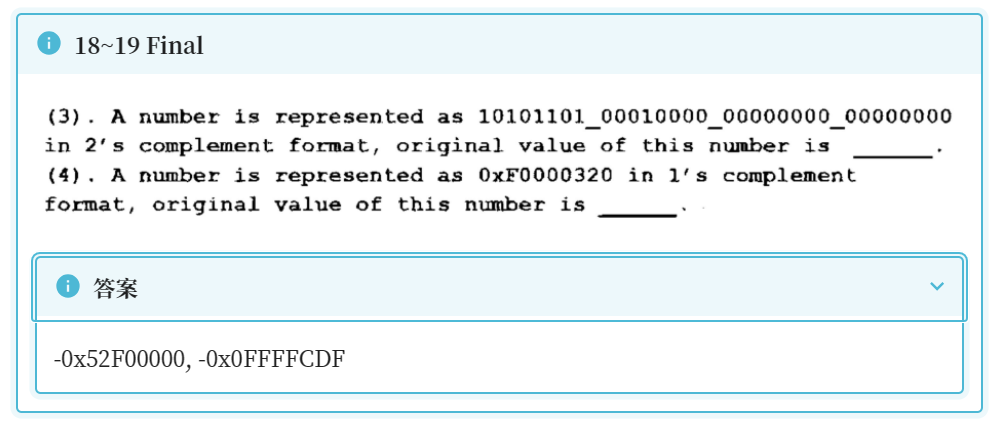
布斯乘法算法 - 维基百科,自由的百科全书 (wikipedia.org)
算法描述 对于N位乘数Y,布斯算法检查其2的补码形式的最后一位和一个隐含的低位,命名为y-1,初始值为0。对于yi, i = 0, 1, ..., N - 1,考察yi和yi - 1。当这两位相同时,存放积的累加器P的值保持不变。当yi = 0且yi - 1 = 1时,被乘数乘以2i加到P中。当yi = 1且yi - 1 = 0时,从P中减去被乘数乘以2i的值。算法结束后,P中的数即为乘法结果。
该算法对被乘数和积这两个数的表达方式并没有作规定。一般地,和乘数一样,可以采用2的补码方式表达。也可以采用其他计数形式,只要支持加减法就行。这个算法从乘数的最低位执行到最高位,从i = 0开始,接下来和2i的乘法被累加器P的算术右移所取代。较低位可以被移出,加减法可以只在P的前N位上进行。
浮点乘法将两个 Exponent 相加并 减去一个 bias,因为 bias 加了 2 次
- 将两个 (1 + Fraction) 相乘,并将其规格化;此时同样要考虑 overflow 和 underflow;然后舍入,如果还需要规格化则重复执行

https://www.h-schmidt.net/FloatConverter/IEEE754.html
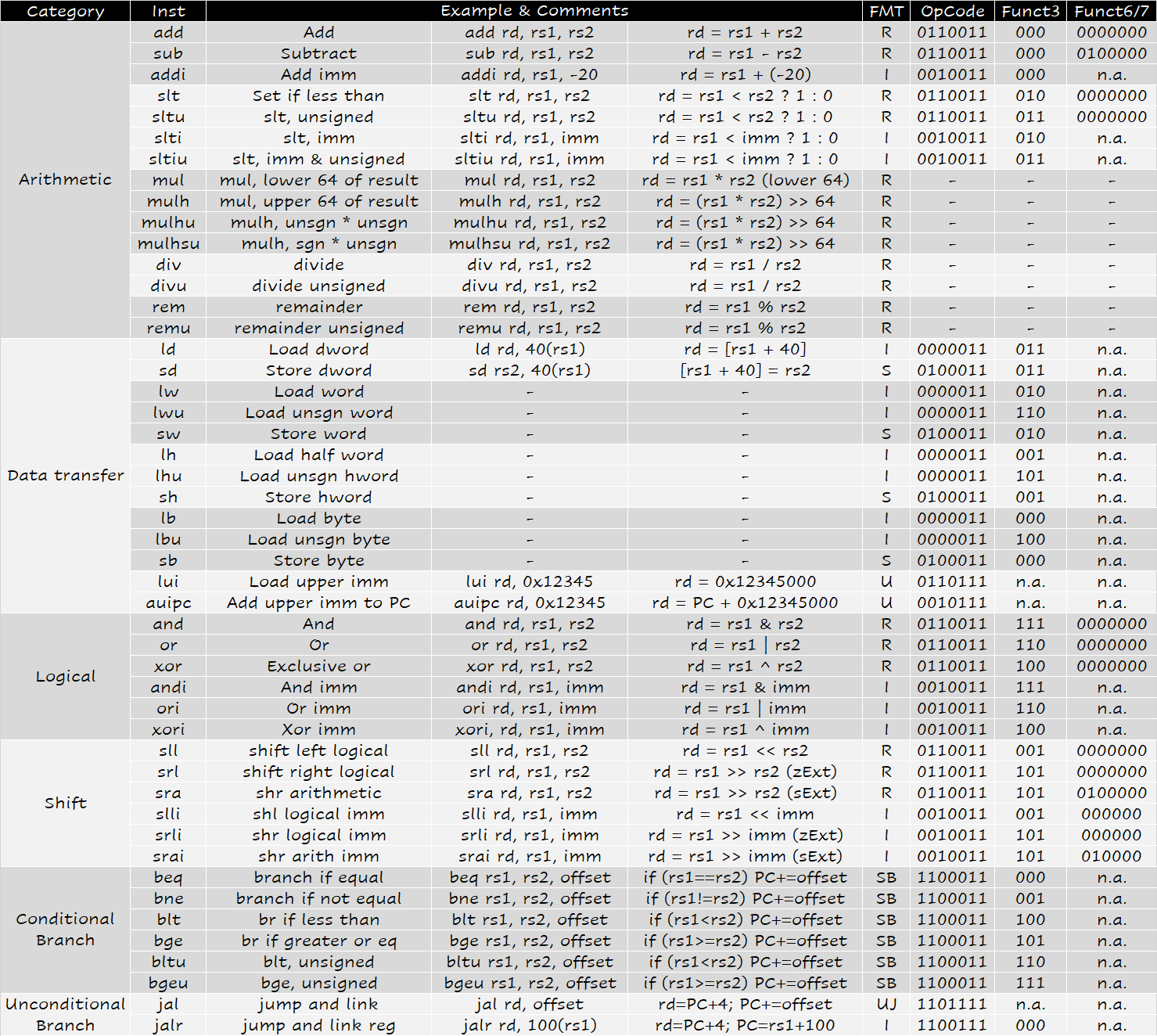
RISC-V 约定:
x5-x7以及x28-x31是 temp reg,如果需要的话 caller 保存;也就是说,不保证在经过过程调用之后这些寄存器的值不变。
x8-x9和x18-x27是 saved reg,callee 需要保证调用前后这些寄存器的值不变;也就是说,如果 callee 要用到这些寄存器,必须保存一份,返回前恢复。
x10-x17是 8 个参数寄存器,函数调用的前 8 个参数会放在这些寄存器中;如果参数超过 8 个的话就需要放到栈上(放在fp上方,fp + 8是第 9 个参数,fp + 16的第 10 个,以此类推)。同时,过程的结果也会放到这些寄存器中(当然,对于 C 语言这种只能有一个返回值的语言,可能只会用到x10)。
x1用来保存返回地址,所以也叫ra。因此,伪指令ret其实就是jalr x0, 0(x1)。
-
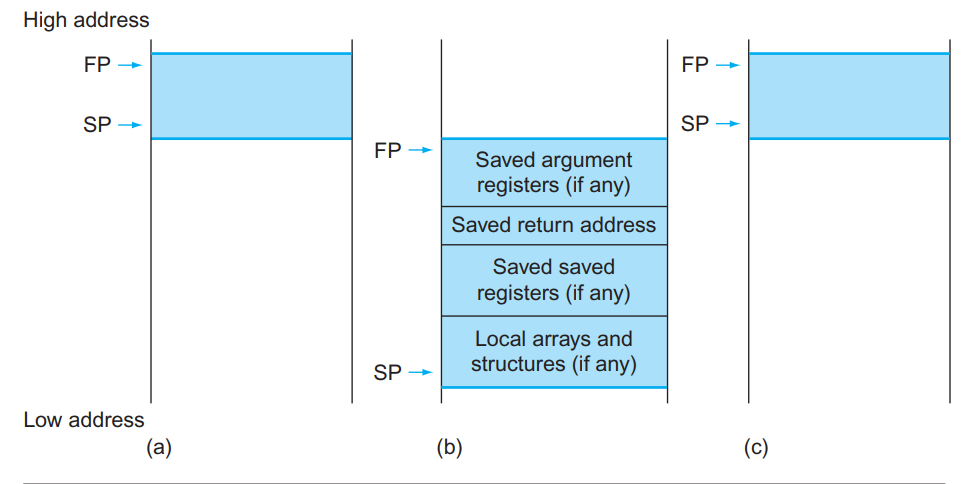
栈指针是
,也叫
;始终指向
栈顶元素
。栈从高地址向低地址增长。
addi sp, sp, -24,sd x5, 16(sp),sd x6, 8(sp),sd x20, 0(sp)可以实现将 x5, x6, x20 压栈。
- 一些 RISC-V 编译器保留寄存器
x3用来指向静态变量区,称为 global pointergp。
-
一些 RISC-V 编译器使用
指向 activation record 的第一个 dword,方便访问局部变量;因此
也称为 frame pointer
。在进入函数时,用
将
初始化。
fp的方便性在于在整个过程中对局部变量的所有引用相对于fp的偏移都是固定的,但是对sp不一定。当然,如果过程中没有什么栈的变化或者根本没有局部变量,那就没有必要用fp了。
至此,我们将所有寄存器及其用途总结如下:
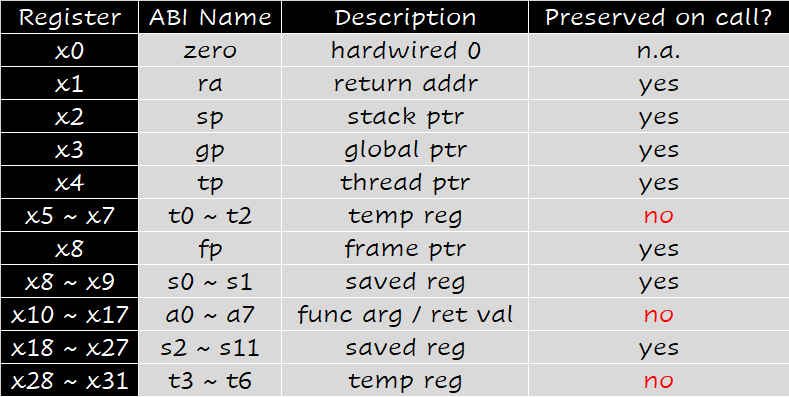 其中 "preserved on call" 的意思是,是否保证调用前后这些寄存器的值不变。
其中 "preserved on call" 的意思是,是否保证调用前后这些寄存器的值不变。
1.1 Eight Great Ideas¶
部分在实际题目中还挺难区分的,注意识别题目中的关键暗示。此外,先学习了之后的内容会对部分思想有更深刻的理解。
- Design for Moore’s Law (设计紧跟摩尔定律)
- Moore's Law: Integrated circuit resources double every 18-24 months.
- Design for where it will be when finishes rather than design for where it starts.
- Use Abstraction to Simplify Design (采用抽象简化设计)
- 层次化、模块化的设计
- Make the Common Case Fast (加速大概率事件)
- Performance via Parallelism (通过并行提高性能)
- Performance via Pipelining (通过流水线提高性能)
- 换句话说就是,每个流程同时进行,只不过每一个流程工作的对象是时间上相邻的若干产品;
- 相比于等一个产品完全生产完再开始下一个产品的生产,会快很多;
- 希望每一个流程的时间是相对均匀的;
- Performance via Prediction (通过预测提高性能)
- 例如先当作
if()条件成立,执行完内部内容,如果后来发现确实成立,那么直接 apply,否则就再重新正常做; - 这么做就好在(又或者说只有这种情况适合预测),预测成功了就加速了,预测失败了纠正的成本也不高;
- 例如先当作
- Hierarchy of Memories (存储器层次)
- Disk / Tape -> Main Memory(DRAM) -> L2-Cache(SRAM) -> L1-Cache(On-Chip) -> Registers
- Dependability via Redundancy (通过冗余提高可靠性)
- 类似于卡车的多个轮胎,一个模块 down 了以后不会剧烈影响整个系统;


1,2,5,6,8,9,10,11,12,13,14

RISCV寻址模式详解
RISCV寻址模式用于计算操作数的有效地址,即操作数在内存中的实际位置。RISCV支持五种主要的寻址模式:
- 直接寻址(Direct Addressing):操作数的有效地址是指定寄存器中的值。这种寻址模式通常用于访问寄存器中的数据。
示例:
代码段
该指令将寄存器x1中的值加到寄存器x0中的值,并将结果存入寄存器x10。操作数(寄存器x1中的值)的有效地址就是寄存器x1中的值。
- 立即数寻址(Immediate Addressing):操作数的有效地址是指令中编码的12位立即值。这种寻址模式通常用于加载小常量或偏移量。
示例:
代码段
该指令将立即值10加载到寄存器x10中。操作数(立即值10)的有效地址就是立即值10本身。
- 寄存器寻址(Register Addressing):与直接寻址类似,但它使用寄存器来指定操作数的基地址而不是有效地址本身。这种寻址模式通常用于访问存储在已知寄存器固定偏移处的数据。
示例:
代码段
该指令从寄存器x0指向的地址偏移4字节处加载数据并将其存入寄存器x10。操作数的有效地址是通过将偏移量4添加到寄存器x0中的值来计算的。
- 基地址寻址(Base Address Addressing):与寄存器寻址类似,但它允许更灵活地指定操作数的基地址。这种寻址模式通常用于访问存储在已知寄存器可变偏移处的数据。
示例:
代码段
该指令从寄存器x0指向的地址加上寄存器x1中的值偏移0字节处加载数据并将其存入寄存器x10。操作数的有效地址是通过将寄存器x1中的值添加到寄存器x0中的值来计算的。
- PC相对寻址(PC-Relative Addressing):使用程序计数器(PC)作为操作数的基地址。这种寻址模式通常用于分支和跳转,因为它允许指令引用相对于自身在指令流中的位置的内存位置。
示例:
代码段
该指令无条件跳转到地址0x100。操作数的有效地址是通过将偏移量0x100添加到PC的值来计算的。
选择合适的寻址模式
寻址模式的选择取决于具体的指令和要访问的数据。总的来说,直接寻址和立即数寻址对于访问已经存在于寄存器中的数据或加载小常量是最有效的。寄存器寻址和基地址寻址对于访问存储在已知寄存器固定或可变偏移处的数据更灵活。PC相对寻址通常用于分支和跳转。
希望以上解释能够帮助您理解RISCV中的寻址模式。如果您还有其他问题,请告诉我。
算数左移、逻辑右移、算数右移、逻辑右移_逻辑右移会溢出吗-CSDN博客