Lecture 11 | Memory Hierarchy - Cache basics
计算机组成2024-05-07第6-8节 (zju.edu.cn)
5.3 The basics of Cache
第四章的inst mem和data mem实际上就是兩個独立的cache
每一个下层的数据只会唯一地出现在cache里面,即相同的数据不会重复占用cache地址
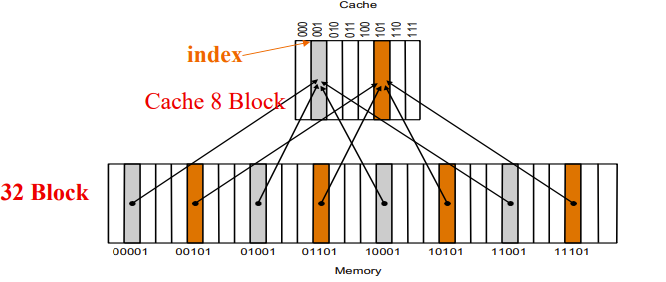
如下图所示,数据在cache是乱放的,所以我们要看下怎么寻址比较好

Direct Mapped Cache
直接映射
Direct-mapping algorithm:(Block address) modulo (Number of blocks in the cache)
就是取 block addr 的低 \(n\) 位作为 cache 内的地址,一样的在一起
\(n\) 取决于cache有 \(2^n\) 个index
至于怎么区分cache一个block里面的blocks,我们可以通过剩下高处的位作为判断,这些剩下的高处的地址位叫做 \(tag\)
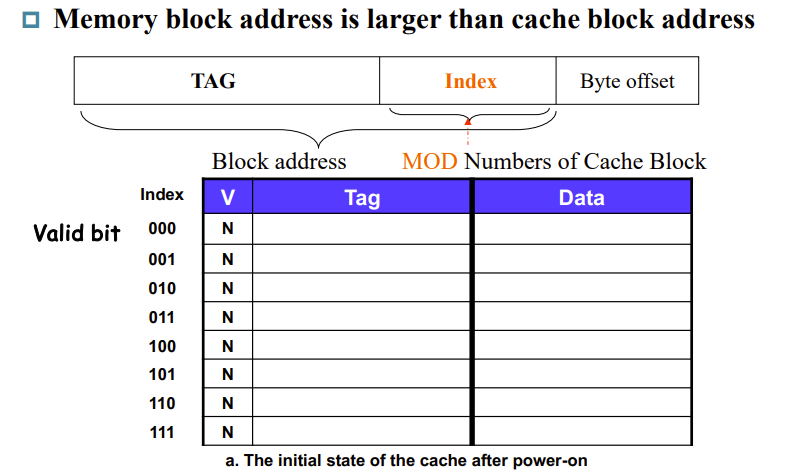
但是有些mem的block可能没有data,我们需要标记一下,于是有了所谓的 valid bits,其值为1表示present,0表示 no present,初始化为0
下图是Direct Mapped Cache的完整示意图
V是valid bits,index是低 \(n\) 位,byte offset取决于一个block有多少byte
block addr = tag+index+byte offset
下面举个例子
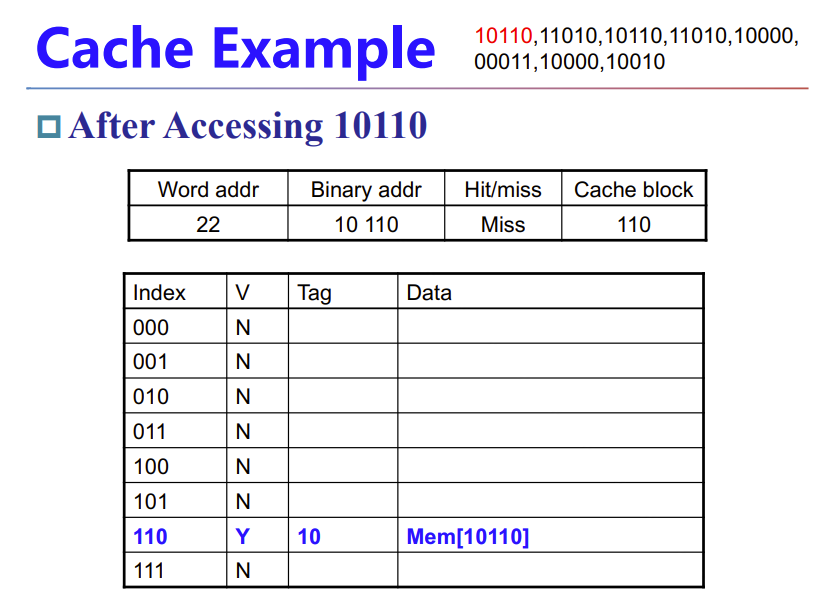
cache没有就miss了,需要从mem中读进来
如果重复访问就能hit了
如果index一样但tag不一样,依旧会miss,然后覆盖相应index的tag和data
下面举个例子,看下tag bits和cache size怎么计算
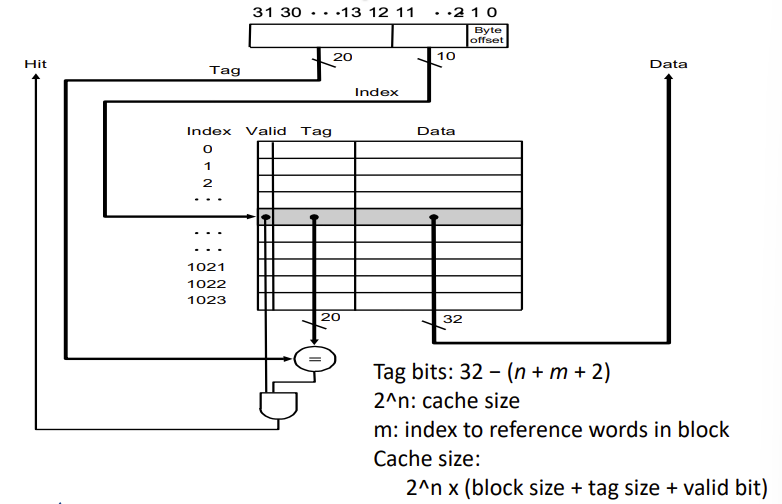
n就是index占的位数
\(2^m\) 是一个block有多少个word,2是byte的地址寻址位数
m+2占的位用于在cache的data里面找到需要的byte,m用于找到block里面的word,2用于找到word里面的byte(一个word有4个byte,只需要两bit寻址)
这个2就是刚刚提到的byte offset
注意,这里的index,m,n,tag,都是CPU提供的物理地址如何被cache解码用到的概念

下面给个计算cache大小的例子
注意KB的B是byte,不是bit

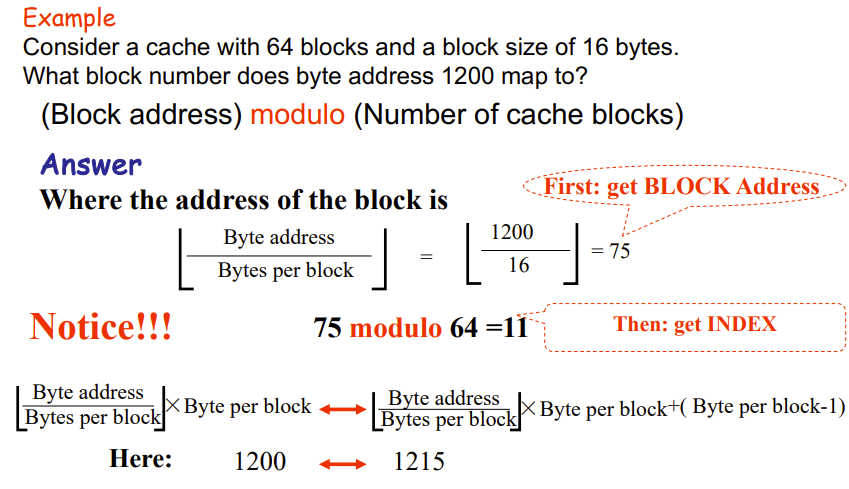
上面这题答案是11,就是让你算index
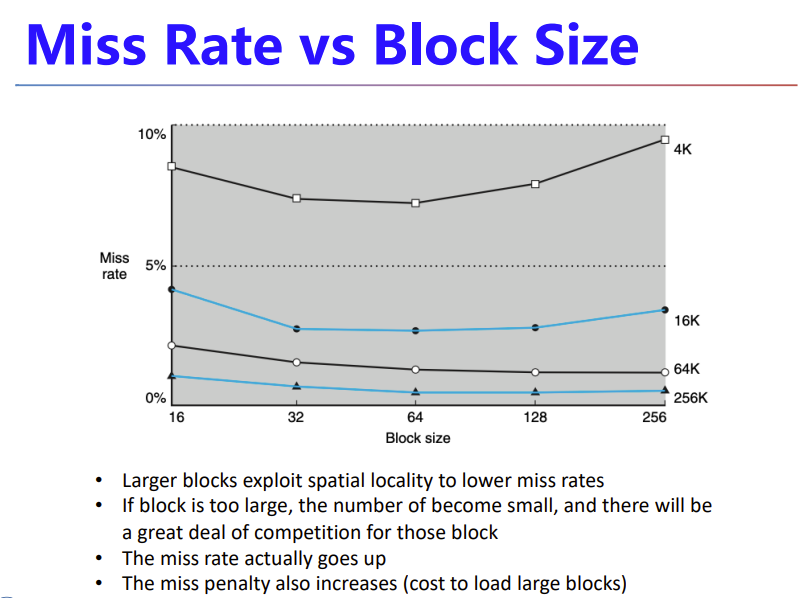
Handling Cache hit and Misses
Read misses—two kinds of misses
- instruction cache miss
- 遇到时processor会将PC-4这个地址交给mem,将相应的inst重新读入inst cache,再重新操作
- data cache miss
Write hits
Different Strategies
- write-back: Cause Inconsistent
- 只更新cache,不更新mem
- 很快,但会导致不一致,但是可以多次写出在一起写入mem,减少mem操作
- write-through: Ensuring Consistency
- 写入cache和mem,但是比较慢
Write misses
就是发现cache里面没读入这个要写的block
read the entire block into the cache, then write the word
Four Questions for Memory Designers
这部分会详细讲cache怎么实现
- 下层数据该映射到上层的什么位置(Block placement)
- 怎么确认下层数据已经在上层(Block identification)
- miss的时候怎么办(Block replacement)
- 写该如何实现(Write strategy)
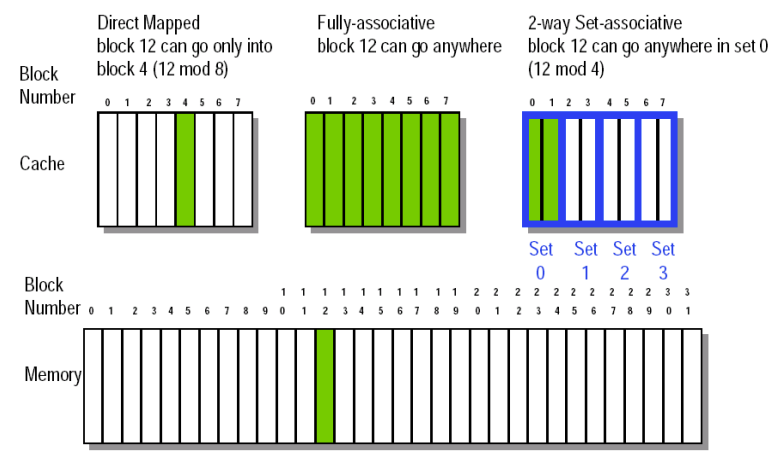
Q1: Block Placement
- Direct mapped
- Block can only go in one place in the cache
- Fully associative
- Block can go anywhere in cache.
- Set associative
- Block can go in one of a set of places in the cache.
- A set is a group of blocks in the cache.
- fully associative is m-way set-associative (for a cache with m blocks)
- Note that direct mapped is the same as 1-way set associative
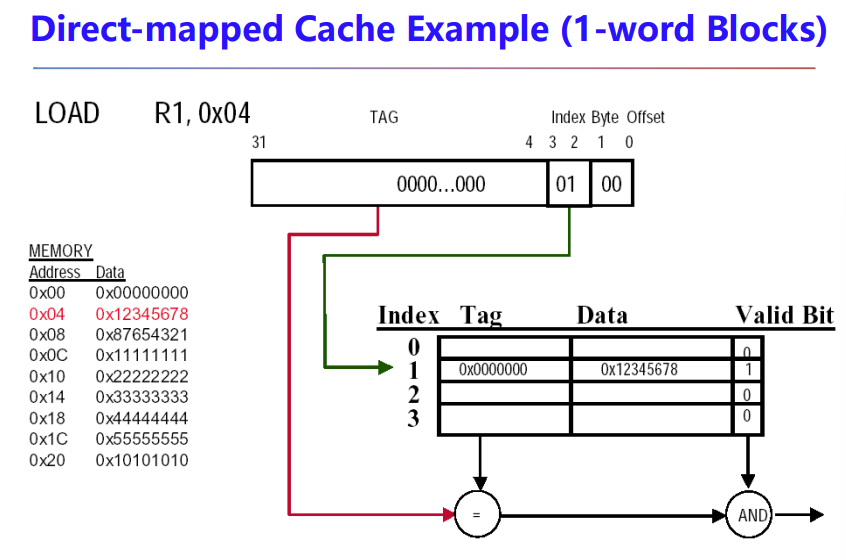
Q2: Block Identification
- Tag
- Valid bit
The Format of the Physical Address
- index
- The set, in case of a set-associative cache
- The block, in case of a direct-mapped cache
- Has as many bits as log2(#sets) for set-associative caches, or log2(#blocks) for direct-mapped caches
- The Byte Offset field selects
- The Tag

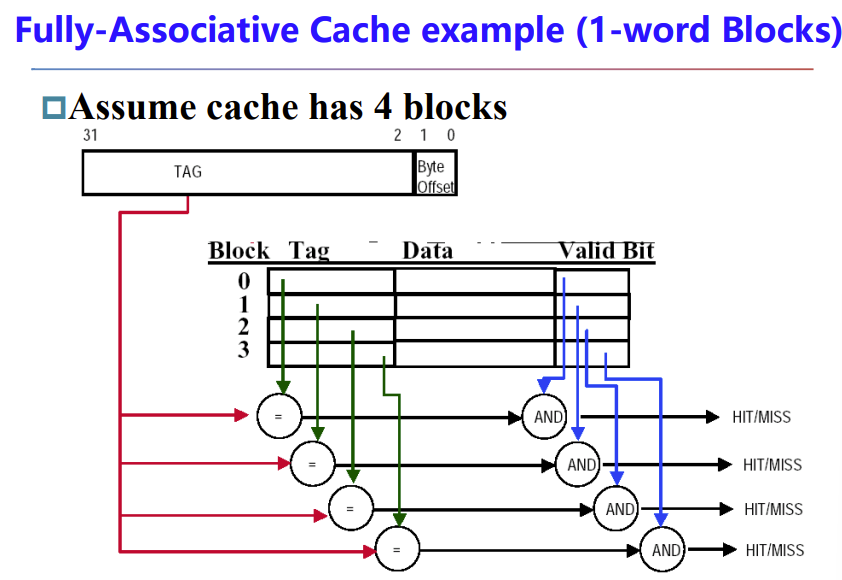
采用了并行比较,就是同时检查所有cache entity目前有无数据
而且物理地址没有index了
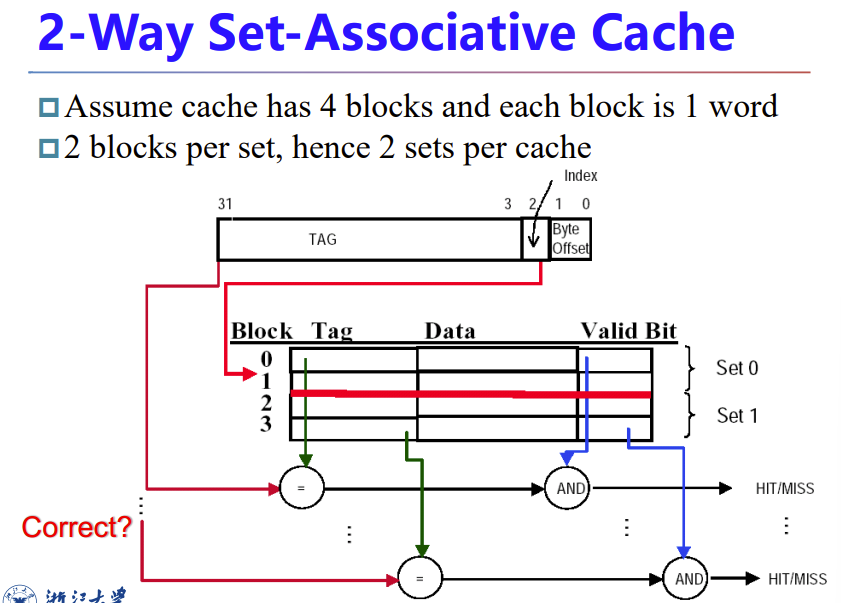
index指示set了
但是这图有问题,寻址应该寻的是set,而不是block
而且,set确定后只需要对set里面的entity进行valid bit比较即可,不需要全部比
Q3: Block Replacement
这问题直接映射能直接解决,另外两个需要另外看看,就set或cache满了该怎么替换
- Random replacement
- Least-recently used (LRU)
- 就是将最久没用的换出去,刚进来的不换
- MRU
- LRU反过来
- First in,first out(FIFO)
Q4: Write Strategy
- write-back cache
- 有个问题是cache里数据写了还没放回mem,需要进行保护
- 我们加一个dirty bit来标记这种entity
- 即,write-back cache 比 write-through cache 多一bit
- 效率更高,但是设计更复杂
- write-through cache
Write Stall
- Write stall --When the CPU must wait for writes to complete during write through
- Write buffers
- 即CPU和mem之间加一个small cache
- CPU写出会往 cache 和 Write buffers 一起写,让这个buffer消化写出操作
- 经常用于 write-through cache
Write Misses
- Write allocate
- 需要先从mem读入cache,再写
- Write around / No write allocate
- 不写cache,用 Write buffers 直接写入mem
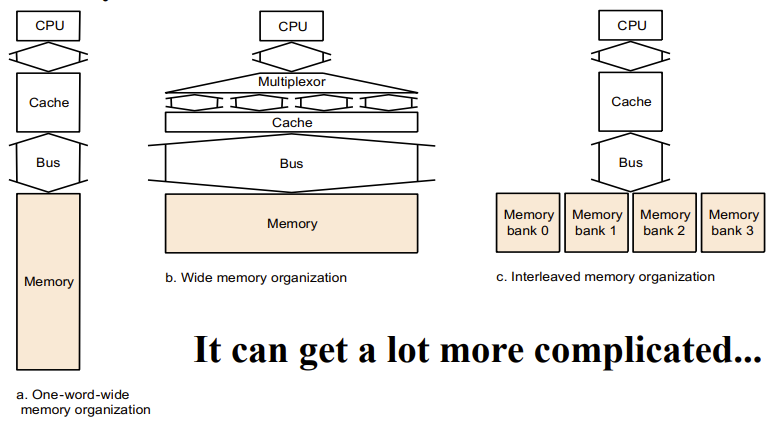
Memory system
Make reading multiple words easier by using banks of memory
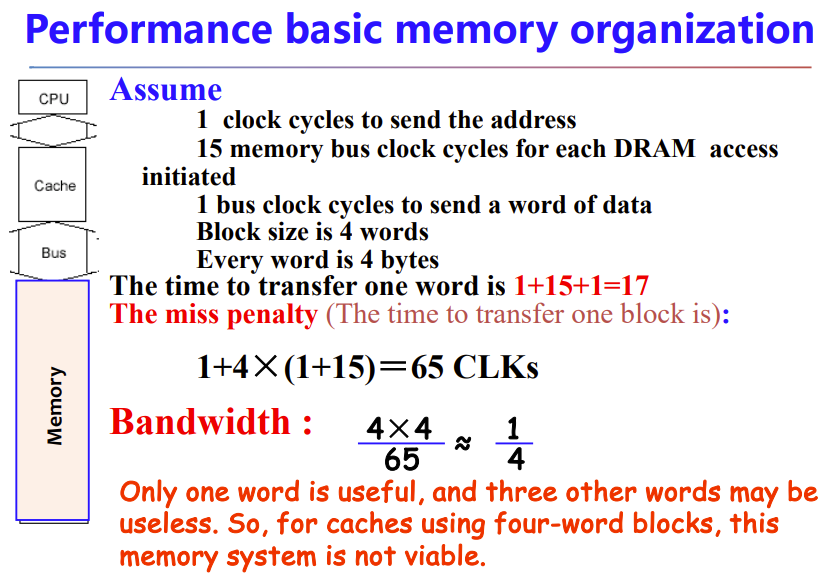
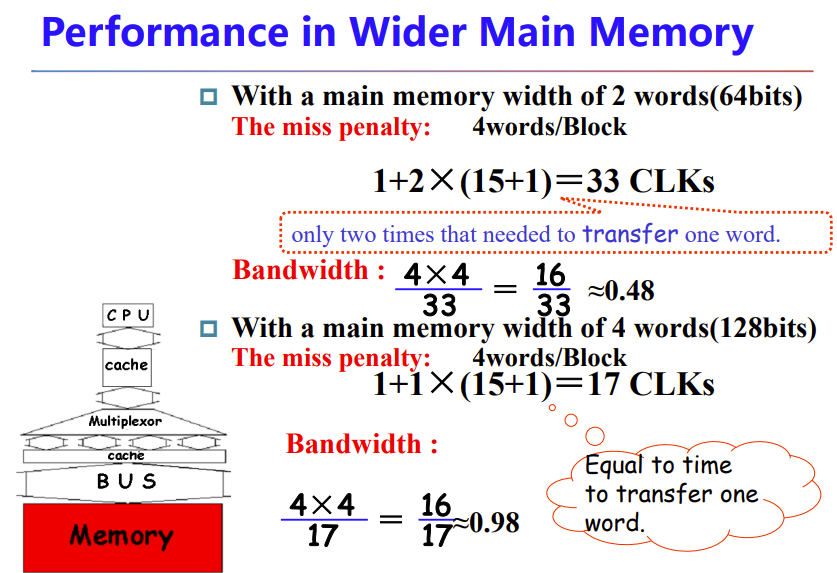
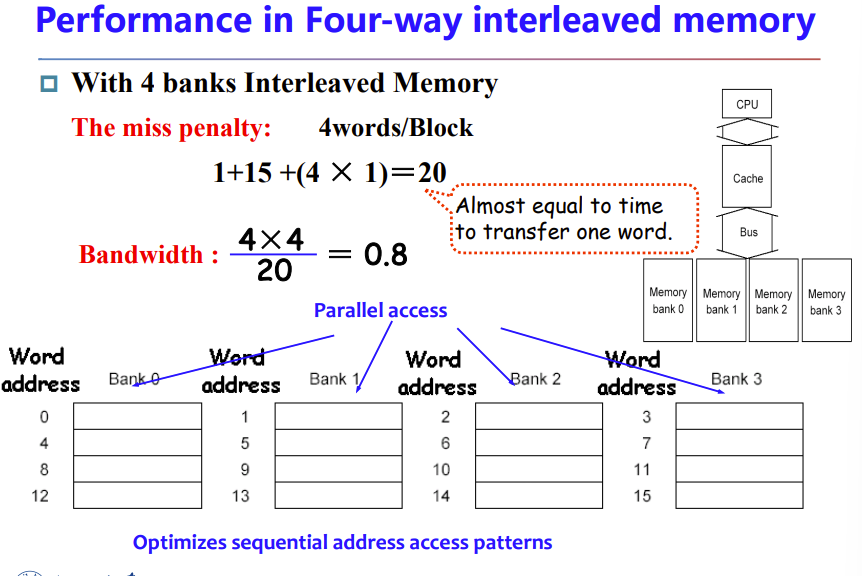
5.4 Measuring and improving cache performance
How to measure cache performance?
How to improve performance?
Measuring cache performance
Reducing cache misses by more flexible placement of blocks
Reducing the miss penalty using multilevel caches
- Average Memory Assess Time (AMAT) = hit time + miss time = hit time + miss rate × miss penalty
- Hit time: The time to access the upper level of the memory hierarchy, which includes the time needed to determine whether the access is a hit or a miss.
- find if hit or miss + cache to CPU
- miss penalty: The time to replace a block in the upper level with the corresponding block from the lower level, plus the time to deliver this block to the processor.
- mem to cache + cache to CPU
Measuring cache performance
之前的 CPU_time = Inst ×CPI × Clock cycle time
我们需要重新定义
"# of"通常表示“数量”或“总数”。
- CPU time = CPU execution clock cycles + Memory-stall clock cycles
- Memory-stall clock cycles = # of (mem) instructions × miss ratio × miss penalty = Read-stall cycles + Write-stall cycles

If the write buffer stalls are small, we can safely ignore them .
If the cache block size is one word, the write miss penalty is 0.
Combine the reads and writes
In most write-through cache organizations, the read and write miss penalties are the same in the time to fetch the block from memory
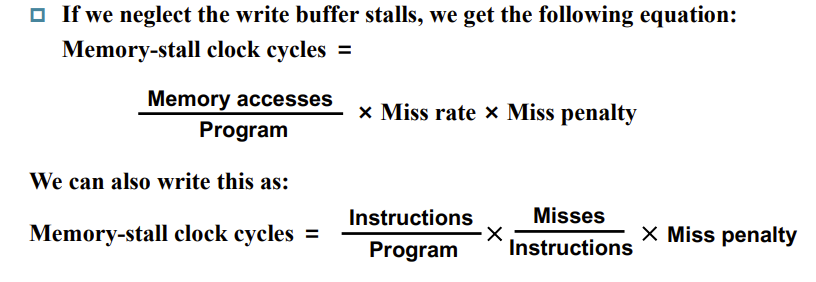
Calculating Cache Performance EXP
