Lecture 13 | APPENDIX | I/O
计算机组成2024-05-21第6-8节 (zju.edu.cn)
A.1 Introduction
Typical I/O Devices
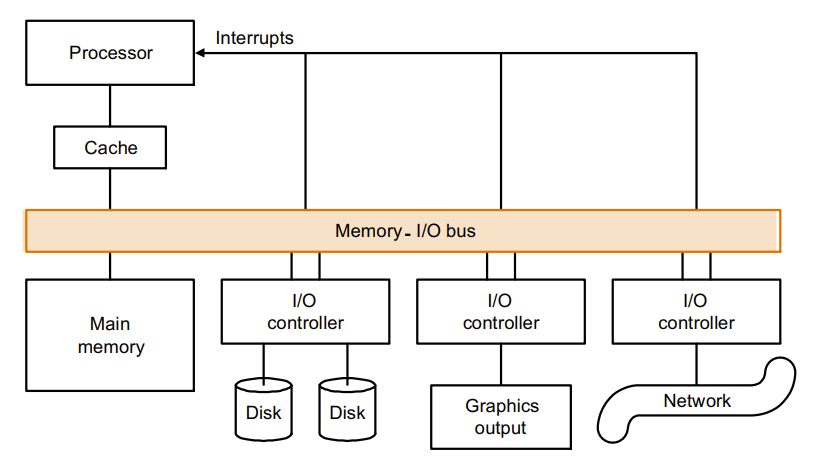
用总线接入所有I/O,CPU接入 总线(bus) 以获取规格统一的I/O信号
Three Characters of I/O
- Behavior
- 行为
- Input (read once)
- output (write only, cannot read)
- storage (can be reread and usually rewritten)
- Partner
- 对象
- Either a human or a machine is at the other end of the I/O device
- either feeding data to input or reading data from output
- Data rate
- The peak rate at which data are transferred between the I/O device and the main memory or processor
I/O Performance Depends on the Application
三种评价方式
- Throughput
- I/O bandwidth can be measured in two different ways
- 即,I/O的吞吐量分为了两类:数据和操作次数
- How much data can be transferred in a certain time
- How many I/O operations can be performed per unit time
- I/O bandwidth can be measured in two different ways
- Response time
- Both throughput and response time
单个组件的优化效果还是用这定理


A.2 Disk Storage and Dependability
- Magnetic disks
- 磁盘存储密度很高,持久性高,数据恢复性高,但是很慢
- SSD(Solid State Drive)
- 持久性差,一年不上电会丢失
The Organization of Hard Disk
Disks are organized into platters, tracks, and sectors
- platters
- each has two recordable disk surfaces
- tracks
- each disk surface is divided into concentric circles
- sectors
- 扇区
- each track is in turn divided into sectors
- the smallest unit that can be read or written

To Access Data on Disk
Access time包含以下四个部分
- Seek (time): position read/write head over the proper track
- 寻道时间
- average seek time (3 to 14 ms)
- seek time 比较费时
- Rotational latency: wait for desired sectors
- 寻找扇区的时间

- Transfer time
- time to transfer a sector (1 KB/sector) of data
- Disk controller
- control the transfer between the disk and the memory

Flash Storage
闪存
- Nonvolatile solid-state storage
- 也是SSD
Flash Types
- NOR flash: bit cell like a NOR gate
- Random read/write access
- 每个块都引一条线,可以随机访问(RAM)
- NAND flash: bit cell like a NAND gate
- 每个块串联,只能一页一页地写
Disk Performance Issues
Dependability, Reliability, Availability
- Dependability
- Reliability: 多久才坏,出错的概率
- Availability: 可正常使用的总时间
Measure
- MTTF (Mean Time to Failure)
- MTTR (Mean Time to Repair)
- MTBF (Mean Time Between Failures) = MTTF+ MTTR
- Availability = (MTTF) / (MTTF+MTTR)
- 反映能用的时间占总时间的多少
Array Reliability
就我们尝试将多个硬盘堆在一起以提高存储容量,看下可靠性
- Reliability of N disks = Reliability of 1 Disk ÷ N
- AFR (annual failure rate) = percentage of devices to fail per year
- AFR = 8760/time to fail for 1 disk
- “nines of availability” per year
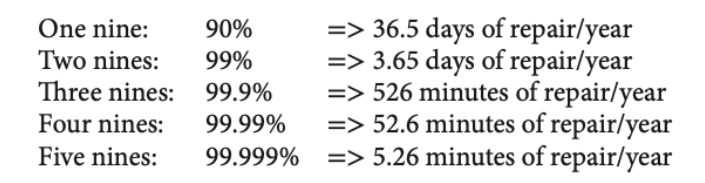

Three Ways to Improve MTTF
- Fault avoidance
- preventing fault occurrence by construction
- Fault tolerance
- using redundancy
- 出错的情况下还能正常运行
- Fault forecasting
- 预测错误
Redundant Arrays of (Inexpensive) Disks
RAID 底层本冗余阵列实现大容量磁盘
- Files are "striped" across multiple disks
- 文件分为多份,存在不同的磁盘上
- Redundancy yields high data availability
- 从冗余盘恢复信息
- Disks will still fail
- 会坏了但不怕
- Contents reconstructed from data redundantly stored in the array
- 从冗余盘恢复信息
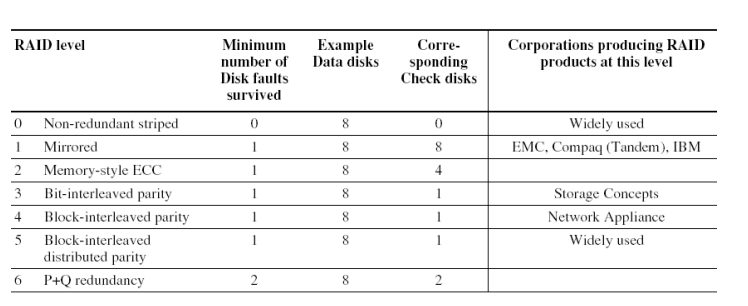
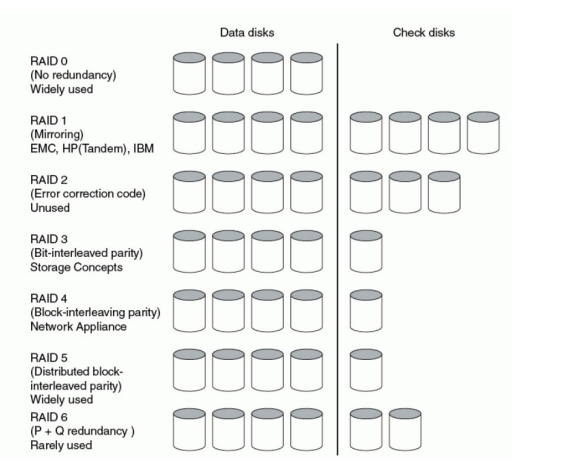
接下来考虑的磁盘坏掉不是里面的数据没了,而是这个磁盘挂掉了
RAID 0: No Redundancy
假的RAID,根本没有冗余,但是还是会拆分文件分开存
能提高access性能,多磁盘使用
RAID 1: Disk Mirroring/Shadowing
一个文件复制为两份,存两个盘
但是写的负荷大,因为要往两个硬盘写一模一样的文件
RAID 2不学
RAID 3: Bit-Interleaved Parity Disk
只用一张冗余盘与其它盘组合
对一个文件的每一个bit都存在不同的磁盘上,
冗余盘的值通过奇偶校验得到
P contains sum of other disks per stripe mod 2 (“parity”)
If disk fails, subtract P from sum of other disks to find missing information
有个问题,P盘是使用次数最多的盘,反而会最先坏
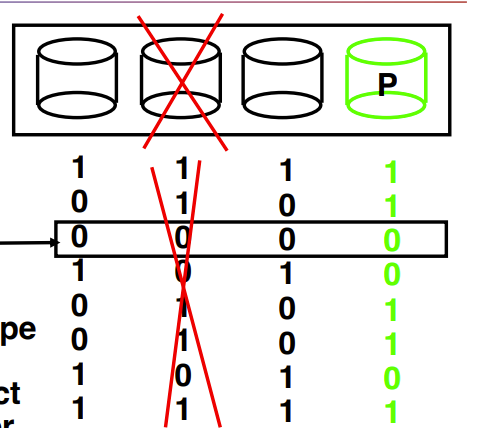
RAID 4:Block-Interleaved Parity
不要一个bit地存了,打包成一个块一个块地存
Example: small read D0 & D5, large write D12-D15
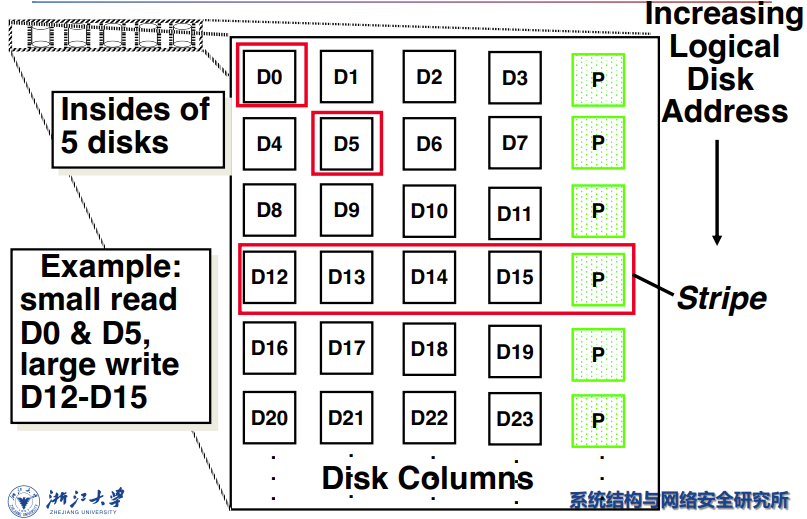
有个问题,前面的盘如果有更新,P也得更新,而且需要读取前面四个盘的数据,这样太麻烦了
我们可以检查被更新的块,如果没翻转就不用更新P了,否则就更新P
可以用两次xor进行检测
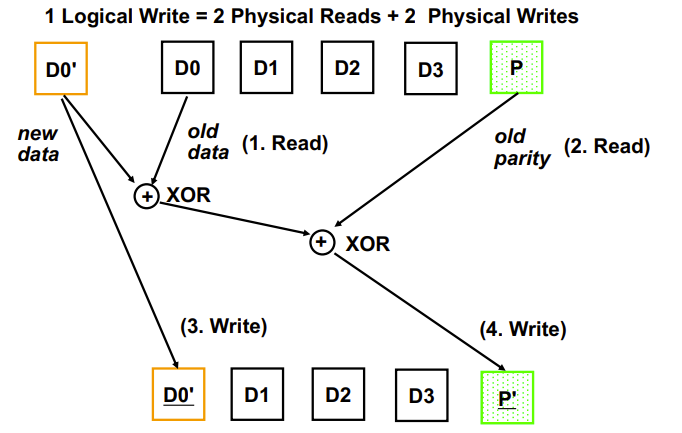
但是还有问题,对前面的盘进行修改,依旧需要更新P盘
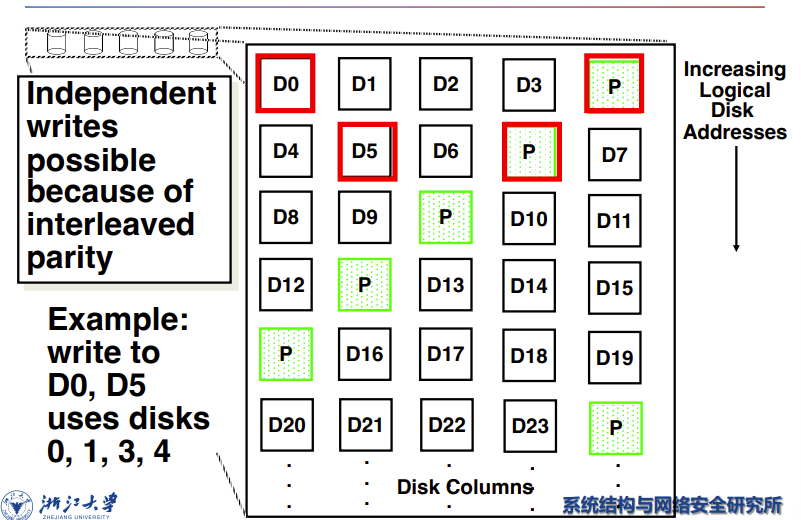
RAID 5: High I/O Rate Interleaved Parity
直接把P盘的block均匀分散到其它盘里面
RAID 6: P+Q Redundancy
与RAID 5相比就多了一个 check 盘

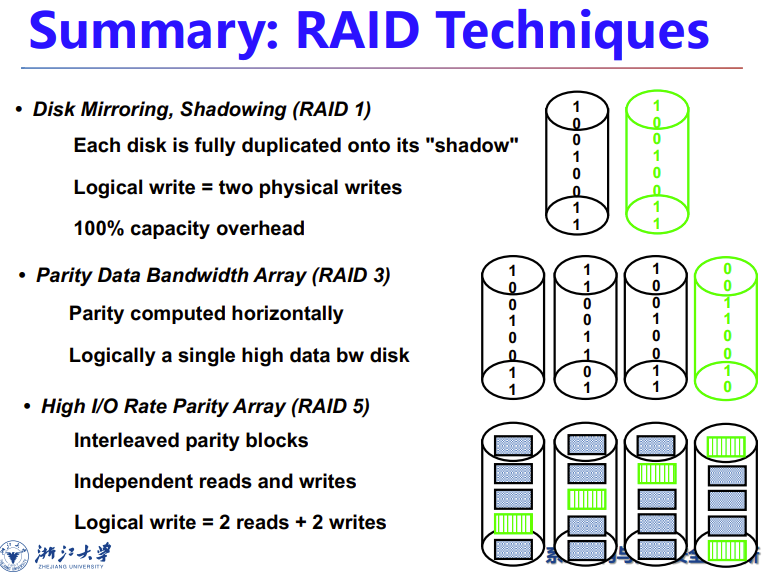

1是对的
2是对的
3是对的,会被P盘卡脖子
4是对的,因为所有盘所有信息都重写的,都被用满了
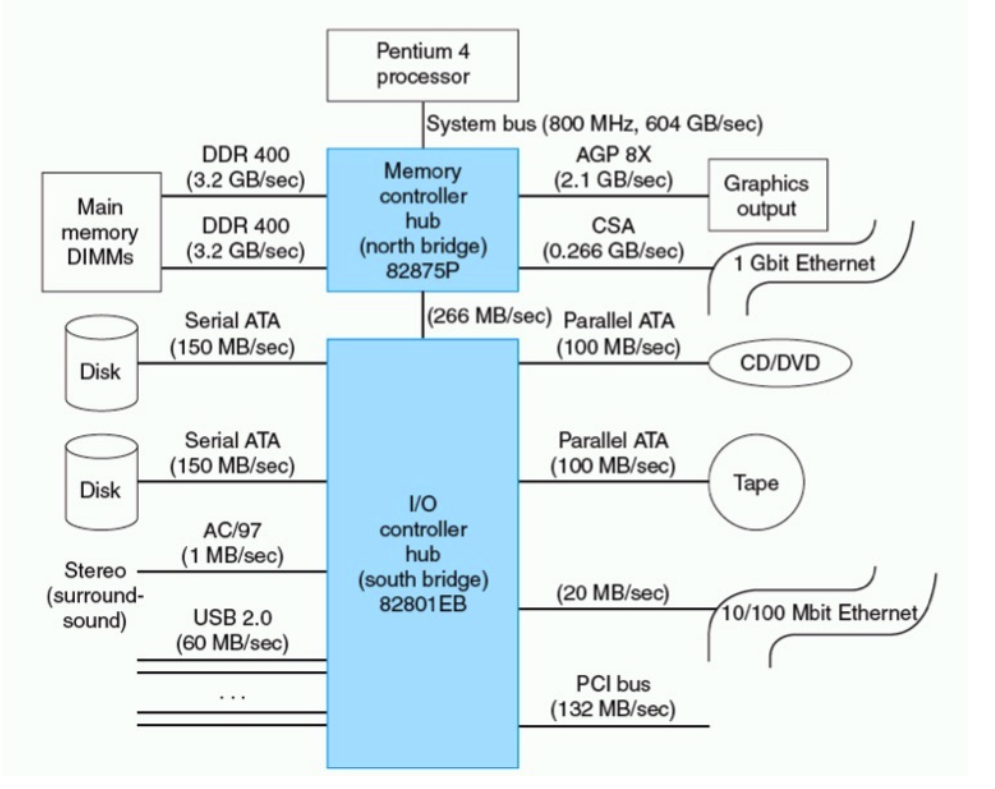
A.4 Buses and Other Connections between Processors Memory, and I/O Devices
- 南桥北桥
- 实际是一个控制器
- 高速设备挂北桥
- 低速设备挂南桥
- Bus: Shared communication link (one or more wires)
- 即,总线就是一个被不同设备共享的通路
- A bus contains two types of lines
- Control lines
- Data lines:
- 别忘了地址也是数据
- Bus transaction
- Include two parts
- sending the address
- receiving or sending the data
- Two operations
- input: receiving data from the device to memory
- output: sending data to a device from memory
- 都是和内存打交道
- Include two parts


Types of Buses
- Processor-memory : short high speed, custom design
- Backplane : high speed, often standardized
- I/O : lengthy, different devices, standardized


Synchronous vs. Asynchronous Buses
不同之间的设备建立连接
- Synchronous bus
- 所有设备工作频率相同
- 但是对于工作频率慢的设备不合理
- Asynchronous bus
- 请求过来的时候处理器才开始处理
- 使用握手协议处理
- Handshaking protocol
- A serial of steps used to coordinate asynchronous bus transfers
Asynchronous Example
这个图比较重要

I/O设备向内存请求取数据
Data在ReadReq发起请求时是地址
这四个数据线内存和I/O共享的
我们约定橙色的线为I/O发起的信号
- When memory sees the ReadReq line, it reads the address from the data bus, begin the memory read operation, then raises Ack to tell the device that the ReadReq signal has been seen.
- I/O device sees the Ack line high and releases the ReadReq data lines
- Memory sees that ReadReq is low and drops the Ack line
- When the memory has the data ready, it places the data on the data lines and raises DataRdy
- The I/O device sees DataRdy, reads the data from the bus , and signals that it has the data by raising ACK
- The memory sees Ack signals, drops DataRdy, and releases the data lines.
- Finally, the I/O device, seeing DataRdy go low, drops the ACK line, which indicates that the transmission is completed
下面来个例题看下两种总线速度差异
显然同步总线速度快,但CPU占有率高

- 同步取数据过程三大过程
- 发送地址
- 内存找数据
- 数据发过来
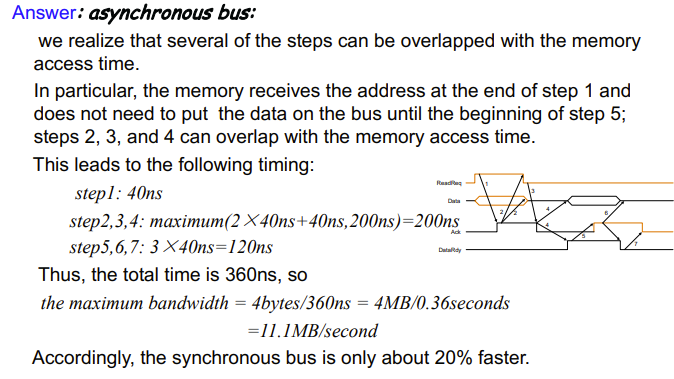
握手协议一共7步