Review 10 | Transactions
Transaction
Transaction Concept
并发控制与恢复由事务管理模块实现,即其操作对象是事务
事务是一串SQL语句的执行序列,可以包含多条语句,用于完成一个目的,是要commit的
要完整描述一个事务,我们需要用到ACID Properties 这个概念
- Atomicity (原子性)
- 构成事务的操作被看成一个整体看待,要么全部成功,要么全不执行
- 数据库恢复功能能实现原子性
- Consistency (一致性)
- 不会错误地修改数据库,相互关联的数据应该进行更新。比如转账转完总的钱应该不变
- consistency requirements include
- Explicitly (显式) specified integrity constraints : primary keys , foreign keys
- 就是定义表时人为定义的
- Implicit (隐式)integrity constraints, e.g.– sum of balances of all accounts minus sum of loan amounts must equal value of cash-in-hand
- Explicitly (显式) specified integrity constraints : primary keys , foreign keys
- Isolation (隔离性)
- 要求各并行事务相互之间不能影响,就像虚拟内存的分块、
- 会影响的就不要并行了,改串行
- Durability (持久性)
- 对数据库的成功修改是永久性的,除非被其它事务再次修改
- even if there are software or hardware failures
- 出故障时,数据库恢复功能能实现持久性,比如用日志
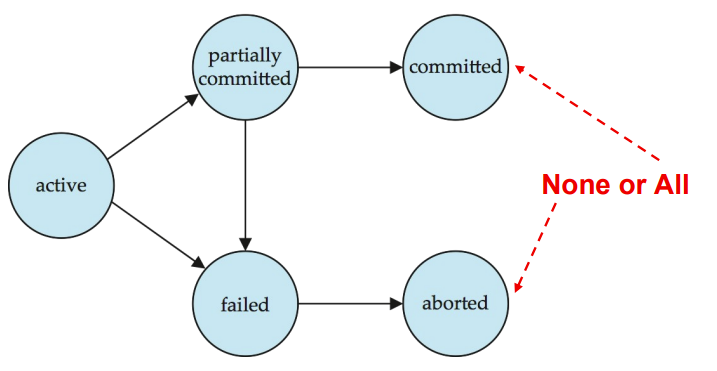
Transaction State
- Active
- 初始状态,事务正在执行
- Partially committed
- statement 执行完了,此时修改还在缓冲区没提交,可能会fail
- Failed
- 发现问题了
- Aborted
- 回滚之后就是这个状态,之后要么清除事务,要么重新执行
- Committed
Concurrent Executions
并行处理会遇到以下问题
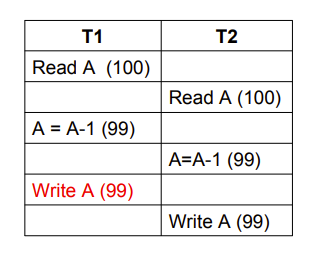
- Lost Update( 丢失修改 )
- 出现了交叉修改,其中一个被覆盖了
- 比如两个人同时买票
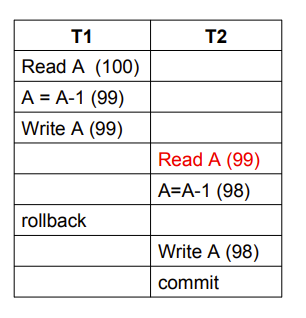
- Dirty Read (读脏数据)
- 比如一个人预定票结果没钱退了,另一个人正好在买票
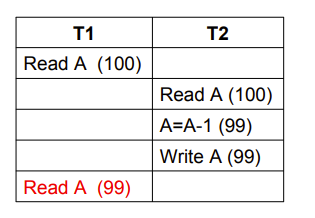
- Unrepeatable Read(不可重复读)
- 我们要求事务的隔离性,这里T1的第二次read被T2影响了,这是我们不希望出现的
- 我们要求事务的隔离性,这里T1的第二次read被T2影响了,这是我们不希望出现的
- Phantom Problem (幽灵问题)
- 和上一个类似,不过这里是指T1里面的第二次select由于收到T2影响,多了一个entity

Schedules(调度)
就是一组排好序以防止出现并行问题的事务,注意是一组事务
串行调度(serial schedule),先执行一个再执行另一个,肯定能保证正确

交叉调度,与Schedule 1等价

这个交叉调度等价于串行调度
这种能等价变化到串行调度的调度叫 Serializability( 可串行化 ) 的
Serializability
- Conflicting Instructions
- 操作对象相同,只要有写,就是冲突
- 操作对象不相同肯定不冲突
Conflict Serializability (冲突可串行化)
能通过交换非冲突指令变成另一个调度,就说这两调度是冲突等价的
Precedence graph(前驱图)有向边指示两者有一对冲突的操作,被指向事务指令时间在后
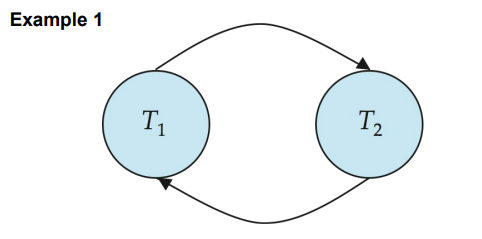
冲突的操作是不能交换次序的,所以如果两个事务能形成一个有向闭环,那肯定不能转化为串行
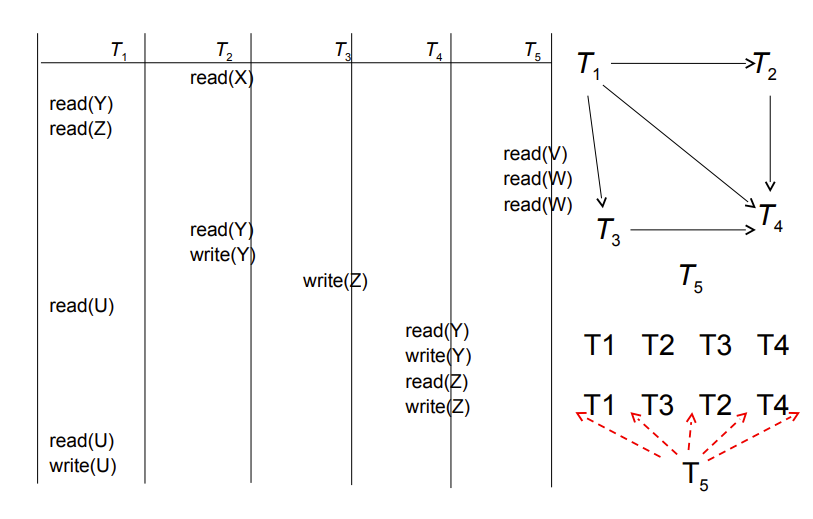
注意T5没有冲突,但是也要放进图里,可以放在串行调度里的任意位置(见右下角示意图)
Different forms of Serializability
view serializability 要求两个调度只要读操作获得的数值一致,且写操作写出去的数值也是一样的即可
Recoverable Schedules
- Recoverable schedule (可恢复调度)
- 比如,T1先写了A,T2再读了A,那么如果T1的commit先于T2,这就是可恢复调度
- 如果T2先commit,那么T1如果rollback就会导致T2读的是不一致的
Cascading rollback 即多个事务都一个接一个读和写,第一个错了就会导致后面的全部都要rollback
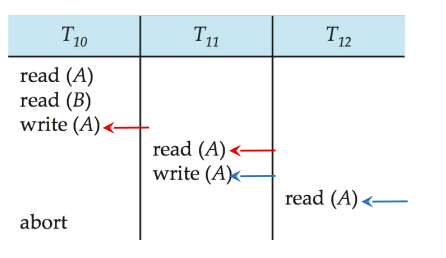
一个简单的解决办法就是规定不读脏数据,我们管采用这种规则的调度叫 Cascadeless schedules (无级联调度),脏数据即改了还没commit的数据
Transaction Isolation Levels
- Serializable
- Repeatable read
- only committed records to be read, repeated reads of same record must return same value.
- 不关心幽灵问题
- Read committed
- 不读脏数据
- Read uncommitted
- 能读脏数据
Concurrency Control Protocols
- Lock-Based Protocols
- 访问数据前需要申请相应的锁,一个数据同一时间只有一个锁
- Timestamp-Based Protocols
- 给每个事务一个时间戳,类似出生日期,且十分精确
- 根据时间戳决定次序
上面两种都是悲观的,即针对会出现问题的情况进行设计
下面这个是乐观的
- Validation-Based Protocols
- Each transaction must go through 3 phases:
- Read phase Validation phase Write phase
- Each transaction must go through 3 phases:
Concurrency Control
Lock-Based Protocols
basic two-phase locking(基本两阶段封锁),可串行,但不保证可恢复
可恢复的要求是不读脏数据
下面的两种加强版保证了可恢复性
- Strict two-phase locking(严格两阶段封锁)
- a transaction must hold all its exclusive locks till it commits/aborts
- Rigorous two-phase locking(强两阶段封锁)
- a transaction must hold all locks till commit/abort
- 很影响并发度
我们下面讲的是 basic 2PL protocol
事务访问数据前需要申请相应的锁,锁加给被操作的数据
exclusive (X)- Data item can be both read as well as written.
shared (S)- Data item can only be read.
管理器通过相容矩阵判断一个事务能不能提供锁

The Two-Phase Locking Protocol
这些协议是针对一个事务,而不是一个事务集
例如,一个事务满足下面两个先后阶段即可,不用所有事务都需同时在一个phase里,一个事务集里事务的lock point可以不同
- Phase 1: Growing Phase
- 加锁阶段
- Phase 2: Shrinking Phase
- 解锁阶段

-- Growing Phase
lock-S(A);
read (A);
lock-S(B); -- lock point
read (B);
-- Shrinking Phase
unlock(A);
unlock(B);
display(A+B)
这种协议保证了可串行性,且串行顺序为LP顺序,当然不是只能按照LP顺序串行
- delete就往要删的tuple加X锁
- insert就往刚插入的tuple加一个X锁
Lock Conversions
U-lock :update-lock,先表现为S,后面可升级为X,这种相互转化叫做Lock Conversions
lock-upgrade:S->Xlock-downgrade:X->S
以此我们得出新的可串行化协议:
- Two-phase locking with lock conversions
- 第一阶段只能update
- 第二阶段只能downgrade
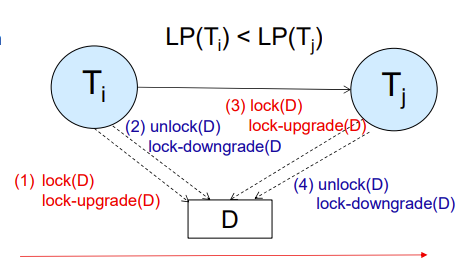
Implementation of Locking
lock manager:独立的进程,管理所有的锁,所有的锁都集中在一个地方,而不是真的物理上放在数据上
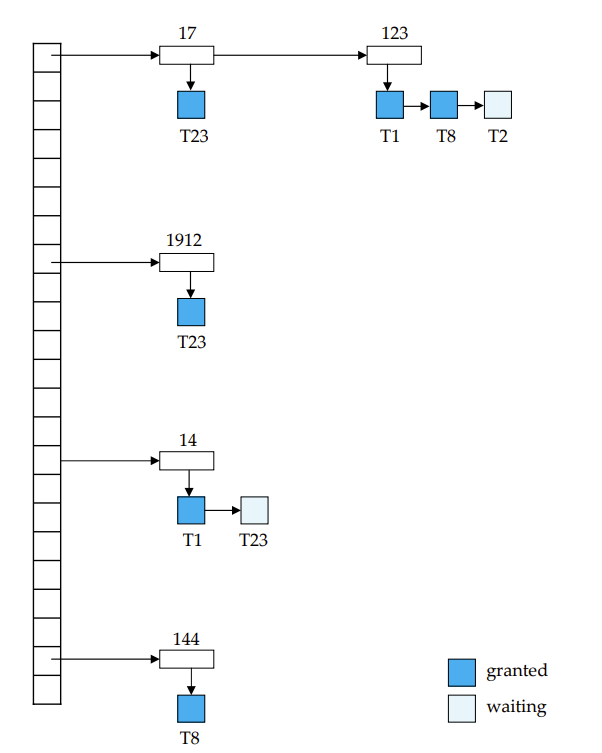
Lock Table
锁通过哈希表进行锁操作(就是标记一下这地方被锁了)
每个数据都会有一个id之类的标识,如果要被锁,就将其id交给lock manager,后者会将这个id映射到哈希表上,然后根据规则加锁标记
Deadlock Handling
死锁,就多个事务相互等待,陷入死循环了

Deadlock prevention protocols
- 一个事务开始前给其打上所有今后需要的锁 (predeclaration)
- 给数据访问操作进行合理的排序(graph-based protocol)
- Timeout-Based Schemes
- 等半天都等不到对方释放锁,就别等了,tnnd直接整个事务回滚重开
- 可能会 starvation,就在同一个地方反复回滚反复卡
Deadlock Detection
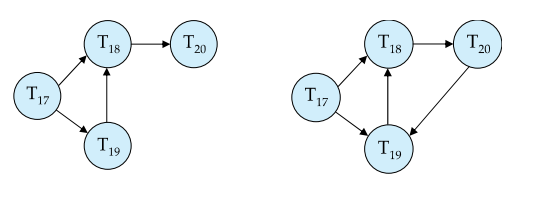
Deadlocks can be described as a wait-for graph
就是画等待关系,等待中的事务指向被等待的事务,有环就死锁了,即出现了相互等待的情况
显然这个图在不断变化,所以系统是定期来检测一次
Deadlock Recovery
选一个事务(victim)杀了(回滚),打破这个环
怎么选?
- 杀最年轻的(最晚开始执行的可能亦执行的操作比较少)
- 杀最老的(执行的操作很多,可能造成了很多死锁)
- 杀当前手上的锁最多的
- ......
当然,也可能出现starvation的情况,总是同一个人被杀,最好是均摊一下死亡次数
Graph-Based Protocols
另一种锁协议
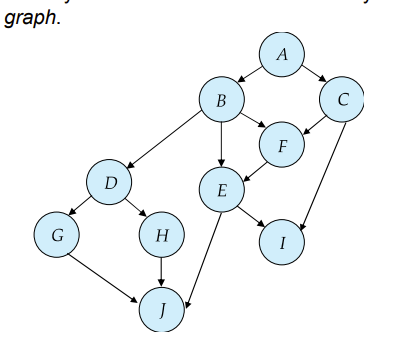
下面这个是 database graph,结点为数据
有向边表示有事务需要访问边两端的结点,而且有先后顺序,先访问指向后访问
如果没有环,就能设计出很好的协议,下面我们讲基于特殊的database graph设计的协议
Tree Protocol
如果 database graph是树,即只有一个根,那就能用这个协议
- 该协议只有exclusive locks ,没有S锁
- 对于一个事务来说,first lock 可以放在任意 data item 上
- 后续如果要加锁,数据的父节点必须有锁,否则该数据不能加锁
- 任意锁可在任意时间解锁
- 对于一个事务,每个数据只能锁一次,unlock之后不能再lock了
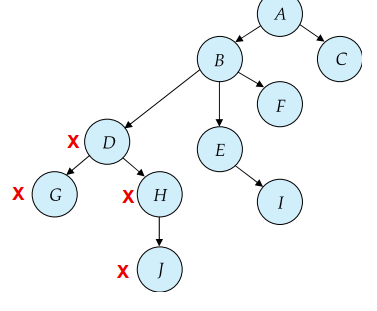
这样能保证冲突可串行,防止死锁,但不保证恢复性,加的锁会更多
Multiple Granularity(多粒度)
把每种数据看成一个颗粒,有粗有细,以此分为不同等级(hierarchy of data granularities),一个等级即一个粒度
锁可以加在任意需要的颗粒上,比如锁一张表,锁一个B+树
- fine granularity(细粒度)
- lower in tree
- high concurrency, high locking overhead
- coarse granularity(粗粒度)
- higher in tree
- low locking overhead, low concurrency
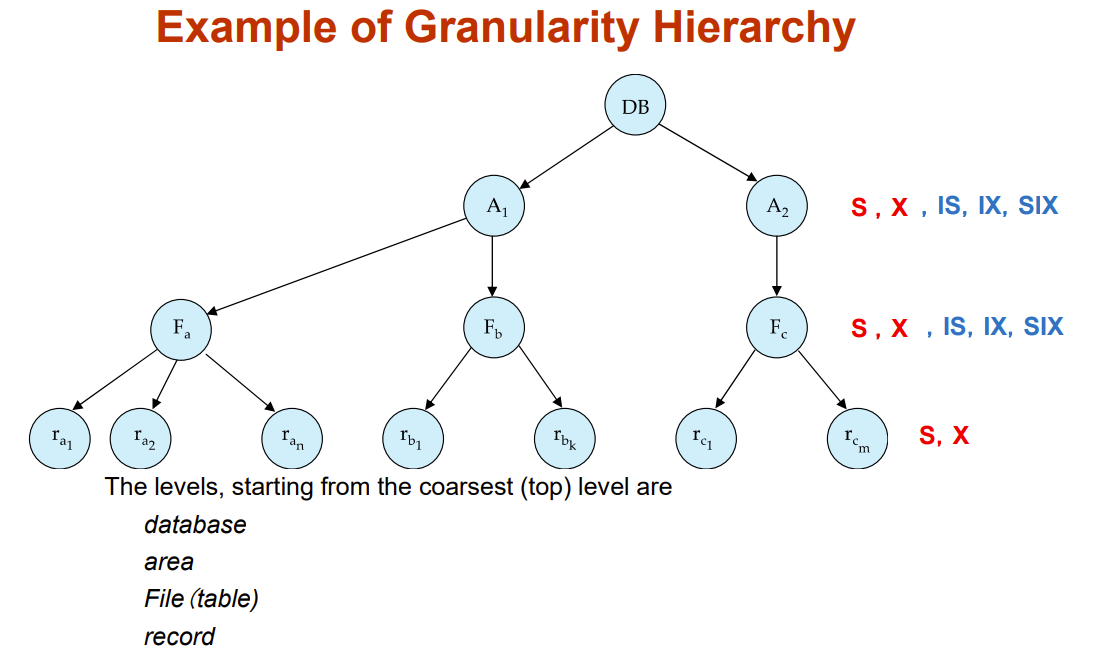
三个新锁对于基粒(最小的颗粒)不作用
- intention-shared (IS)
- 一个事务意向给基粒加S锁,就给其所有祖父结点加IS锁,表有事务有意向访问该子树里的数据并给其加S锁
- intention-exclusive (IX)
- 同IS,不过既可以加S也可以加X
- shared and intention-exclusive (SIX)
- 表示里面的颗粒不需要加S锁也可以读,但是写还是要X锁
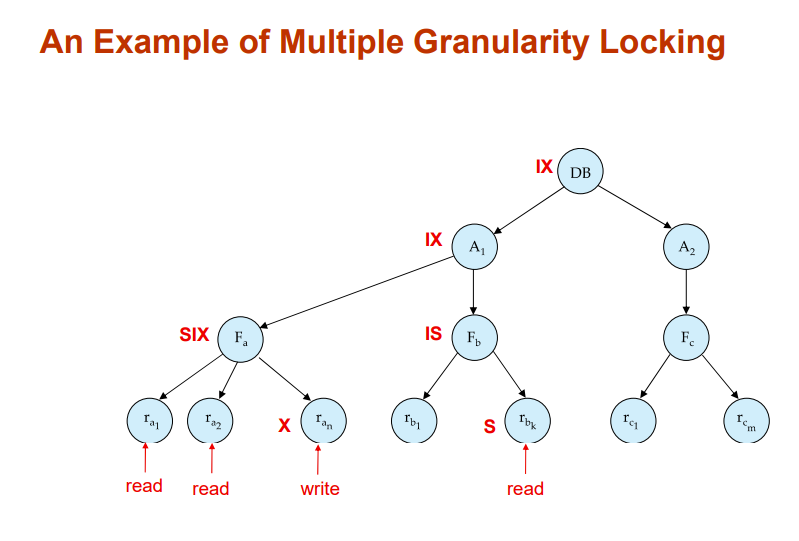
Multiple Granularity Locking Scheme
Transaction Ti can lock a node Q, using the following rules:
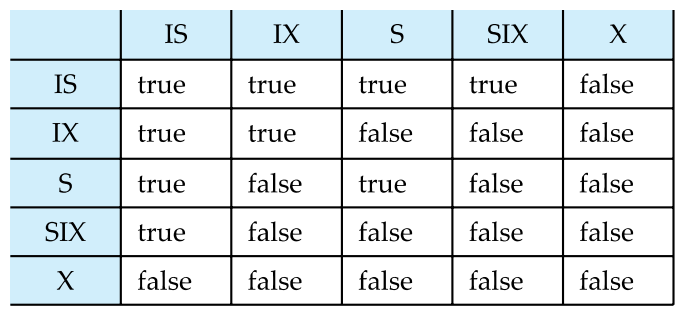
- 严格遵循相容矩阵
- 根需要第一个被锁,随便选一种锁就行
- 父子关系:IX/IS -> S/IS
- 父子关系:IX/SIX -> X/SIX/IX
- 要求事务遵循两阶段锁协议
- 加锁从上往下,解锁从下往上
Handling Phantoms
Insertions and deletions can lead to the phantom phenomenon.我们可以用索引等方式高效解决
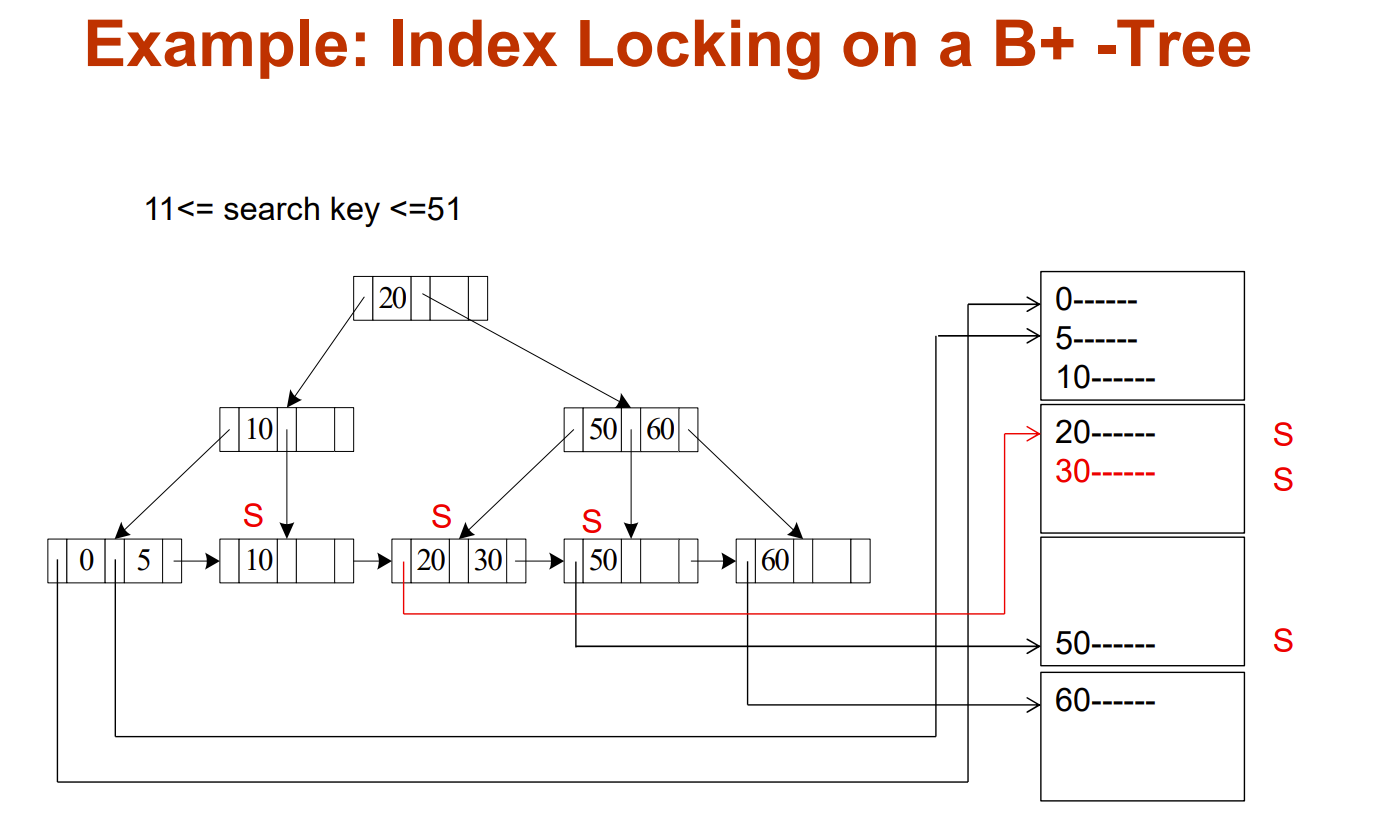
Index Locking Protocol To Prevent Phantoms
通过索引用S锁住所有与要读的数据集有相同key的数据,防止出现X锁
Multiversion Concurrency Control Schemes(MVCC)
之前都是单版本并发控制,一个信息只有一份,修改只能覆盖原来的
我们可以多版本,修改后产生新版本,而不是进行覆盖
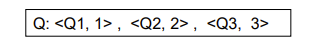
- Q1, Q2,...是数据,右边的数字是时间戳,反映新旧程度,越大表示越新
- 一个数据有多个版本,这些版本共同组成一个整体,锁只能加在这个整体上
这个协议需要先声明一个事务是 read-only transactions 还是 update transactions,即只读和允许编辑
只读不用加锁,直接读最新的
写需要先申请S锁,然后复制最新的数据,时间戳设置为无穷大,表示尚未提交,不能被其它指令修改;修改好后计数器+1,更新新版本的时间戳,最后才解锁
这是严厉的两阶段锁协议