REVIEW 5 关系数据库设计和关系规范化
一个不好的关系数据模式会产生数据冗余、数据更新异常等问题。
为了解决这些问题,我们可以把不规范的关系模式分解为规范化的关系模式。
BCNF是函数依赖范畴内规范化程度最高的关系模式,而3NF是比BCNF低的规范化形式。
一个关系模式总能无损连接地分解为BCNF 的关系模式,但不一定能保持函数依赖;若要求分解既是无损连接的又是保持函数依赖的,则保证可以分解为3NF。
通过考察多值依赖,还可以获得更高规范化的关系模式,即4NF。
好的关系模式应该保证只有key可以唯一确认一条tuple,即整个schema只能有主键这一个候选键
而且一个schema应该少点属性,这样一张表也能小很多
但是我们需要关注的是,拆分后的schema与原来的schema是否有数据变化
例如,将下面的schema拆分为两个schema
inst_dept(id,name,salary,dept_name, building, budget)->
teacher(id,name,salary,dept_name)->
dept(dept_name, building, budget)可以通过 自然连接 才能无损恢复
确认一个关系模式好坏的具体理论,包括:
- functional dependencies
- multivalued dependencies
怎么判断一个分解是不是无损连接分解
分解后各关系的交是其中一个关系的候选键
Functional Dependencies
什么是函数依赖

就是只要属性\(\alpha \(的value确定了,\)\beta\)也就确定了
两个tuple的\(\alpha\)相同,那么\(\beta\)也一定相同
如果\(\alpha\)和\(\beta\)单独组表,那前者就是主键
例如,学号 -> 姓名
有一种没有任何意义的、普遍存在的函数关系我们称为trivial(频繁),比如自己依赖自己,子集依赖父集,都没意义,我们一般不考虑这玩意儿,
Closure(闭包)
闭包分为函数依赖的和属性集的
of a Set of Functional Dependencies
一个关系模式里面,有重叠的函数依赖可以推出新的函数依赖。
所有 同一个起点的 函数依赖,就是这个起点的闭包。

下面有三条公理叫做 Armstrong's Axioms,用于推演 \(F+\) 的成员

自反律就是trivial
第二个\(\gamma \alpha\)是并在一起的意思
由公理可推导更多的定理:

例题

of Attribute Sets
就能通过关系依赖被A决定的属性,包括A本身,组成的属性集合就是A的闭包
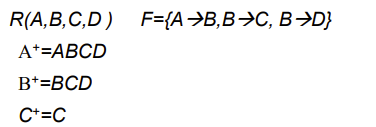
和上面的区别就是集合元素变成了属性,简洁很多
获取属性闭包画函数依赖的单向图(Graph)就行了
例题

Canonical Cover(正则覆盖)
刚刚说的闭包是尽可能列出所有的函数依赖,会有很多重叠的
正则覆盖类似线性代数里基的概念,在函数依赖中找到最小的、但是却可以确定所有函数依赖的函数依赖集合
闭包用 \(F+\) 表示,正则覆盖用 \(F_c\) 表示
例题

左边一样的话右边要合并,要求元素最少
做题就从选项最小的开始检查
Dependency Preservation
原来每一条函数依赖都能在被分解后的任意一个表上得到验证,那么就称这个分解是满足 依赖保持 的
注意是在每一个表里面能够独立地检验所有的依赖保持,或者说每个表都保留了原表的正则覆盖
分解后的每一张表剩下的函数依赖的并,正好是原表有的函数依赖,那么就称这个分解是满足 依赖保持 的
或者说,每张表剩下的正则依赖凑一起能得到原表的正则依赖

例题

Normal Form
1NF
- 表中无表,即每个属性都是不可分割的。
- Identification numbers like CS101 that can be broken up into parts
- 不满足第一范式的数据库就不是关系型数据库,所以说能在 MySQL 建立的表肯定满足第一范式。
2NF
- 满足 1NF 的基础上,非主属性必须完全依赖于主属性。
- 即主键整体才能确定一个非主属性。
- 如果主键的部分属性就确定了一个非主属性就不满足第二范式。
例如,一个表为 R (学号,课程号,成绩,姓名, 老师,老师职称),学号和课程号叫做关键码
知道了学号就可以确定一个学生,并不需要课程号。
这个R就不是第二范式
Boyce-Codd Normal Form
一个关系模式,如果只有一个key,就是BCNF
用函数依赖来定义就是,这个关系模式所有的函数依赖,要么左边是超键,要么就是trivial
Decomposing a Schema into BCNF
始终保持一个原则:无损分解3NF及之后才能保证无损分解
算法

人话:如果目前的result里面有非BCNF的,就在这个schema里面找一个左边不是key的函数依赖 \(\alpha \rightarrow \beta\),这是搅乱一锅粥的老鼠屎,所以我们直接将其拆分出来,\(\alpha\)和\(\beta \(单独组成新的schema,\)\alpha\)作为key,原来的schema去掉\(\beta\),但不去掉\(\alpha\)
例题

3NF
满足第二范式,且消除对主属性的传递依赖
或者说,任何一条函数依赖,要么是频繁的,要么左边是key,要么右边的属性包含在某个candidate key 里面
显然是BCNF弱化的版本,因为对函数依赖的右侧多了要求
有一张表 R (学号,课程号,成绩,姓名, 老师,老师职称)
我们可以发现(学号,课程号)之所以能决定教师职称并不是直接得出来的,是因为我们先由此推出老师是谁,才知道教师职称。
即X(学号,课程号)→Y(教师),Y(教师)→Z (教师职称) 导致的X(学号,课程号)→Z(教师职称)。
我们称教师职称是传递依赖于(学号,课程号)。
存在传递依赖也有弊端,比如:
老师职称改变了,要修改很多条数据。(修改异常)
没人选某个老师的课时候,该老师的职称记录就会被全部删除。(删除异常)
新来老师还没有定教哪门课,教师职称不知该保存到什么地方。(插入异常)
所以,我们必须消除传递依赖。具体做法就是消除传递依赖的非主属性:
(学号,课程号,成绩,教师)
(教师,教师职称)
三范式分解算法

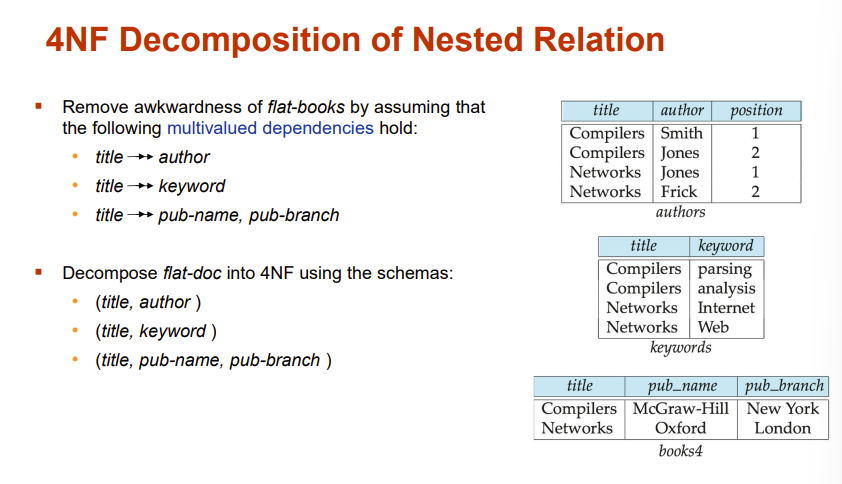
4NF
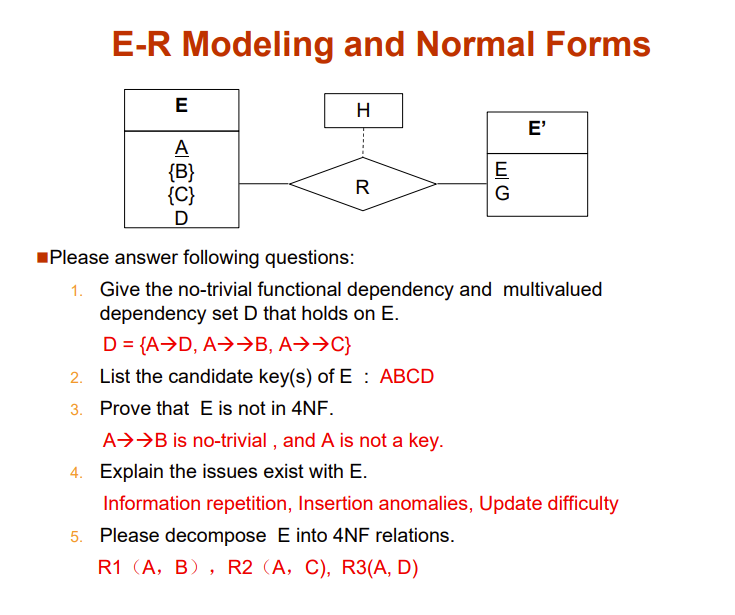
引入
我们先看下面这个例子
不止这一个ID哈,只是截取了ID为99999的tuple

好垃圾啊,三个属性一起上才能锁定一个tuple,但这关系里的函数依赖是trivial,这意味着这是一个BCNF
明显有信息冗余,而且如果一个老师没有孩子,根本插不进去,修改信息也很困难
说明这种情况下BCNF不是最好使的,直观上还是得拆成两个表:

我们需要第四范式!!!
Multivalued Dependencies (MVDs)
就是上面一个ID决定了一组child_name ,一个ID决定了一组phone_number
- ID →→ child_name
- ID →→ phone_number
函数依赖是多值依赖的特殊形式
If A→B, then A→→B
Fourth Normal Form
除了左边是key的多值依赖,只存在频繁的多值依赖,就是四范式
例子
Lecture 8: Complex Data Types
Object-based Databases
????