REVIEW 7 | Indexing
Basic Concepts
索引用来加快数据获取,用到 Search Key ,即一个专门用于寻找record的属性
An index file consists of records called index entries, of form: search-key|pointer,这个pointer 就指向对应的 record
Two basic kinds of indices
- Ordered indices: index entries 按 search keys 顺序排序
- Hash indices: 根据search key计算出存储地址
- 但是很难找到均匀的哈希函数,所以还是用Ordered indices更多
Ordered Indices
Basic
顺序索引基于建立索引的属性情况,又分两种类型:
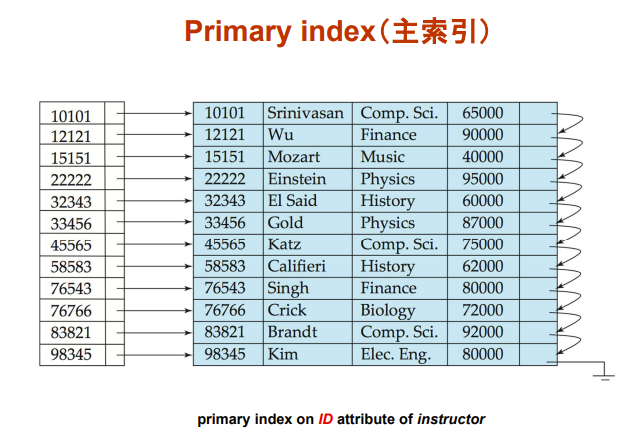
- Primary index(主索引)
- 也叫 clustering index(聚集索引)
- 源文件中的record已经按照某attribute的顺序排下来,建立在这个attribute上的index就是primary index
- 不一定是主键哈
- 主索引的 search key 次序与物理文件排放次序一样,所以是最高效的索引
- 一个物理文件一般最多一个主索引
- Secondary index(辅助索引):search key次序与物理文件排放次序不一样
- 显然辅助索引很难更新
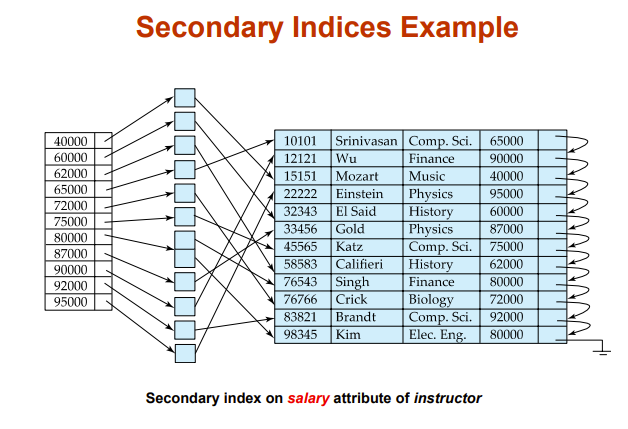
注意不是直接
40000->record里的40000,而是中间多一个容器这些容器包含所有属性值相同的record的地址,比如40000指向的容器包含所有属性值为40000的record地址
因为一个40000可能对应多个record
这个应该不是辅助索引特有的,而是另外的设计
顺序索引基于索引密度,又分两种类型:
- Dense index(稠密索引):每个record都有个索引项
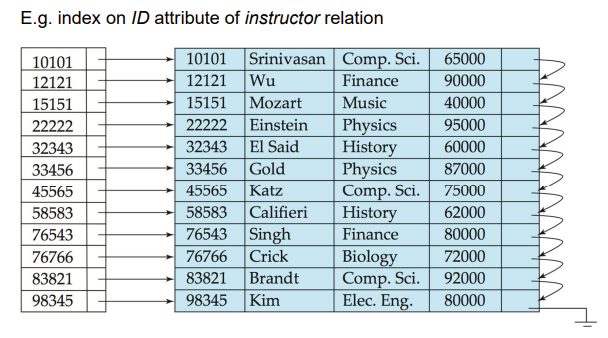
- Sparse Index(稀疏索引):用类似二分法的思想,结合顺序查找
- 稀疏索引只能建立在主索引上,不然无法顺序查找

B+-Tree Index Files
index file 用B+树文件组织方式
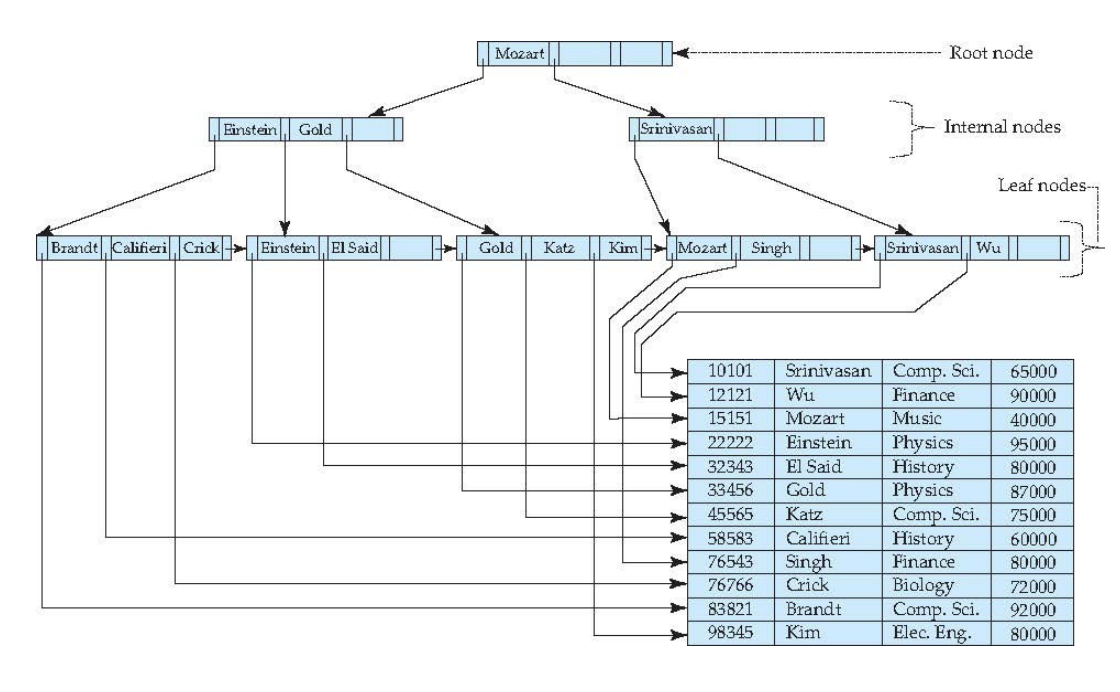
B+树每一个node占用disk的一个block,一个block有4KiB,所以很大
B+树的各类操作见ADS笔记,会考
B+- tree : height and size estimation
重要考点,计算占用的空间大小
下面举个例子开看看

我们要求的是:
- 每个record的大小
- 每个block可以放多少个record
- n个record需要多少个block
- fan-out是B+树的一个node多少个pointer,即多少阶
这个计算还不懂,之后重新看下智云

注意删掉叶子时,不用管内部节点,即不需要再删除一次,与ADS讲的不一样
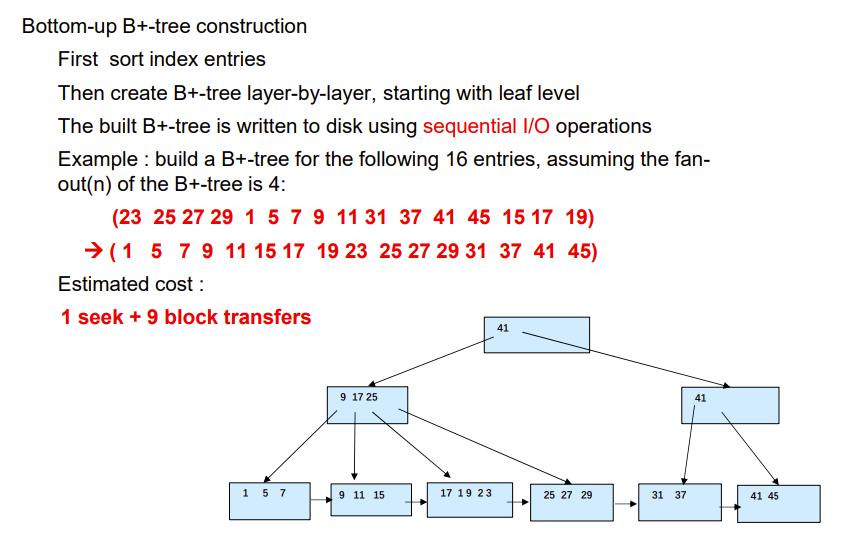
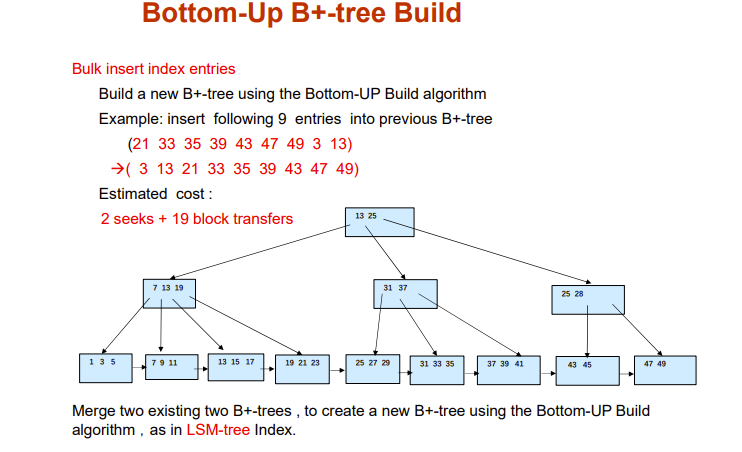
Bottom-Up B+-tree Build
Log Structured Merge (LSM) Tree
20240620 补天
在计算机科学中,Log-structured merge-tree(LSM 树),也称为 日志结构合并树,是一种数据结构,用于高效存储和检索磁盘或闪存存储系统中的键值对。LSM 树通过结合内存和基于磁盘的结构来优化读写操作。
LSM 树的主要特点包括:
- append-only 存储: 新数据始终附加到 LSM 树的末尾,而不是更新现有数据。这使得写操作非常高效,因为它们不需要磁盘寻道。
- 分层存储: LSM 树使用分层存储结构,其中数据存储在不同的存储层中。每个存储层都针对其各自的存储介质进行了优化。例如,内存层用于快速访问最新数据,而磁盘层用于存储较旧的数据。
- 批量合并: LSM 树定期合并相邻的存储层以消除碎片并提高读取性能。
LSM 树的优点包括:
- 高写性能: LSM 树非常适合写入密集型工作负载,因为它们可以提供高吞吐量的写入操作。
- 可扩展性: LSM 树可以轻松扩展以容纳更多数据,因为它们可以添加新的存储层。
- 压缩: LSM 树可以有效地压缩数据,以减少存储空间。
LSM 树的缺点包括:
- 读取性能: LSM 树的读取性能可能不如其他数据结构,例如 B 树,因为它们需要合并多个存储层才能检索数据。
- 复杂性: LSM 树比其他数据结构更复杂,因此可能更难实现和维护。
LSM 树的常见应用包括:
- NoSQL 数据库: LSM 树是许多流行的 NoSQL 数据库(例如 Cassandra、ScyllaDB 和 RocksDB)的核心数据结构。
- 键值存储: LSM 树用于各种键值存储应用程序,例如缓存和日志记录。
- 文件系统: LSM 树用于一些文件系统,例如 ZFS 和 Btrfs。
总而言之,LSM 树是一种高效的数据结构,适用于写入密集型工作负载。它们具有高写性能、可扩展性和压缩能力,但读取性能可能不如其他数据结构。LSM 树常用于 NoSQL 数据库、键值存储和文件系统。