Lecture 14 | Concurrency Control
ch18 - Concurrency Control new.pdf
数据库系统2024-05-27第6-8节 (zju.edu.cn)
什么样的并发控制能保证事务都产生可串行调度
然后检测是不是可恢复的
卡斯特调度
Lock-Based Protocols
事务访问数据前需要申请相应的锁,锁加给被操作的数据
exclusive (X)mode- Data item can be both read as well as written.
X-lockis requested using lock-X instruction.
shared (S)mode- Data item can only be read.
S-lock isrequested using lock-S instruction
锁不止这两种,我们只学这两种
如果锁冲突了要等待
管理器通过下面的相容矩阵判断一个事务能不能提供锁

数据库往往是自动隐性加锁


The Two-Phase Locking Protocol
这些协议是针对一个事务,而不是一个事务集
例如,一个事务满足下面两个先后阶段即可,不用所有事务都需同时在一个phase里,一个事务集里事务的lock point可以不同
- Phase 1: Growing Phase
- 加锁阶段
- 这个阶段事务可以获得锁,不能释放锁
- Phase 2: Shrinking Phase
- 解锁阶段
- 可以释放锁,不能获得锁

注意有个lock point的概念
-- Growing Phase
lock-S(A);
read (A);
lock-S(B); -- lock point
read (B);
-- Shrinking Phase
unlock(A);
unlock(B);
display(A+B)
- Two-Phase Locking Protocol assures serializability.
- 这种协议保证了可串行性
- the transactions can be serialized in the order of their lock points
- 不是只能按照LP顺序串行,而是这样一定可以,其它的也有可能
证明很简单,因为两个事务对一个数据进行冲突操作,需要前一个事务完成unlock之后,第二个事务才能开始lock
这意味着 \(LP1<LP2\)
如果形成了一个环,会得到 \(LP1<LP1\) 的结论,这是荒谬的
所以不可能形成环,即这种协议保证了可串行性
上面讲的是 basic two-phase locking(基本两阶段封锁),可串行,但不保证可恢复
可恢复的要求是不读脏数据
下面的两种加强版保证了可恢复性
- Strict two-phase locking(严格两阶段封锁)
- a transaction must hold all its exclusive locks till it commits/aborts
- Rigorous two-phase locking(强两阶段封锁)
- a transaction must hold all locks till commit/abort
- 很影响并发度
Two-phase locking is not a necessary condition for serializability.
下面的例题就属于一个反例

明显T1可以不遵守两阶段封锁协议,但是T1~T3可串行
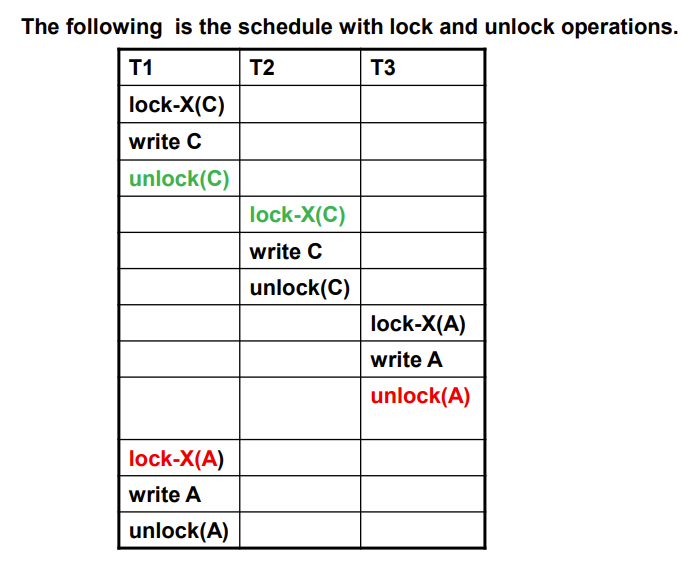
Lock Conversions
我们之前讲过的锁有S-Lock和X-Lock这两个基本的锁
U-lock :update-lock,先表现为S,后面可升级为X
还有些锁可以反过来
这种相互转化叫做Lock Conversions
lock-upgrade:S->Xlock-downgrade:X->S
以此我们得出新的可串行化协议:
- Two-phase locking with lock conversions
- 第一阶段只能update
- 第二阶段只能downgrade
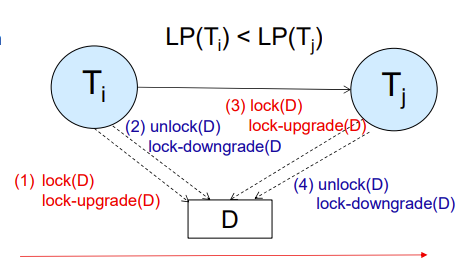
Implementation of Locking
- lock manager:独立的进程,管理所有的锁
- 所有的锁都集中在一个地方,而不是真的物理上放在数据上
lock manager maintains a data-structure called a lock table to record granted locks and pending requests
Lock Table
锁通过哈希表进行锁操作(就是标记一下这地方被锁了)
每个数据都会有一个id之类的标识,如果要被锁,就将其id交给lock manager,后者会将这个id映射到哈希表上,然后根据规则加锁标记
New request is added to the end of the queue of requests for the data item, and granted if it is compatible with all earlier locks
Unlock requests result in the request being deleted, and later requests are checked to see if they can now be granted
If transaction aborts, all waiting or granted requests of the transaction are deleted
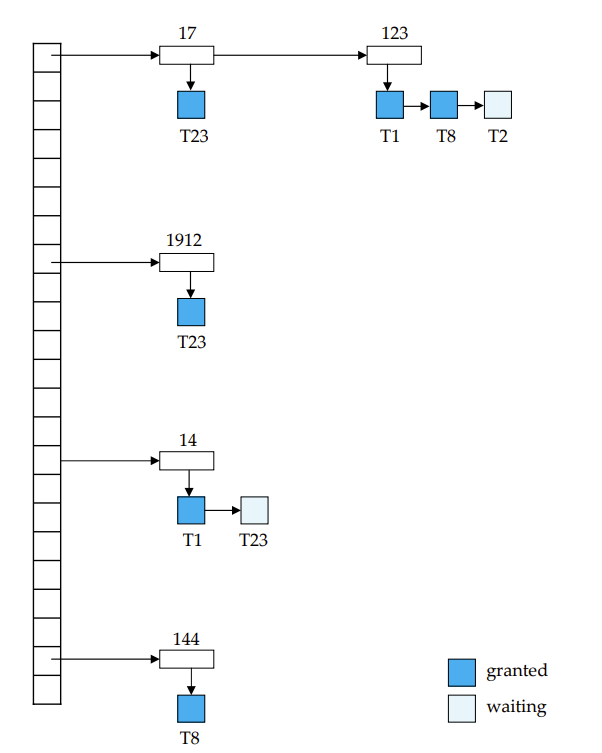
Deadlock Handling
死锁,就多个事务相互等待,陷入死循环了
System is deadlocked if there is a set of transactions such that every transaction in the set is waiting for another transaction in the set.
这个问题是普遍的

Deadlock prevention protocols
- Require that each transaction locks all its data items before it begins execution
- 一个事务开始前给其打上所有今后需要的锁(predeclaration)
- Impose partial ordering of all data items
- 给数据访问操作进行合理的排序(graph-based protocol)
- Timeout-Based Schemes
- a transaction waits for a lock only for a specified amount of time
- 等半天都等不到对方释放锁,就别等了,tnnd直接整个事务回滚重开
- 有个问题,有些本来就设计上要等很久,所以得把控最多等多久
- simple to implement; but starvation is possible.
- starvation:就在同一个地方反复回滚反复卡
Deadlock Detection
Deadlocks can be described as a wait-for graph
就是画等待关系,等待中的事务指向被等待的事务
有环就死锁了,即出现了相互等待的情况
显然这个图在不断变化,所以系统是定期来检测一次
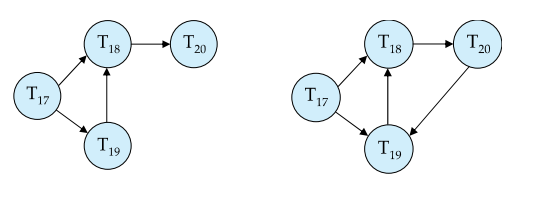
Deadlock Recovery
选一个事务(victim)杀了,打破这个环
杀其实就是回滚
怎么选?
- 杀最年轻的(最晚开始执行的可能亦执行的操作比较少)
- 杀最老的(执行的操作很多,可能造成了很多死锁)
- 杀当前手上的锁最多的
- ......
当然,也可能出现starvation的情况,总是同一个人被杀,最好是均摊一下死亡次数
下面来一道例题
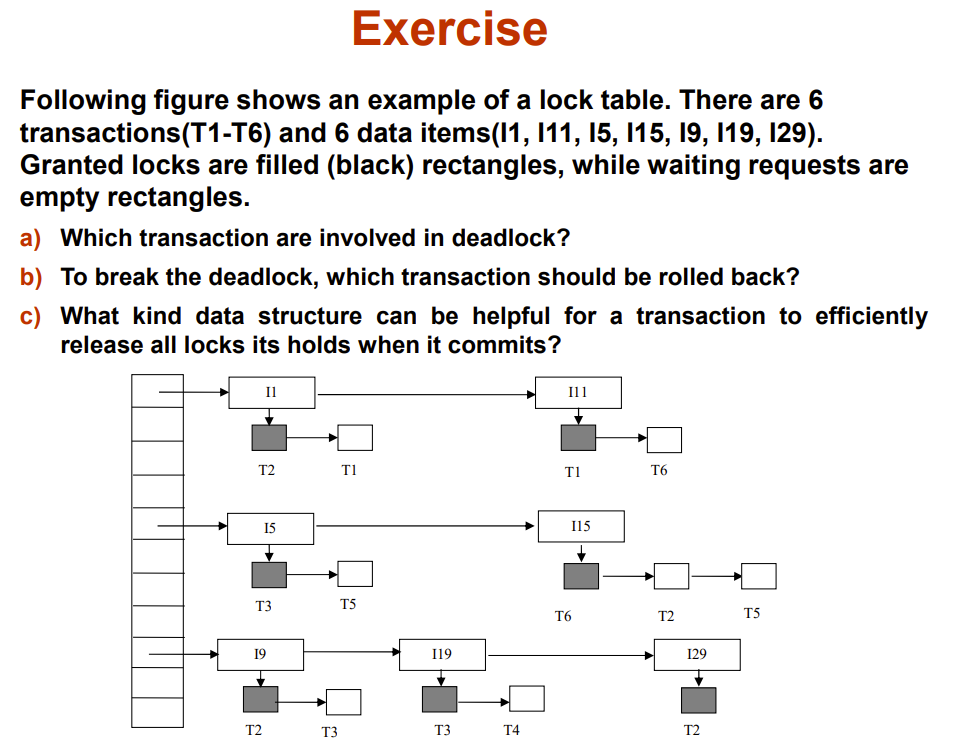
Graph-Based Protocols
Graph-based protocols are an alternative to two-phase locking
还是锁协议的一种哈,要用的锁的,和两阶段锁协议一个级别
下面这个是 database graph,结点为数据
有向边表示有事务需要访问边两端的结点,而且有先后顺序,先访问指向后访问
如果没有环,然后就能设计出很好的协议,下面我们讲基于特殊的database graph设计的协议
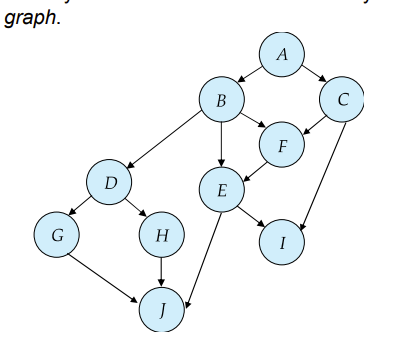
Tree Protocol
database graph是树的情况,即只有一个根
- 该协议只有exclusive locks ,没有S锁
- 对于一个事务来说,first lock 可以放在任意 data item 上
- 后续如果要加锁,数据的父节点必须有锁,否则该数据不能加锁
- 任意锁可在任意时间解锁
- 对于一个事务,每个数据只能锁一次,unlock之后不能再lock了
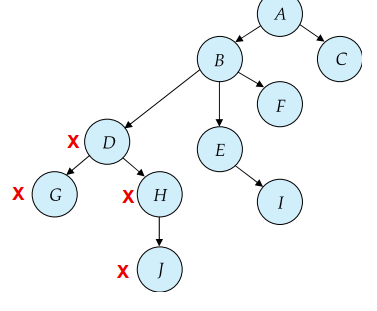
The tree protocol ensures conflict serializability as well as freedom from deadlock
- Advantages
- Unlocking may occur earlier than two-phase locking protocol, shorter waiting times, increase in concurrency
- Disadvantages
- not guarantee recoverability or cascade freedom
- may lock more data items than needed
- 父节点不一定是需要的数据
Multiple Granularity(多粒度)
把每种数据看成一个颗粒,有些粗有些细,以此分为不同等级(hierarchy of data granularities),一个等级即一个粒度
最大最粗的颗粒就是数据库本身,小的颗粒比如一张表,最小最细的颗粒就是一个数值/字符串之类的record
我们之前锁的对象好像都局限于最小的颗粒,实际上锁可以加在任意需要的颗粒上,比如锁一张表,锁一个B+树
锁的对象是信息
- Granularity of locking (level in tree where locking is done):
- fine granularity(细粒度)
- lower in tree
- high concurrency, high locking overhead
- coarse granularity(粗粒度)
- higher in tree
- low locking overhead, low concurrency
- fine granularity(细粒度)
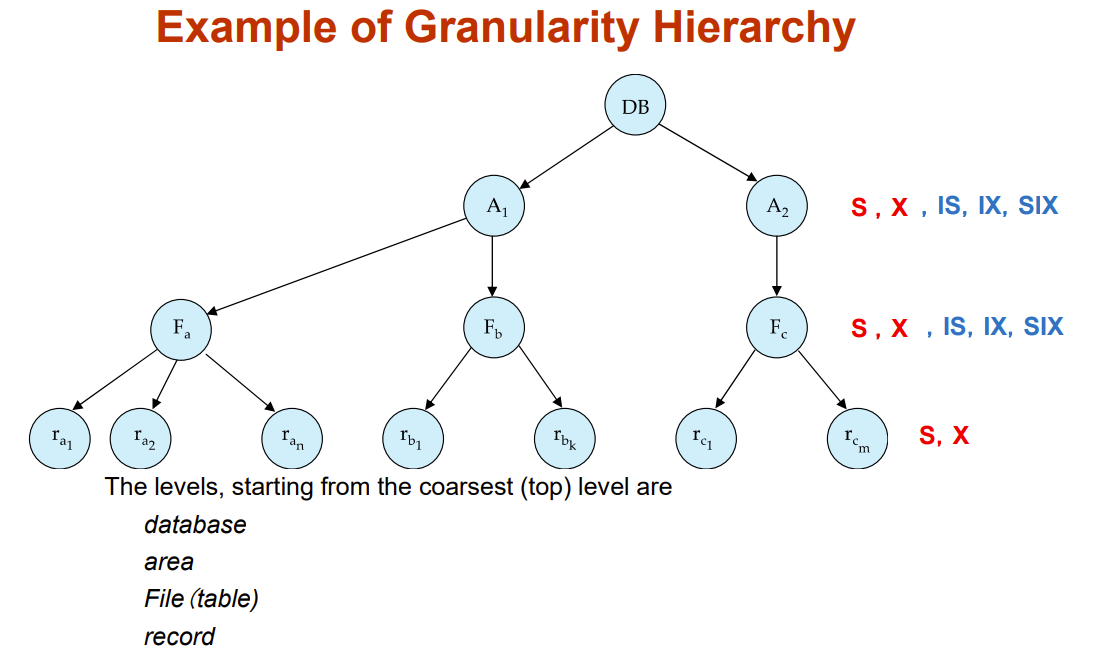
注意到上图除了S、X锁多了三种新锁,用于快速判断一个数据能否加锁
下面三个新锁对于基粒(最小的颗粒)不作用
- intention-shared (IS)
- indicates explicit locking at a lower level of the tree but only with shared locks.
- 一个事务意向给基粒加S锁,就给其所有祖父结点加IS锁,表有事务有意向访问该节点里面的一个数据并给其加S锁
- intention-exclusive (IX)
- indicates explicit locking at a lower level with exclusive or shared locks
- 同IS,不过既可以加S也可以加X
- shared and intention-exclusive (SIX)
- the subtree rooted by that node is locked explicitly in shared mode and explicit locking is being done at a lower level with exclusive-mode locks.
- 表示里面的颗粒不需要加S锁也可以读,但是写还是要X锁
下面是相容性矩阵
Compatibility Matrix with Intention Lock Modes
compatible是可相容的
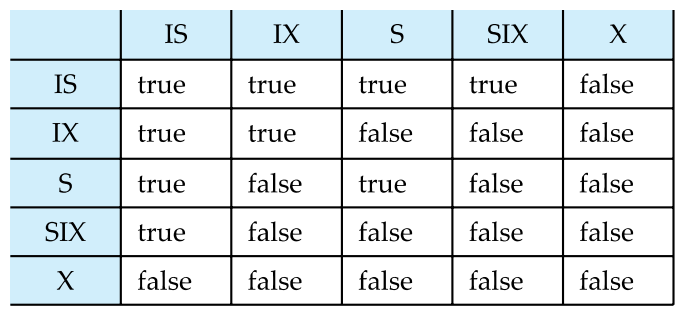
意向都是相容的,冲突反映在真正的lock上
Multiple Granularity Locking Scheme
要求事务遵循两阶段锁协议
Transaction Ti can lock a node Q, using the following rules:
- The lock compatibility matrix must be observed.
- 严格遵循相容矩阵
- The root of the tree must be locked first, and may be locked in any mode.
- 根需要第一个被锁,随便选一种锁就行
- Q can be locked by Ti in S or IS mode only if the parent of Q is currently locked by Ti in either IX or IS mode.
- IX/IS -> S/IS
- Q can be locked by Ti in X, SIX, or IX mode only if the parent of Q is currently locked by Ti in either IX or SIX mode
- IX/SIX -> X/SIX/IX
- Ti can lock a node only if it has not previously unlocked any node (that is, Ti is two-phase).
- 要求事务遵循两阶段锁协议
- Ti can unlock a node Q only if none of the children of Q are currently locked by Ti .
- 要求从下往上依次解锁,不能跳跃
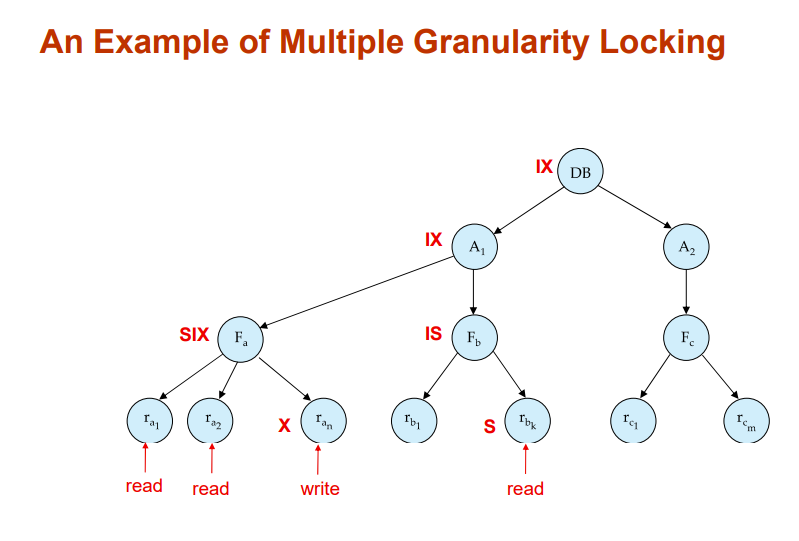
加锁从上往下
解锁从下往上
Insert and Delete Operations
- 如果是two-phase locking
- delete就往要删的tuple加X锁
- insert就往刚插入的tuple加一个X锁
- 我们需要保证的是
- reads/writes conflict with deletes
- Inserted tuple is not accessible by other transactions until the transaction that inserts the tuple commits
Handling Phantoms
Insertions and deletions can lead to the phantom phenomenon.
往tuple加锁不能解决这个问题,可以直接锁住整个表,但是太暴力了
我们可以用索引等方式高效解决
Index Locking Protocol To Prevent Phantoms
思路是,通过索引S锁住所有与要读的数据集有相同key的数据,防止要读取的数据集被插入新数据
这种协议叫 Index locking protocol
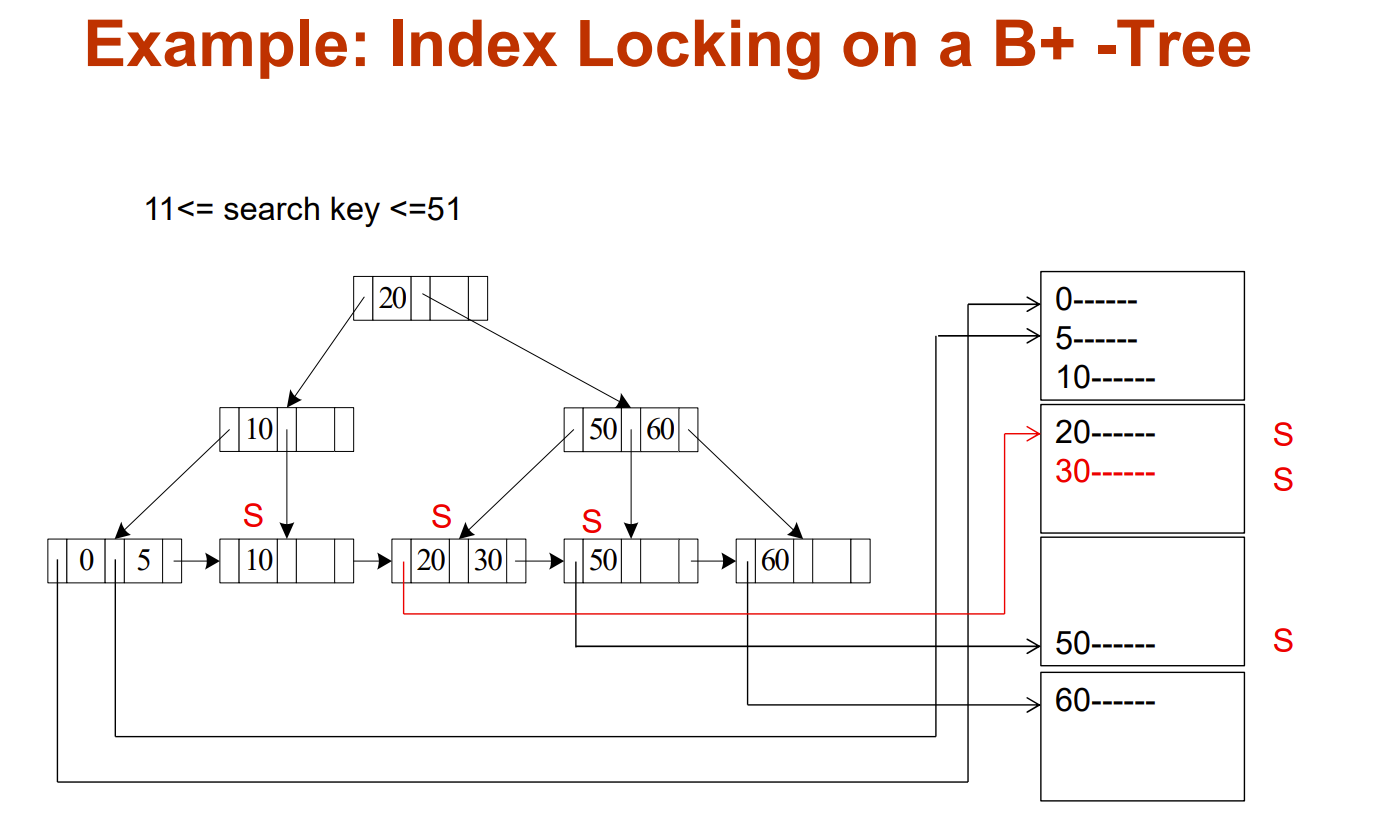
Next-Key Locking To Prevent Phantoms

Multiversion Concurrency Control Schemes(MVCC)
之前都是单版本并发控制,一个信息只有一份,修改只能覆盖原来的
我们可以多版本,修改后产生新版本,而不是进行覆盖
也是两阶段锁协议
When a read(Q) operation is issued, select an appropriate version of Q based on the timestamp of the transaction, and return the value of the selected version.
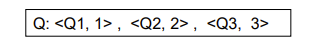
Q1, Q2,...是数据,右边的数字是时间戳,反映新旧程度,越大表示越新
一个数据有多个版本,这些版本共同组成一个整体,锁只能加在这个整体上
访问数据也是访问这个整体,然后才选择要哪个版本
这个协议需要先声明一个事务是 read-only transactions 还是 update transactions,即只读和允许编辑
- 读是读最新的版本
- 写会创建新的版本
具体加锁操作见下图,还没看

写需要先申请S锁,然后读最新版本的数据
然后复制最新的数据,时间戳设置为无穷大,这样不可能被读取,用于表示尚未提交
修改好后计数器+1,更新新版本的时间锉,最后才开始解锁
这时严厉的两阶段
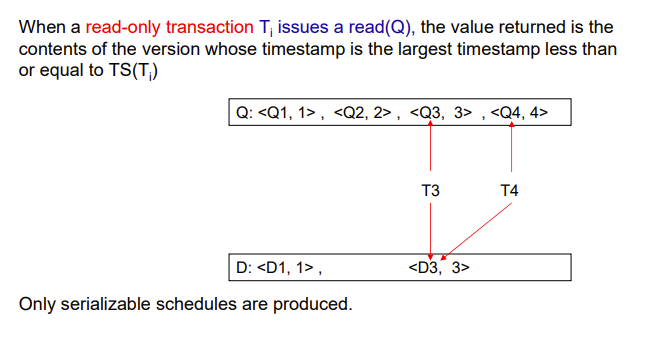
只读不用加锁,肯定能
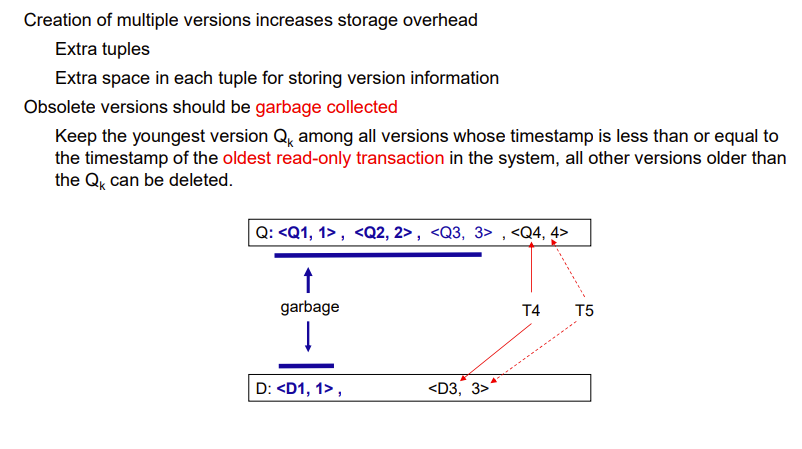
可以对老旧版本进行回收
MVCC在工业界非常常用,非常主流,不要工作才发现自己不懂