Lecture 15 | Recovery System
灰灰,sjl老师,有幸与您相遇,谢谢您
数据库系统2024-06-03第6-8节 (zju.edu.cn)
Basic
Failure Classification
数据库系统可能出现的故障
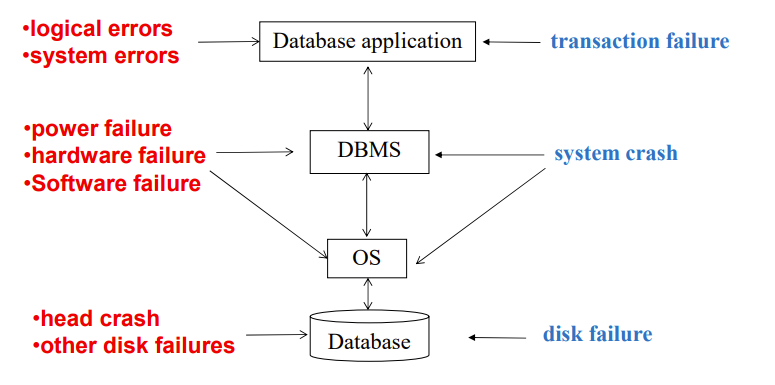
- 发生在数据库应用里的是事务故障出现在单个事务里,比较局部,一般直接rollback
- 具体的实现会准备一个日志,记录所有会影响数据库的操作,比如
uodate等,rollback 时就根据这个日志去恢复
- 具体的实现会准备一个日志,记录所有会影响数据库的操作,比如
- DBMS和OS的故障就是系统崩溃,是全局性的,一堆事务都会受影响,也需要日志去恢复
- 比如死锁需要牺牲一个事务,我们称这个被牺牲的事务发生了系统故障,这不是他自己的问题;还有突然断电也是系统故障
- Database的故障就是磁盘故障,解决思路就是多备份,还是得借用日记去恢复
- Transaction failure
- Logical errors: due to some internal error condition
- System errors: the database system must terminate an active transaction due to an error condition (e.g., deadlock)
- System crash
- a power failure or other hardware or software failure causes the system to crash.
- Disk failure
Storage Structure
- Volatile storage
- not survive system crashes, like main memory, cache memory
- Nonvolatile storage
- survives system crashes, like disk, tape, flash memory
- Stable storage
- 理想化的存储结构,100%不会出问题,只存在于理论中
Stable-Storage Implementation
尽可能接近的实现思路是一份数据copy多份,分别存放在多个disk,分别维护
Database Recovery
恢复算法要保证数据库的一致性,以及事务在发生错误时的原子性和持久性
- Recovery algorithms 有两个部分
- normal transaction processing 期间收集用于恢复的信息
- recover
我们这节课举的例子都是 strict two-phase locking, ensures no dirty read
恢复算法有 Idempotent(幂等性),即不管恢复多少次都是一样出的结果,特别是恢复时出了故障还是能正常恢复的
Log-Based Recovery
log
log 存储在 stable storage(稳定存储器),是一个序列/线性文件,包含的元素是 log records,记录各种会影响数据库的操作信息,特别是 update
- 一个事务 \(T_i\) 开始时,log会记录
<Ti start>Ti是这个事务的 id,每个事务的标识符
- 执行
write(X)操作前,日志会先记录<Ti, X, V1, V2>V1是旧数据(old value),V2是新数据(new value)
- 事务完成最后一个statement后,记录
<Ti commit> - 事务要 rollback ,记录
<Ti abort>
Log File Example
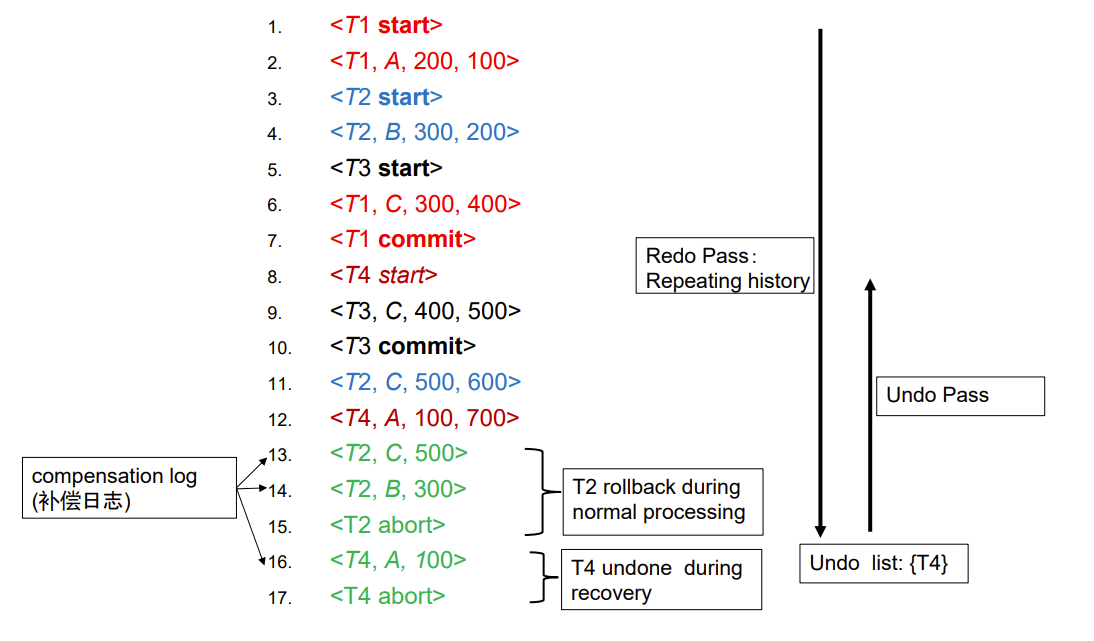
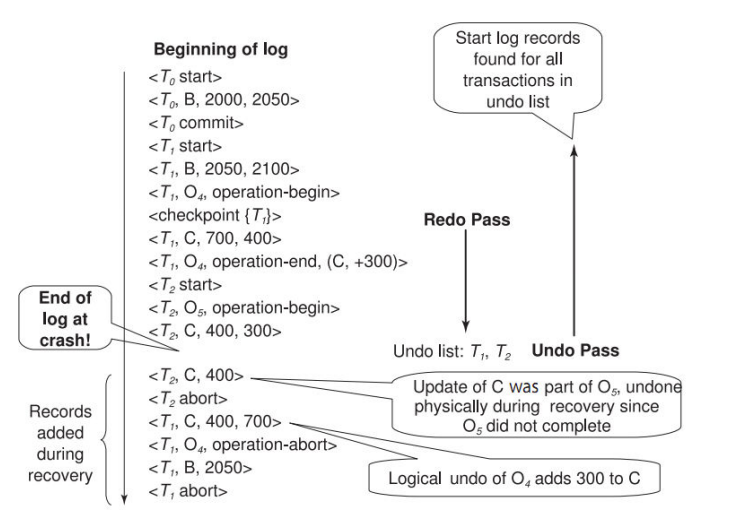
前12行是正常的日志,后面绿色的部分叫补偿日志,记录的恢复所进行的操作,13~15行是T2发起rollback的恢复操作,16 ~ 17行是crash后undo的恢复操作记录
如果发生了 System crash 之类的严重情况,我们恢复的第一步是恢复现场(redo pass),就是把log文件里记录的操作全部重做一遍,包括补偿日志,这也叫 repeating history(重复历史)
我们会顺便检查所有事务,没有 commit 的或没有 abort 的事务就放进 undo list,这些是执行到一半被中断的事务(这个图里面的16~17行是后面加的,此时只有前15行,所以T4在list里面)
第二步是 undo pass,就是撤销 undo list 的事务已经执行的操作,注意 undo pass 的恢复操作也要进行补偿日志,即16~17行
Write-Ahead Logging or WAL(先写日志原则): 日志文件应该先于output写出主存,免得中间出问题后无法恢复
还有一件事,事务commit结束的标志是其对应的log commit记录写入了stable storage
Checkpoints
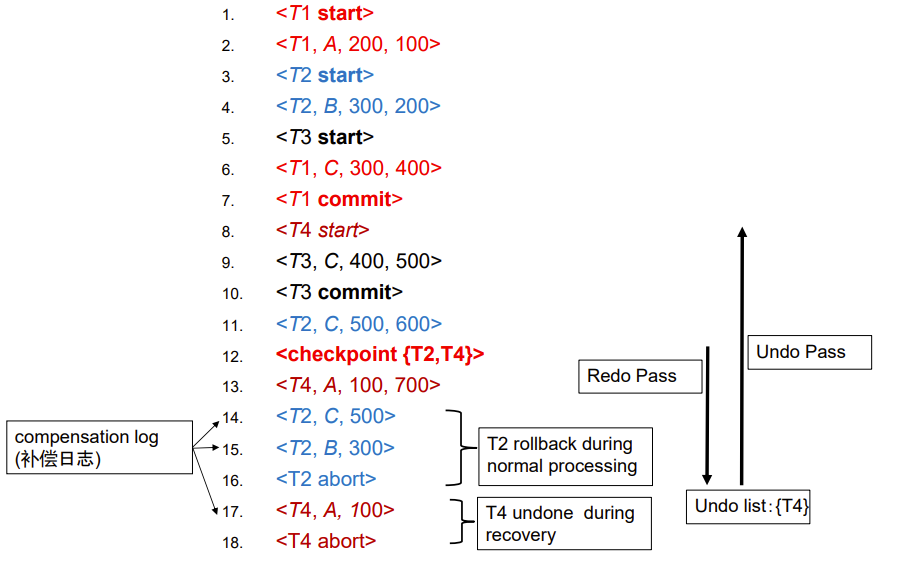
显然从头开始用日志恢复现场太恐怖了,我们尝试减少恢复量
系统每一段时间设置一个检查点,设置检查点的操作如下:
- 先让目前所有还在主存的日志都写出去
- 再让所有目前主存里已修改的block写出去,保证前面的操作已经全部写入了数据库
- 日志记录
<checkpoint L>,L 是此时正在运行的事务表,包含所有正在进行的事务
日志文件也是一块一块写出去的,有个专门的buffer
这样恢复现场时就只需要从最近的检查点开始,而不是从日志文件的头开始
注意,设置检查点时会中断所有的 update 操作
Log File with Checkpoint : Example
Log Buffer & Database Buffer

log buffer 的块在满了的时候或事务commit的时候会写出
显然 log buffer 一个块可能包含多个事务的日志,这叫 group commit,可以减少I/O操作次数
Fuzzy Checkpointing
模糊的检查点,只刷日志不刷脏数据,但是会记录哪些block是脏的,以此减少检查点操作造成的stall
在这个模式下,会多一个指向检查点的指针,记录 last_checkpoint 的位置,即最后一个已完成的检查点的位置
等一个检查点所有被记录的脏数据都被写出去了,last_checkpoint 就会指向这个检查点
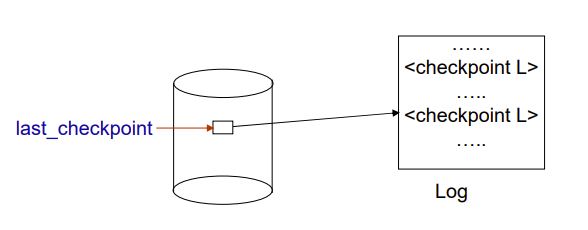
恢复历史时也是从 last_checkpoint 指向的检查点开始
Recovery with Early Lock Release and Logical Undo
即不是严格两阶段锁协议的情况
我们之前的 undo 是物理的,就是直接改回旧数据,而 logical Undo 是,如果你加了300,那么我就减 300,而不是直接用旧数据
和锁的关系和旧数据太旧了这两个点我还不明白,需要看下PPT
Operation Logging
我们将操作看成事务,也记录start和end,但是这里的 log record是用反的逻辑undo记录的,看下面例子
Transaction Rollback with Logical Undo
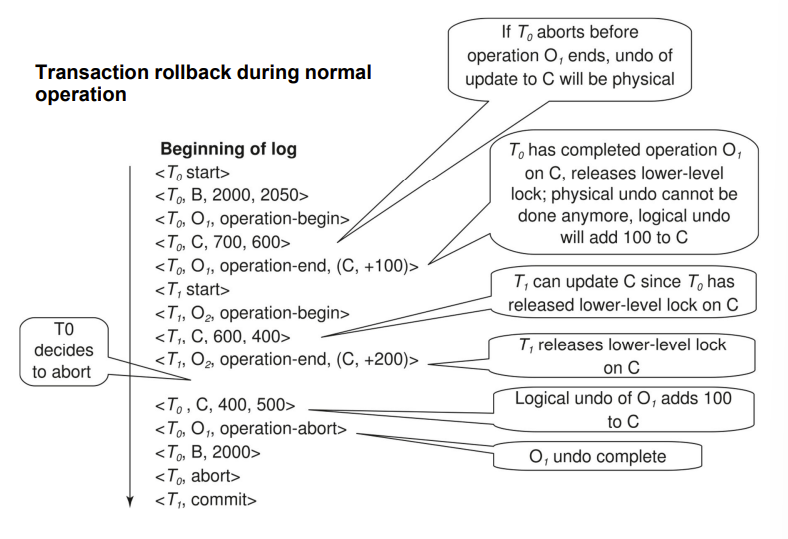
Failure Recovery with Logical Undo
还没end就crash的操作还是只能用物理undo实现
ARIES Recovery Algorithm
ARIES is a state of the art recovery method ,即目前工业界最先进的算法
数据结构
ARIES 使用到的数据结构包括:
- 每个日志record都有一个严格单增的 Log sequence number (LSN) ,类似id
- 每个数据页(等同于 block)都有 Page LSN,记录该 page 相关的最新日志 record
- 可以避免恢复时重复redo,提高 idempotence
- DirtyPageTable
- 一张表,记录当前 buffer 里有哪些 block 是脏的
- 会和 当前事务表(Active TXN Table)一起写进检查点

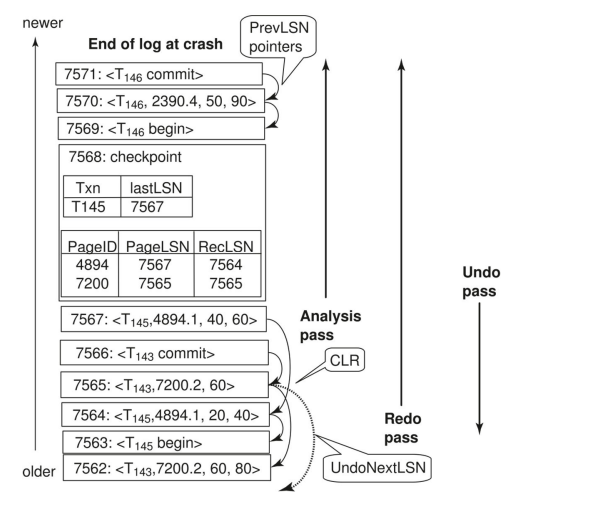
分别解读上面这张图:
- 左下角就是数据库,里面我们假设有四个 page
P1 17表示 \(P1\) 这个 page 已经被写入 \(LSN=17\) 对应的操作需要写的数据
- 右边的大表就是 \(log\; file\),同一个颜色对应同一个事务
- \(PrevLSN\) 指向同一事务上一个record
- \(TNO\) 就是事务的 id
- \(TYPE\) 指示该record 对应的操作类型,
u就是update - \(PID\) 指示操作的页,\(len\) 和 \(offset\) 共同指示要修改的数据段在 page 什么地方
- \(before\) 和 \(after\) 意义显然
- 23~24行是 checkpoint 记录
- 左边的 \(Active\; TXN\; Table\) 即当前事务表
- 记录目前的活跃的事务中最新的已执行的操作
- 上面的 \(Buffer \;Pool\) 即缓冲,存放还没被写入数据库的脏数据
- 对应的数字就是已经执行好的操作
- 左上角的 \(Dirty\; Page\; Table\) 记录脏数据,已经这个脏数据哪些操作造成的修改还没被写入数据库
- \(PageLSN\) 记录最新的已执行操作,\(RecLSN\) 记录最远的还没写入数据库的操作
- 比如,我们只关注page \(P1\),其相关的操作共有 \(LSN=15,17,20,22\) 四个,15和17已经写入数据库了,20和22还没写入,还滞留在缓冲里,可能会丢失
下面是增加3条指令各表的变化,如果突然断电了,三个爆炸表示这些数据没了
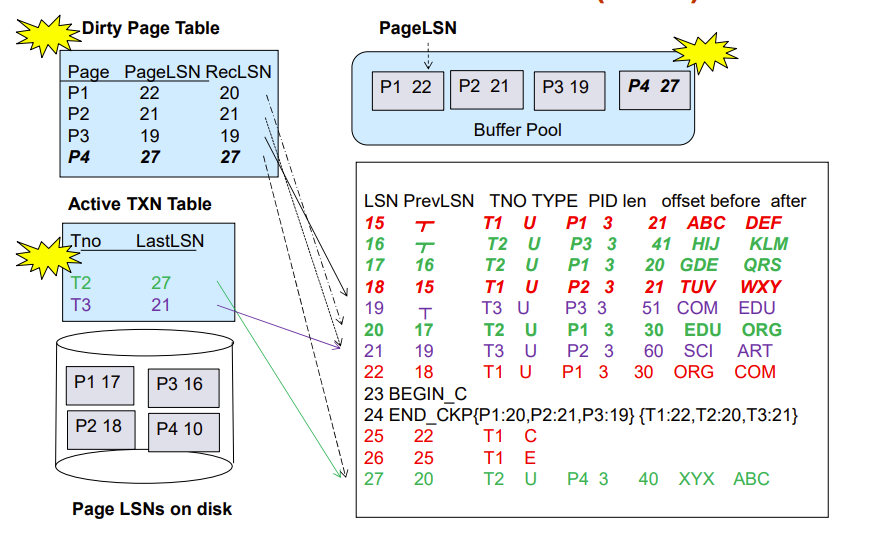
Aries Recovery: 3 Passes
Analysis, redo and undo passes
相比前面,Aries多了个分析阶段
Undo has to go back till start of earliest incomplete transaction
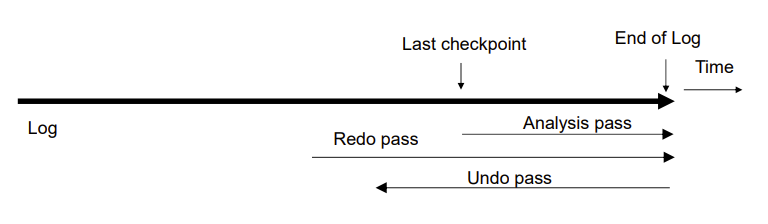
Analysis pass
这个 pass 会分析 redo 该从哪开始,因为Aries没保证检查点前面的操作都写进数据库了
算法如下:

redo 的起点记为 RedoLSN
脏页表记录的就是还没写入数据库的操作,所以直接取里面最早的操作作为 RedoLSN 即可
如果脏页表是空的,显然取检查点为 RedoLSN 即可
??????????????????
检查点里面有的事务的最后一条指令都先放入 undo-list,然后从检查点开始一条条往前找:
没有在 undo-list 的 record 就放进去
如果是
update的 record,?????????????????????????

redo pass
redo会检查要不要redo,如果不在脏页表里的 page 就跳过,或者 record LSN小于脏页表的 RecLSN 也跳过
????????????????????????

Undo Pass

Recovery Actions in ARIES