improve performance of Memory hierarchy
内存方面
DRAM
对于一个内存,如果每次读取都要输入行地址和列地址太慢了,我们需要更快的办法
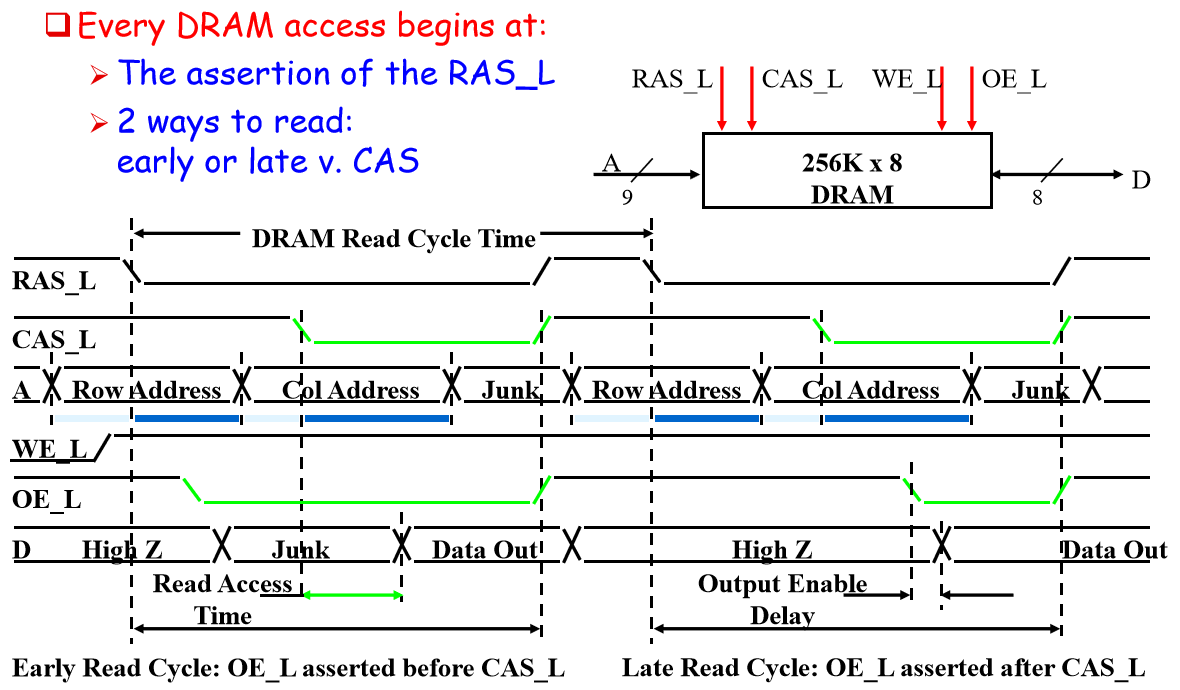
Fast Page Mode DRAM (FPM)
先输入一个行地址,如果紧跟的请求也是同一行的,就只输入列地址
在 FPM 中,row buffer 叫 page

cache bank
n association 即 n 路主关联,也就是一个 set 有 n 个 cache line
在实现上,会将一个 n 路 cache 分为 n 个一路 cache,相当于一个 cache 对应一路,然后用 mux 决定选哪个 data
这一个子 cache 就叫做 cache bank,记为 bank0,bank1,等等
缓存方面
AMAT = HitTime + MissRate x MissPenalty
- Reduce hit time
- Small and simple first-level caches
- Way prediction
- avoiding address translation
- Trace cache
- Increase bandwidth
- Pipelined caches
- multibanked caches
- non-blocking caches
- Reduce miss penalty
- multilevel caches
- read miss prior to writes
- Critical word first
- merging write buffers
- victim caches
- Reduce miss rate
- larger block size
- large cache size
- higher associativity
- Compiler optimizations
- Reduce miss penalty or miss rate via parallelization
- Hardware or compiler prefetching
Reduce hit time
Small and Simple Caches
Using small and Direct-mapped cache
shorter the critical path through the hardware
Direct-mapped is faster than set associative for both reads and writes
Way prediction
对于多路 cache,我们是从多个 bank 读取 data 再通过 mux 筛选,每个 bank 的读取功率一致
但是我们可以预测某个 bank 里的 data 就是我们想要的,就把大部分功率交给这个 bank,读出来 data 不经过 mux 直接用,如此减少 hit time
如果预测错了就有 penalty
Avoiding Address Translation during Indexing of the Cache
首先,我们之前讲过的 cache,都是使用物理地址而不是虚拟地址
CPU 发出的数据请求都是虚拟地址,需要借助页表转换为逻辑地址,然后才能访问 cache
但页表本来就是内存里面的很大一个数据结构,很慢
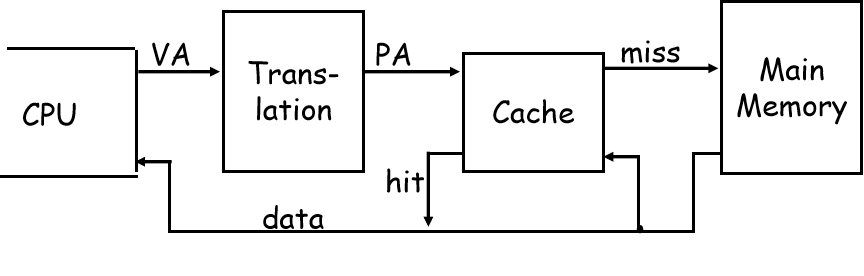
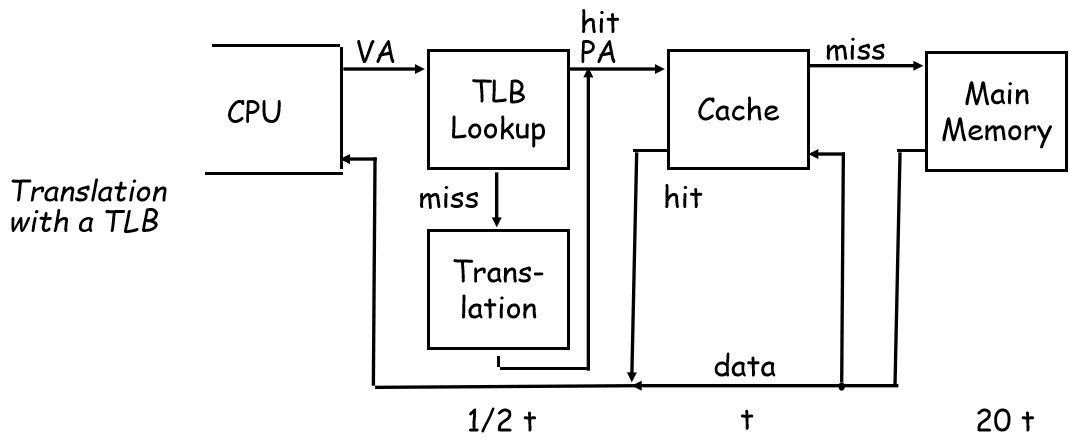
一种办法就是使用 TLB 来加快虚页号转为实页号

还可以尝试避免地址转换,我们有两种办法:
直接让 cache 使用虚拟地址,见下图第二个流程图
$ 是 cache
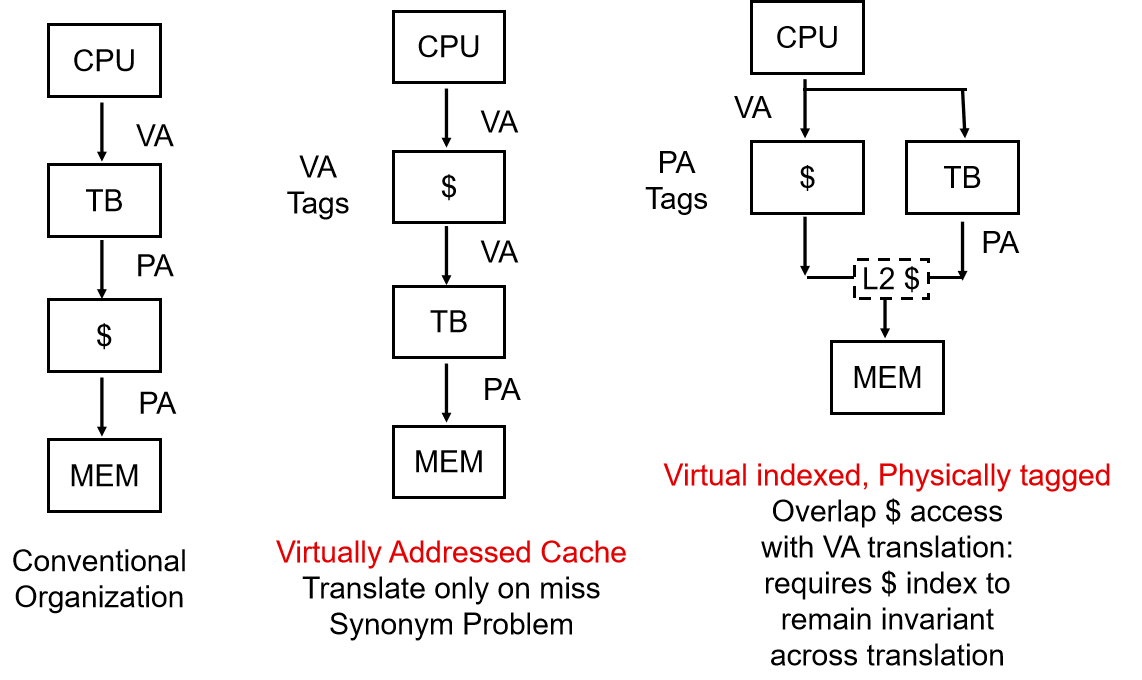
这有个问题——别名 alias,即两个虚拟地址指向了同一个物理地址,导致一个数据可能出现在 cache 的两个位置,如果分别进行了修改就会导致不一致
我们有个办法叫 page coloring,其要求两个互为别名的虚拟地址的 index + block offset 是一模一样的,只有 tag 不一样
????tag 呢,不是会出问题吗???
这是一种软件层面的办法,还有另一种更常用的硬件层面的办法
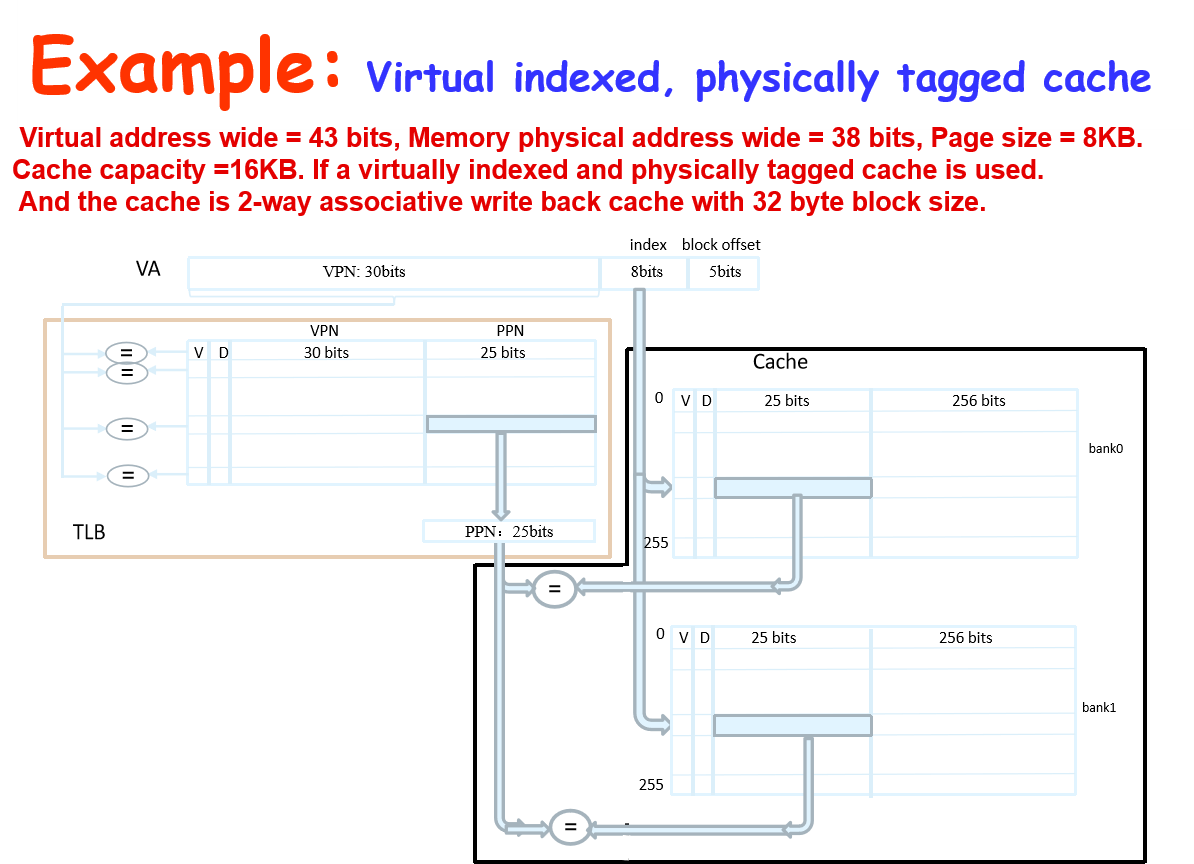
Virtual indexed, physically tagged
我们虚实地址转化实际上是虚页号的转化,具体而言就是除 page offset 之外的数据
我们可以设计 cache,让 index + block offset = page offset
这样在虚实页号转换的同时,并行地让 index 和 block offset 输入 cache 进行访问,等页号转换好了就正好是 tag,拿来做比对,搞定
如此通过并行缓解了因虚实地址转化导致的 hit time 增大
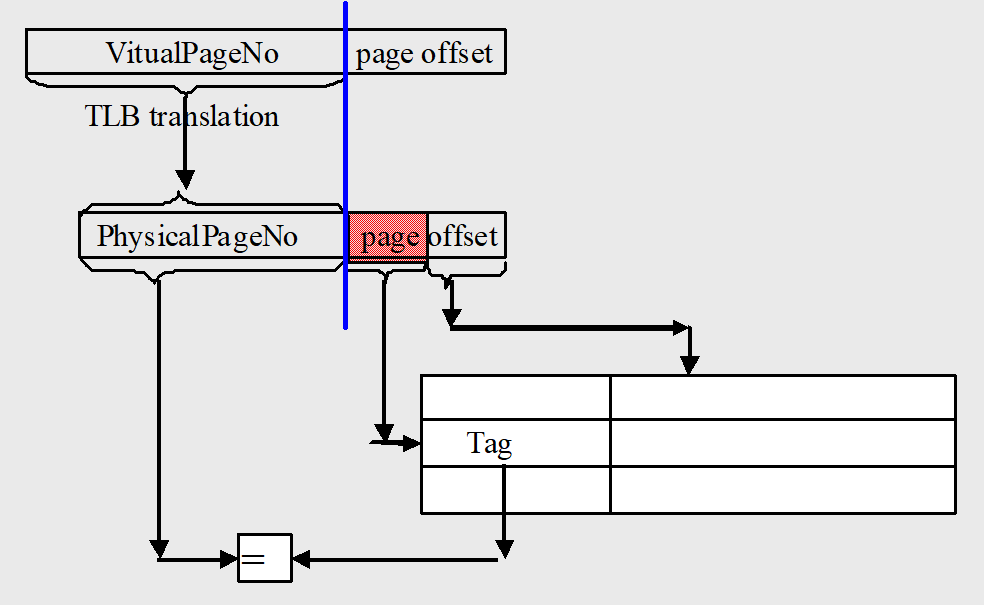
当然很显然,限制是 index + block offset = page offset,cache 大小因此被限制
cache size = \(2^{block\;offset} \times 2^{index}\)
增加 cache 关联、增加 page offset 都能缓解这个限制
Trace caches
主要用于 inst cache
inst 使用很连续,一条一条取就太难崩了,但是又有跳转指令,一坨一坨取静态代码块也有问题
Trace 就是一个动态指令流 dynamic instruction sequence,相当于程序的局部执行轨迹
具体实现流程不管,思路就是缓存逻辑上的指令流,例如跳转指令后面的不缓存,缓存跳转到指令
用到了跳转预测
Increase bandwidth
Pipelined Caches
cache 写操作是分地址识别和数据写入两部分,所以可以引入流水线的思路
Multibanked Caches
即多路 cache
Nonblocking Caches
这个是针对乱序多发流水线的,乱序流水线前后指令的数据依赖比较弱,所以可以 nonblocking
顺序即进入流水线的指令顺序与出来的顺序一致,乱序就是不一致
顺序流水线要求上一个指令用完了 cache,下一个指令才能用,所以叫 blocking cache
nonblocking 即允许一个 cache 被多个指令“同时”访问,确切说是 cache 在 access memory 的同时运行其它指令访问 cache
例如上一条指令需要访问内存,而下一条指令需要的数据就在 cache,这时下一条指令就会被 CPU 先指令,并不等上一条指令的数据从内存取回就先访问 cache 取出下一条指令的数据
Reduce miss penalty
Multilevel Caches
加一个 L2 用来兜底,别忘了 L1 的 miss penalty 是 L2 的取加权
由此多了两个概念,Local miss rate 和 Global miss rate
前者就是 cache 本身的 miss rate,后者是新概念,定义为缓存系统的未命中次数与 CPU 访问缓存次数的比值
就前者是这个组件的理论 miss rate,后者是实际的,L1还是它自己,但对于 L2 有变化,因为 L1 miss 了才到 L2 上场
- 对于 L1 Cache 来说,Global Miss Rate 就是它自身的 Miss Rate
- 对于 L2 Cache 来说,Global Miss Rate 是 L1 的 Miss Rate 和 自身的 Miss Rate 的乘积
Giving Priority to Read Misses over Writes
写很费时费力,那就把要写的脏块丢进 write buffer 专门写,让 cache 继续 read
不过要注意 read 的块是不是 write buffer 还没消化完的
Critical Word First & Early Restart
cache 每次 miss 后都是先定位到数据所在的 word,然后从内存拿这个 word 所在的一整个 block 过来,block 整个写进 cache 后 CPU 才能读取里面的 word
那么我们为什么不在内存找到数据所在的 word 时直接先把这个 word 直接传入 CPU,再 让block 慢慢写入 cache
这就是 Critical Word Firstq
但是有没有一种可能,我下一条指令正好也在这个 block,这下只能等了
还有一个办法,block 是按 word 顺序一个个写入 cache的,那么我们就每读入一个 word 就看是不是指令需要的,是就立刻取走,就有概率解决上面说的问题
这就是 Early Restart
Merging write Buffer
write Buffer 加强版
因为我们 cache I/O 的单位都是一整个 block,包括 write buffer,而我们修改可能就只修改了一个 word
如果前后修改了同一个 block 的两个 word,会导致 write buffer 出现同一个 block,只是不同修改,这样会浪费 write buffer 的空间
merging write buffer 就实现了合并,即同一个 block 的不同修改在 write Buffer 里都合并到这一个 block 里
Victim Caches
Victim Caches 是一个全关联小 cache,用于接受被主 cache 踢出来(替换)的数据,每次访问 cache 顺便在 Victim Cache 里看眼
Reduce miss rate
Larger Block Size(cache size fixed)
Larger blocks decrease the compulsory miss rate by taking advantage of spatial locality.
利用空间局限性,减少冷启动时间,但 hit time 增大
同时 block 数量减少,时间局限性影响减弱
Higher Associativity
直接加他一万个路(x
路多了就不容易冲突,但功率有限,平均之后 hit time 就增大了
Compiler Optimizations
不需要改任何硬件,让编译器优化指令的顺序,增强空间局限性和时间局限性
Way Prediction and Pseudo-Associative Cache
???
伪关联
我们的直接映像 hit time 小,但容易冲突,能不能两全其美
如果一个 index 冲突了,我们就让 index 的最高位取反,得到了

但是可能到后面大部分的都跑伪 cache 了,我们就需要 way 预测,预测是 hit 还是 pseudo hit
Reduce miss penalty or miss rate via parallelization
Prefetching of Inst.and data
预取,一种办法是硬件预取,比如取了某 block 就把附近的一起取了
还可以编译器动态预取一下