Multiple-issue----SuperScalar & VLIW
:material-circle-edit-outline: 约 530 个字 :material-clock-time-two-outline: 预计阅读时间 2 分钟
PPT 智云课堂 26 Superscalar 和 VLIW:如何让 CPU 的吞吐率超过 1?
[!ABSTRACT]
我们希望进一步改进处理器的性能,但目前的框架下,似乎 IPC 只能到 1
我们可以超越现有的框架
超标量 Superscalar
增加 decoder 数量,一次 fetch 多个指令,同时把多条指令发射(Issue)到不同的译码器或者后续处理的流水线中去,保证所有 FU 始终 busy
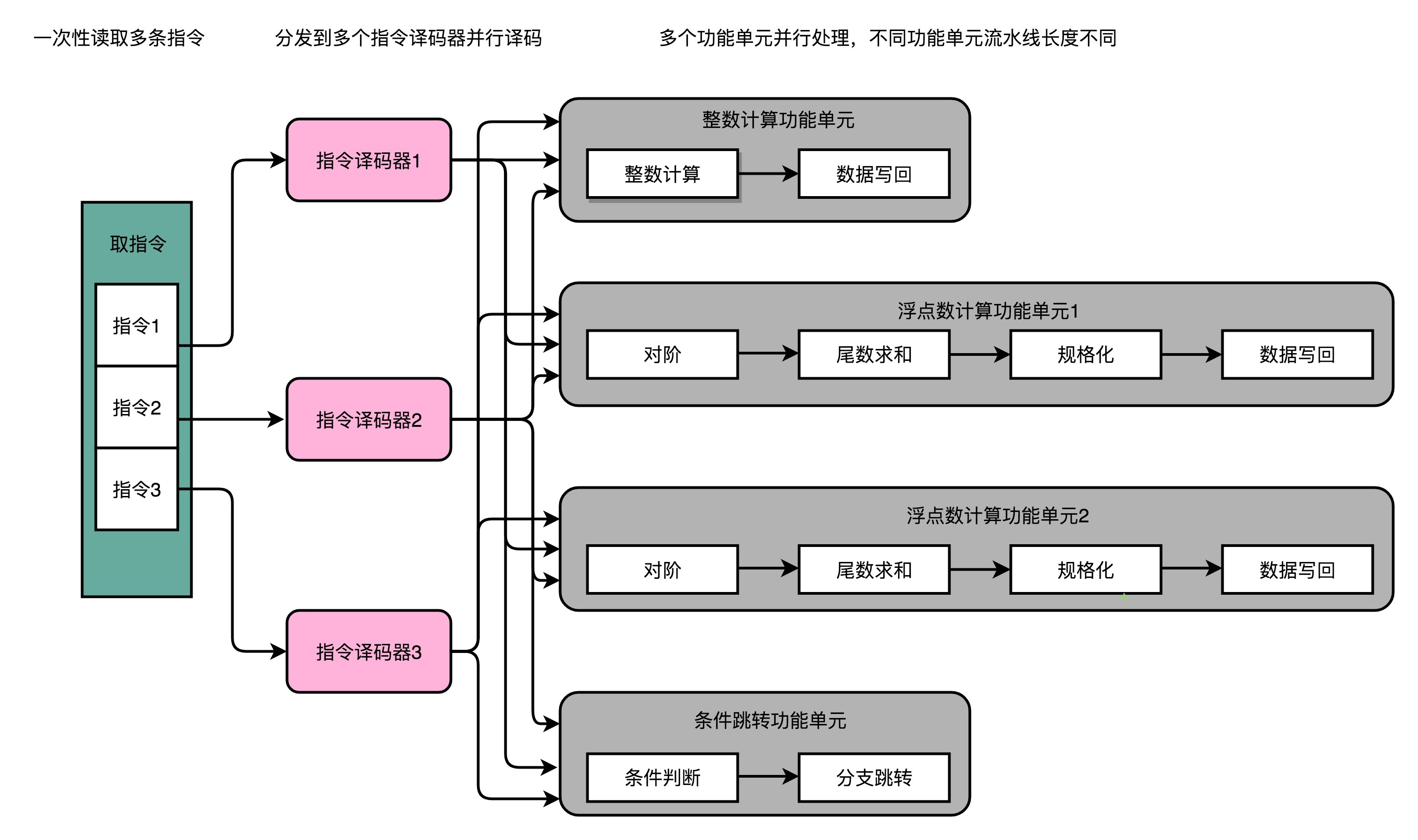
CPU 需要在指令执行之前,判断指令之间是否有依赖关系,如果有就不能分发到执行阶段
依赖关系的识别分静态和动态
- Statically Scheduled Superscalar
- Dynamically Scheduled Superscalar
超标量 CPU 又被称为 动态多发射处理器,依赖关系的检测使得 CPU 电路变得十分复杂
我们能不能不把分析和解决依赖关系的事情,放到软件里面来干呢
超长指令字设计 Very Long Instruction Word(VLIW)
程序的 CPU 执行时间 = 指令数 × CPI × Clock Cycle Time
我们可以通过改进编译器来优化 指令数 这个指标
在乱序执行和超标量的 CPU 架构里,指令的前后依赖关系,是由 CPU 内部的硬件电路来检测的,而到了超长指令字的架构里面,这个工作交给了编译器这个软件
- 我们可以让编译器把没有依赖关系的代码位置进行交换。然后,再把多条连续的指令打包成一个指令包(Group)
- CPU 在运行的时候,不再是取一条指令,而是取出一个指令包。然后译码解析整个指令包,解析出 N 条指令直接并行运行
下一组指令并不是等上一组指令执行完成之后再执行,而是在上一组指令的指令译码阶段,就开始取指令了
相当于原来是一个个指令进行流水,现在是一个个指令包进行流水
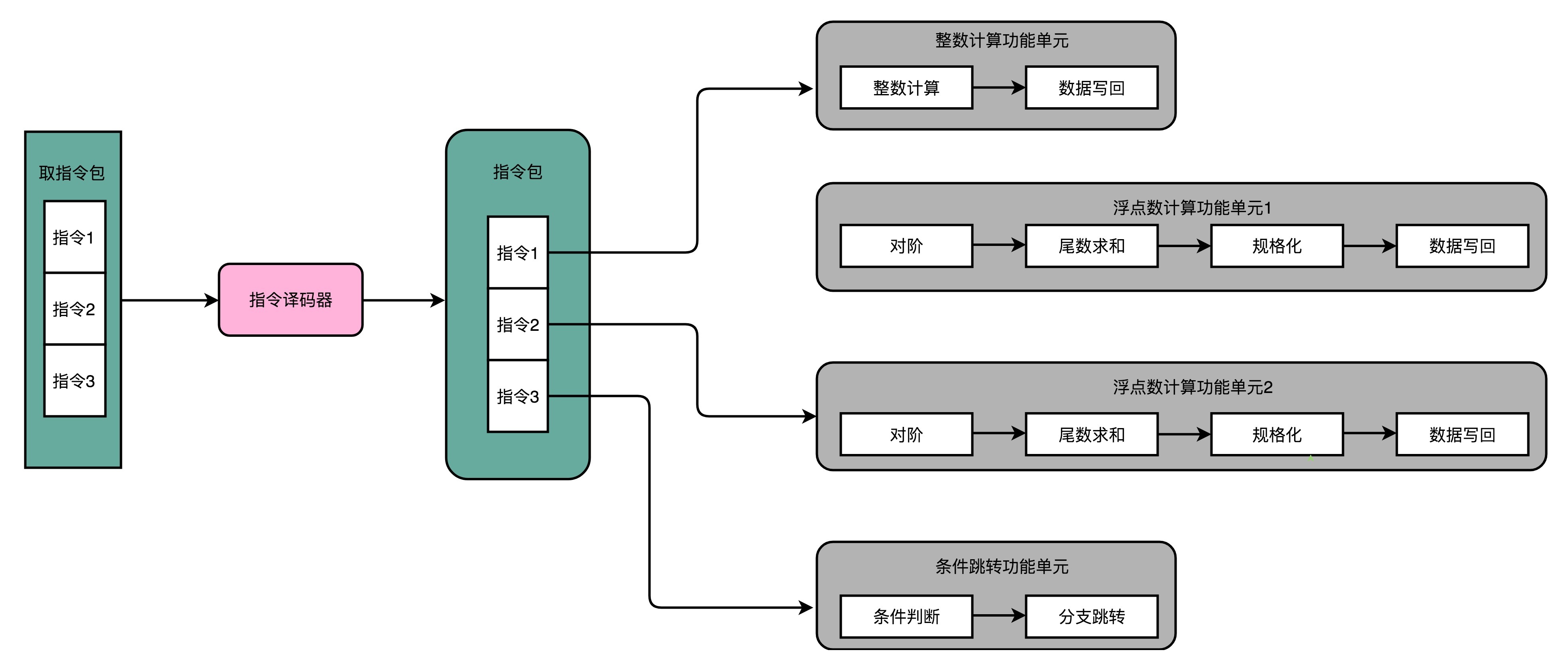
使用这项技术的一个处理器叫 Explicitly Parallel Instruction Computer,缩写 EPIC