Chapter5 Thread Level Parallelism
:material-circle-edit-outline: 约 673 个字 :material-clock-time-two-outline: 预计阅读时间 2 分钟
计算机体系结构(本)2024-12-02 第 3-5 节 PPT
Multiprocessors
Multiple processors working cooperatively on problems: not the same as multiprogramming
A parallel computer is a collection of processiong elements that cooperate and communicate to solve large problems fast.
不同处理器之间会进行通信与协作
Flynn Taxonomy
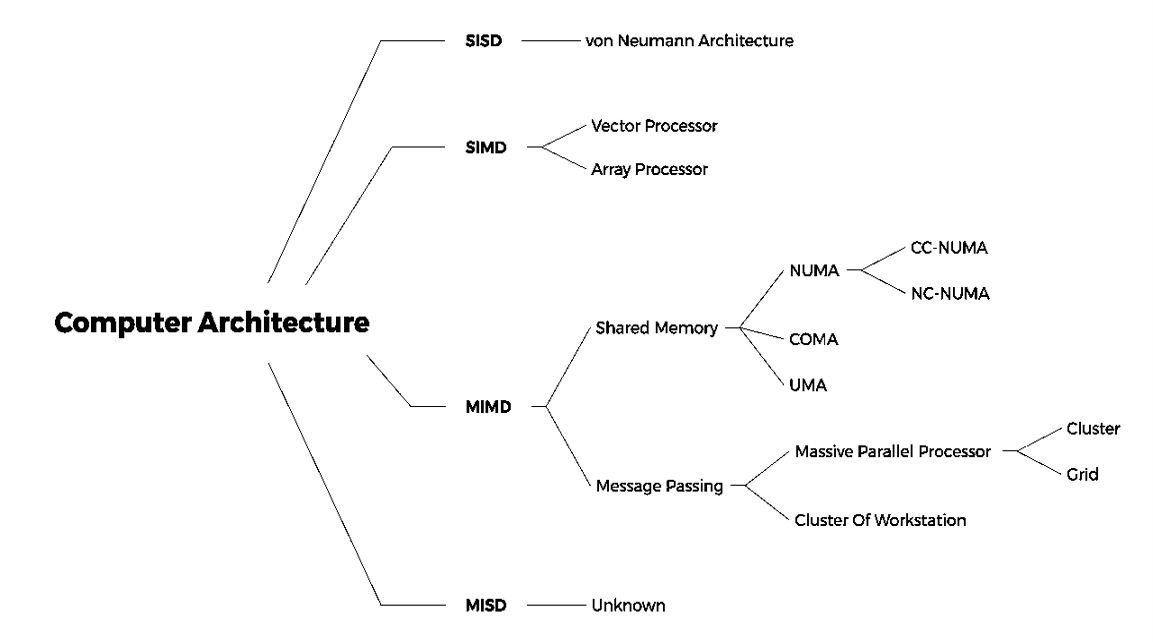
SISD (Single Instruction Single Data) - 单一处理器
MISD (Multiple Instruction Single Data)
SIMD (Single Instruction Multiple Data)
- Each “processor” works on its own data, but execute the same instr
MIMD (Multiple Instruction Multiple Data)
- Each processor executes its own instr. and operates on its own data
memory
多处理器架构下,memory 可以是 shared 也可以是 Distributed
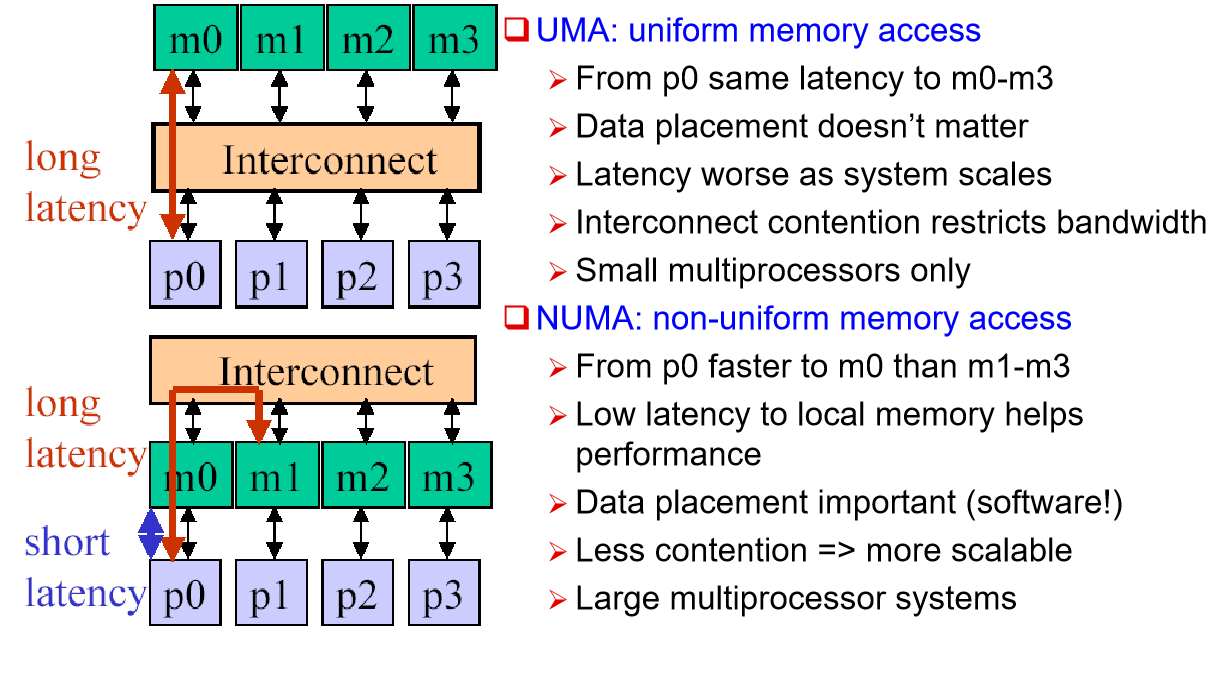
UMA: uniform memory access,指不同指令访问同一个地址的延迟一样
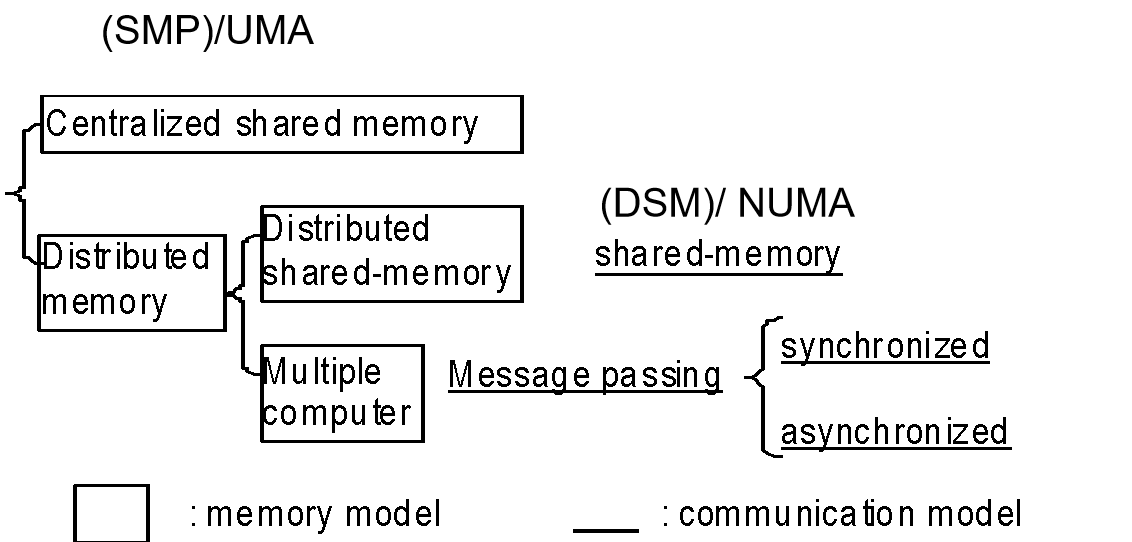
DSM: (physically) distributed, (logically) shared memory,是 NUMA
[!NOTE] UMA vs. NUMA
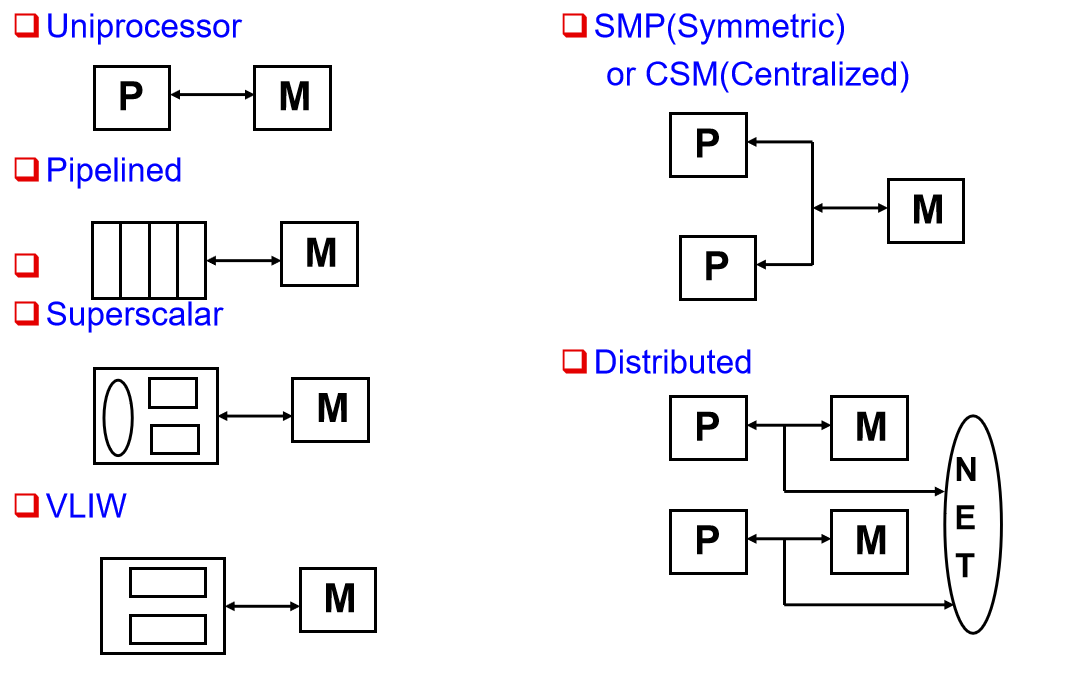
Major MIMD Styles
- Centralized shared memory multiprocessor
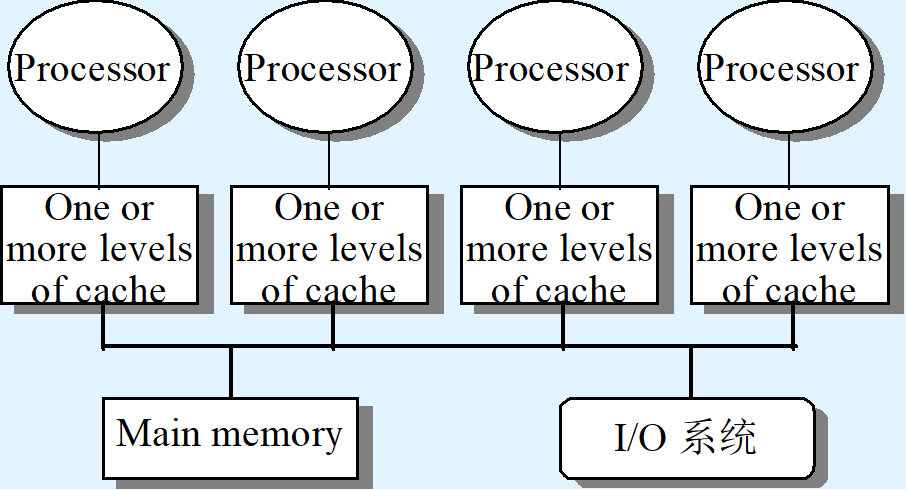
- Decentralized memory multiprocessor
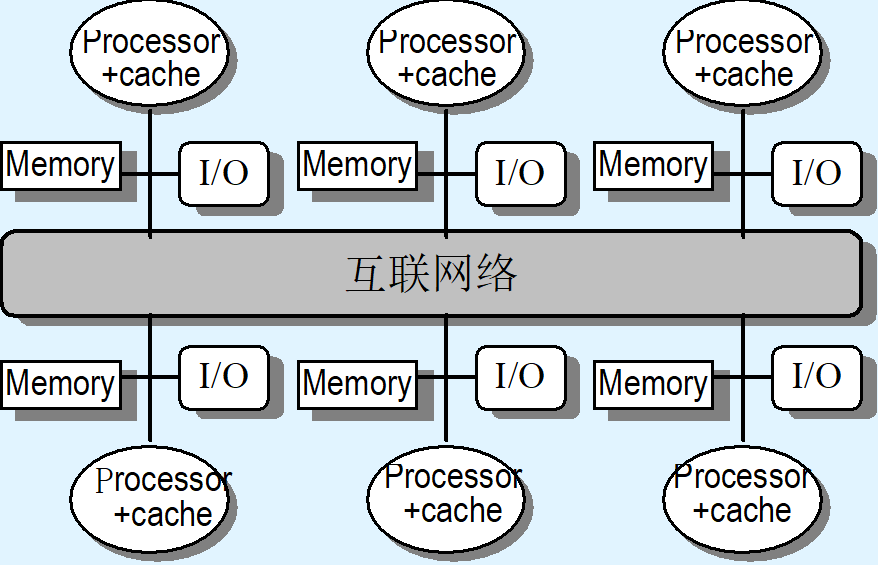
[!NOTE]
Parallel Framework
Parallel Architecture extends traditional computer architecture with a communication architecture
- Programming Model:
- Multiprogramming : lots of jobs, no communication
- Shared address space: communicate via memory
- Message passing: send and recieve messages
- Data Parallel: several agents operate on several data sets simultaneously and then exchange information globally and simultaneously (shared or message passing)
- Communication Abstraction:
- Shared address space: e.g., load, store, atomic swap
- Message passing: e.g., send, receive library calls
Shared Address Model-1
- Each processor can name every physical location in the machine
- Each process can name all data that shares with other processes
- Data transfer via load and store
- Data size: byte, word, ... or cache blocks
- Uses virtual memory to map virtual space to local or remote physical space
- Memory hierarchy model applies
Shared Address Model-2
- Significant research has been conducted to make the translation transparent and scalable for many node
- Handling data consistency and protection is typically a challenge
- For multi-computer systems, address mapping has to be performed by software modules, typically added as part of the operating system
- Latency depends on the underlined hardware architecture (bus bandwidth, memory access time and support for address translation)
- Scalability is limited given that the communication model is so tightly coupled with process address space*
Message Passing Model-1
- Whole computers (CPU, memory, I/O devices) communicate as explicit I/O operations
- Essentially NUMA but integrated at I/O devices vs. memory system
- Send specifies local buffer + receiving process on remote computer
- Receive specifies sending process on remote computer + local buffer to place data
- Usually send includes process tag and receive has rule on tag: match 1, match any
- Synch: when send completes, when buffer free, when request accepted, receive wait for send
- Send + receive => memory-memory copy, where each supplies local address, AND does pairwise sychronization!
Message Passing Model-2
- History of message passing:
- Network topology important because could only send to immediate neighbor
- Typically synchronous, blocking send & receive
- Later DMA with non-blocking sends, DMA for receive into buffer until processor does receive, and then data is transferred to local memory
- Later SW libraries to allow arbitrary communication
Shared Memory vs. Message Passing
- Shared Memory (multiprocessors)
- One shared address space
- Processors use conventional load/stores to access shared data
- Communication can be complex/dynamic
- Simpler programming model (compatible with uniprocessors)
- Hardware controlled caching is useful to reduce latency contention
- Has drawbacks
- Synchronization (discussed later)
- More complex hardware needed
- Message Passing (multicomputers)
- Each processor has its own address space
- Processors send and receive messages to and from each
- other
- Communication patterns explicit and precise
- Explicit messaging forces programmer to optimize this
- Used for scientific codes (explicit communication)
- Message passing systems: PVM, MPI, OpenMP
- Simple Hardware
- Difficult programming Model
Communication Models
- Shared Memory
- Processors communicate with shared address space
- Easy on small-scale machines
- Advantages:
- Model of choice for uniprocessors, small-scale MPs
- Ease of programming
- Lower latency
- Easier to use hardware controlled caching
- Message passing
- Processors have private memories, communicate via messages
- Advantages:
- Less hardware, easier to design
- Focuses attention on costly non-local operations
Fundamental Issues
PPT 29页