词法分析
输入:字符流;输出:抛弃空白符和注释后,生成一系列名字、关键字和标点符号
词法单词 | Lexical Tokens
FLOAT ID(match0) LPAREN CHAR STAR ID(s) RPAREN
LBRACE IF LPAREN BANG ID(strncmp) LPAREN ID(s)
COMMA STRING(0.0) COMMA NUM(3) RPAREN RPAREN
RETURN REAL(0.0) SEMI RBRACE EOF
Regular Expressions
称 language 是 string 的集合;string 是 symbol 的有限序列;symbol 是有限 alphabet 中的元素。
基本规则
每个正则表达式表示字符串的一个集合(i.e. language),即它可以匹配很多字符串:
- Symbol :
a, 匹配字符串 "a"。 - Alternation :
M和N是两个正则表达式,M|N可以匹配M和N匹配集合的并集。如a|b可以匹配字符串 "a" 或 "b"。 - Concatenation :
M和N是两个正则表达式,M·N可以匹配M和N中各一个字符串的联合。如(a|b)·a匹配字符串 "aa" 或 "ab"。 - Epsilon :
ϵ匹配空字符串。如(a·b)|ϵ代表 language {"", "ab"}。 - Repetition :
M是一个正则表达式,则M的 克林闭包 (Kleene closure) 为M*,如果一个字符串是由M中的字符串零至多次 concatenation 的结果,则该字符串属于M*。如((a|b)·a)*表示无穷集合 {"", "aa", "ba", "aaaa", "baaa", "aaba", "baba", "aaaaaa", ... }。
缩写形式
在书写正则表达式时,我们有时省略 · 和 ϵ ,并规定 * 优先级高于 · 高于 | 。还有一些缩写形式:
[abcd]表示(a|b|c|d)[b-gM-Qkr]表示[bcdefgMNOPQkr]M?表示(M|ϵ)M+表示(M·M*)
还有一些其他符号:
.表示除换行符外的所有单个字符"a.+*",引号中的字符串匹配其自身
Lex
Lex 和其他类似的词法分析器中规定了两条规则以消除二义性:
- Longest Match : 输入的字符串中的最长的能与任一正则表达式匹配的子串为匹配到的 token
- Rule Priority : 对匹配到的 longest substring,选择第一个与之匹配的正则表达式。即正则表达式的书写顺序是有意义的

FA

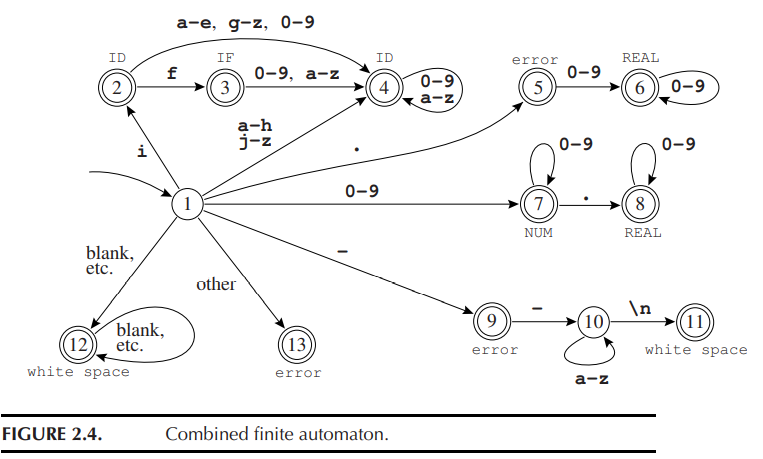
为了避免混淆,我们选择 Recognizing the longest match
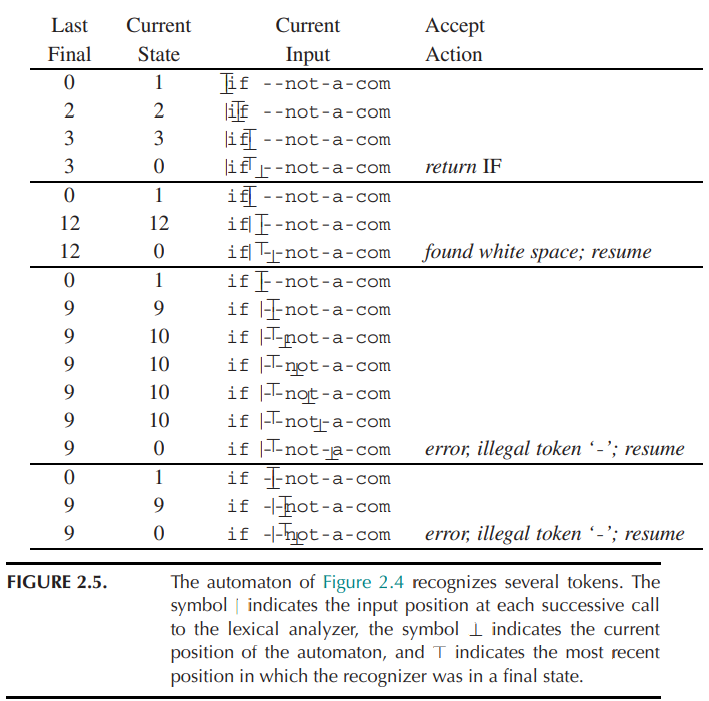
为了识别最长的匹配,词法分析器应当记录迄今遇到的最长匹配及该匹配的位置。
词法分析器使用变量 Last-Final 和 Input-Position-of-Last-Final 记录最近遇到的 final state 的编号和最后一次处于 final state 的时机。
每当进入一个终态时,词法分析器更新这两个变量;当到达 dead state 时,从这两个变量就可以得知其匹配的 token。例如:
NFA 转 DFA
记 \(M^\prime=(K^\prime,\Sigma ,\delta,s^\prime,F^\prime)\) 为 DFA,\(M=(K,\Sigma ,\Delta,s,F)\) 为 NFA,他们是等价的
则:
- \(K^\prime=2^K\)
- \(s^\prime=E(s)\)
- \(F^\prime=\{Q|Q\subseteq K,Q\cap F\neq\empty\}\)
- 转移方程:
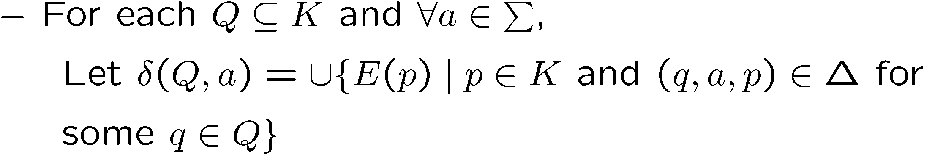
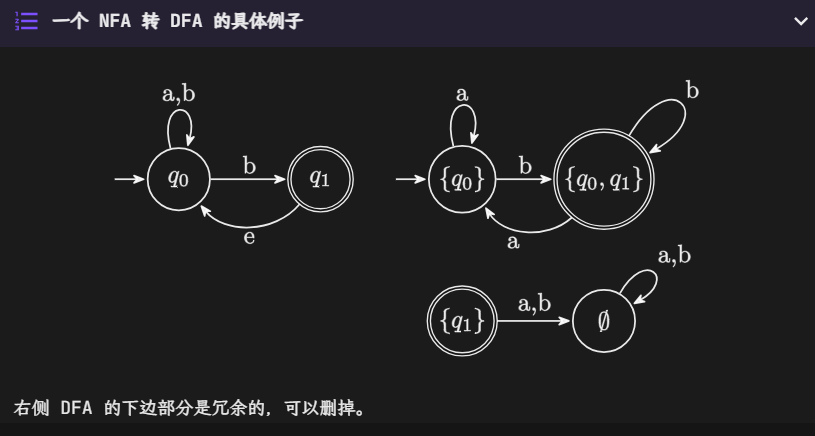
也就是说,我们取 NFA 状态的集合作为 DFA 的一个状态
对于 NFA 所有可能的状态集合,其转移方程为,集合内所有状态的转移关系的结果的 E()
从 \(s^\prime=E(s)\) 往后推即可
注意转换后的 DFA 状态都是 集合,是 NFA 状态的集合
DFA 最小化
算法描述:
- 将目前的终止状态放入一个集合,将其它状态放入另一个集合
- 遍历字母表,如果两个状态输入相同的字符转化到不同的状态,则拆分到不同集合,如果相同则保留在同一个集合
- 遍历结束后,处于同一集合的状态属于等价状态,合并为新状态
- 回到步骤 1,直到步骤 2 没有拆分出任何新集合
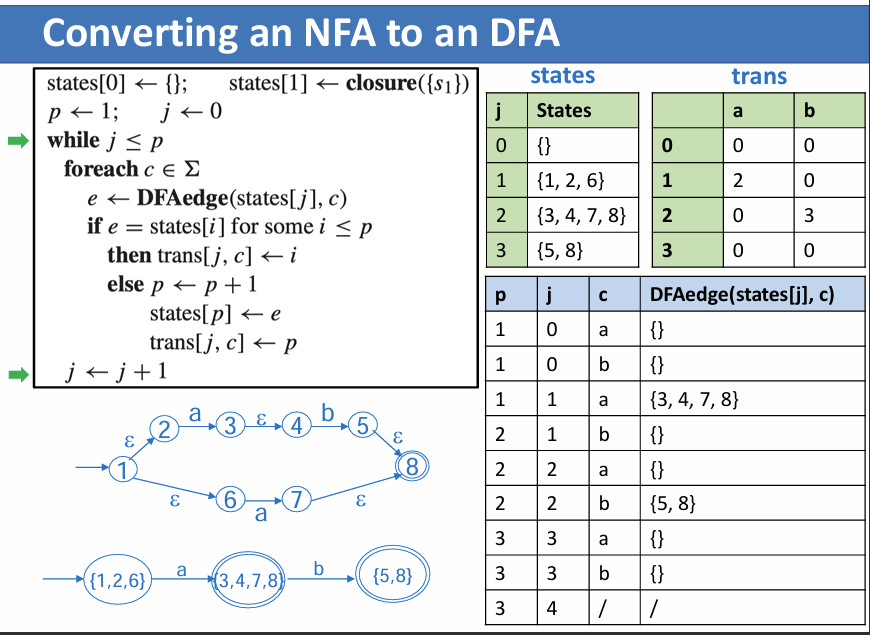
其实就是先取所有通过 \(\epsilon\) 相连的状态组成新的集合作为 DFA 的状态,然后按字母表有序地检查:当每一个字符输入后,状态集合里各个状态会转化到哪些状态,将其组成集合作为新的状态。如此往复,直到找不出新的状态为止
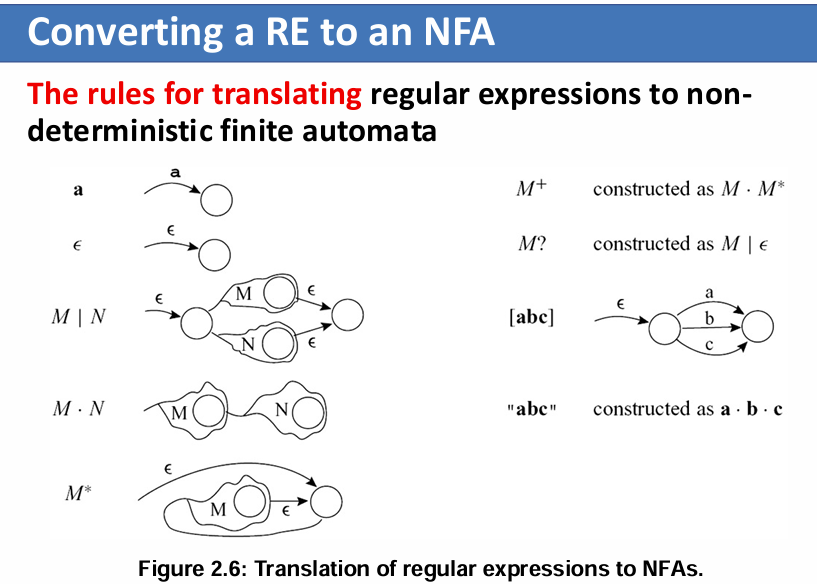
助教说最好按左边的样子来画
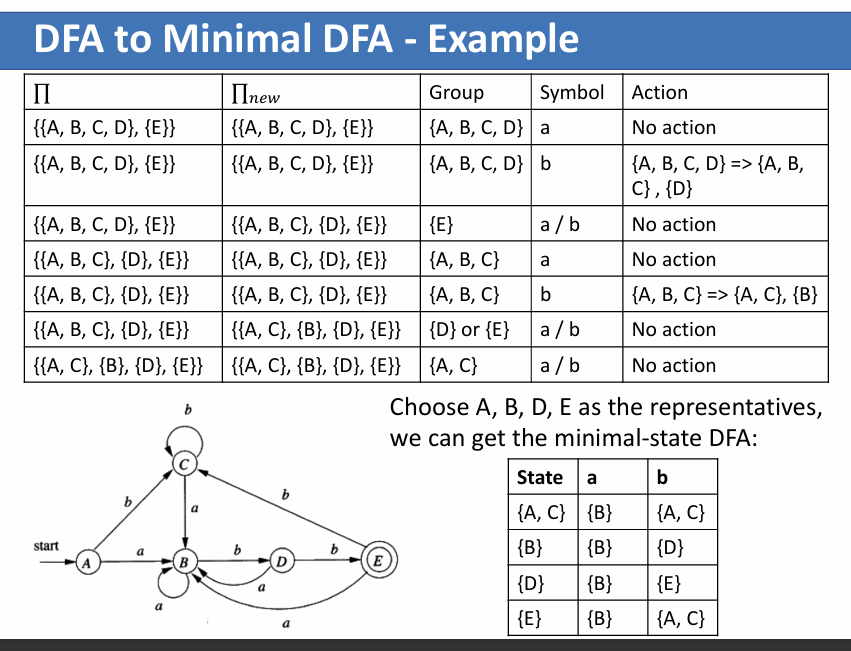
简单来说,就是初始化为 \({S-F,F}\) 两个状态集合,然后每轮循环里对所有集合进行检查:遍历字母表,检查集合里各个状态是否转换到了相同状态,如果不是,则将转换到相同状态的状态取出来组成新集合。如此循环,直到一轮检查后没有新的集合出现。