浙江大学实验报告
课程名称:操作系统 实验类型:综合型/设计型
实验项目名称:实验0 RV64 环境搭建和内核编译
学生姓名:俞仲炜 专业:计算机科学与技术 学号:3220104929
电子邮件地址:zhongweiy@zju.edu.cn 实验日期:2024.9.11
一、实验内容或步骤
包括思考题回答,对每一步的命令以及结果进行必要的解释
实验内容
搭建实验环境环境
安装的时候
$ sudo apt install gcc-riscv64-linux-gnu
$ sudo apt install autoconf automake autotools-dev curl libmpc-dev libmpfr-dev libgmp-dev \
gawk build-essential bison flex texinfo gperf libtool patchutils bc \
zlib1g-dev libexpat-dev git
第一条命令通过 apt 包管理器获取了适用于RISC-V 64位Linux系统的GNU编译器集合(GCC),就是在系统上安装了一个专门用于编译RISC-V架构程序的编译器。
第二条又臭又长,安装了一堆用于构建、配置和管理大型软件的包,比如前三个 \(auto\) 开头的包能自动生成配置脚本和 \(Makefile\),\(curl\) 用于下载文件、传输数据,\(gawk\) 是一个强大的文本处理工具,\(build-essential\) 包含了编译软件所必需的基本工具,如make,\(patchutils\) 用于打补丁,\(git\) 是一个分布式版本控制系统,用于管理代码。
这些工具我已经安装过了

第一条命令下载了 \(qemu\) 的一些基本组件。
第二条下载了 \(GDB\) 的一个多架构版本。
总的来说,这一步是在下载各种之后要用到的工具。
获取 Linux 源码和已经编译好的文件系统
获取 Linux 源码压缩包并用 \(tar\) 解压
通过 git 获取已经准备好的根文件系统镜像 rootfs.img
我已经克隆了,懒得删了重下了

如此我们已经准备好了这次实验要用到的资源
编译 Linux 内核
$ make ARCH=riscv CROSS_COMPILE=riscv64-linux-gnu- defconfig
$ make ARCH=riscv CROSS_COMPILE=riscv64-linux-gnu- -j$(nproc)
ARCH=riscv指定了目标架构为RISC-VCROSS_COMPILE=riscv64-linux-gnu-指定了交叉编译器的前缀,表示我们要编译的代码将运行在RISC-V 64位Linux系统上defconfig表示使用默认的配置文件$(nproc)获取的是当前进程可用的CPU数量,我的电脑是 32,-j的参数可根据实际情况往下调整
第一条命令为RISC-V架构的Linux内核配置一个默认的配置文件
.config文件是一个文本文件,至关重要,里面保存了关于内核编译时所做的各种配置选项,决定了最终生成的内核包含哪些功能、支持哪些硬件设备、以及如何运行
第二条命令编译Linux内核
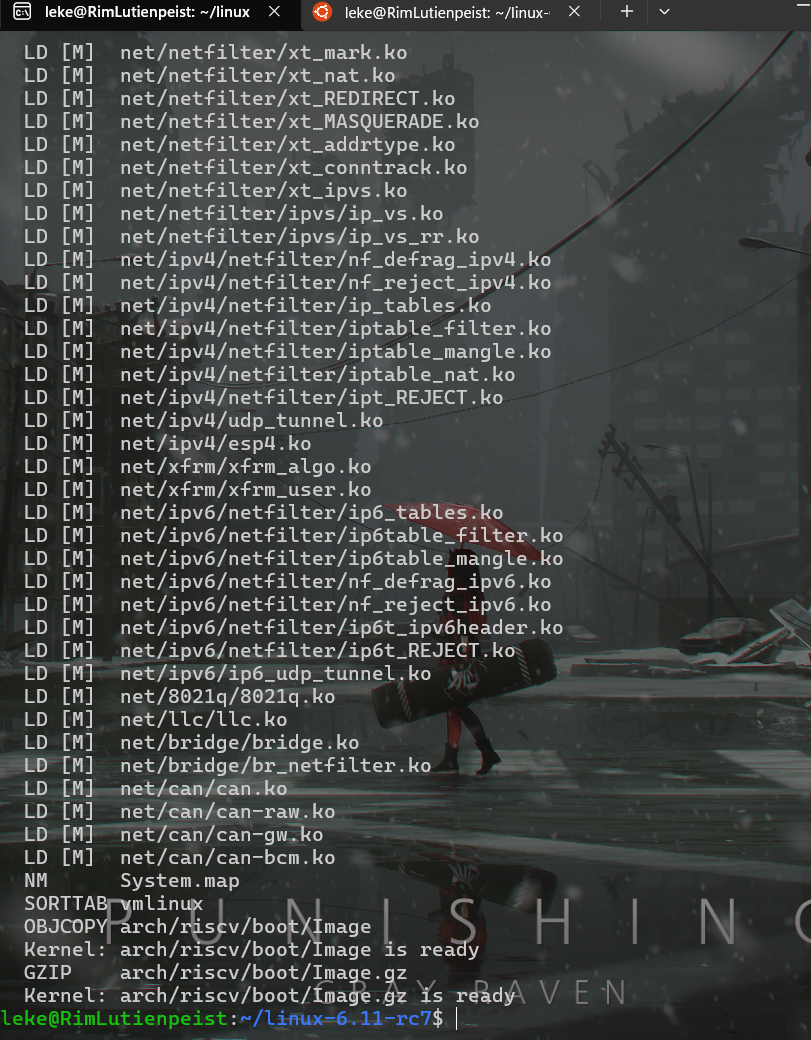
使用 QEMU 运行内核
qemu-system-riscv64 -nographic -machine virt -kernel arch/riscv/boot/Image -device virtio-blk-device,drive=hd0 -append "root=/dev/vda ro console=ttyS0" -bios default -drive file=~/24fall-os/os24fall-stu/src/lab0/rootfs.img,format=raw,id=hd0
这里的各个参数实验文档均已给出详细解释,故不再赘述
这条命令启动了一个 QEMU 虚拟机,用来模拟一个 RISC-V 64 位的 Linux 系统
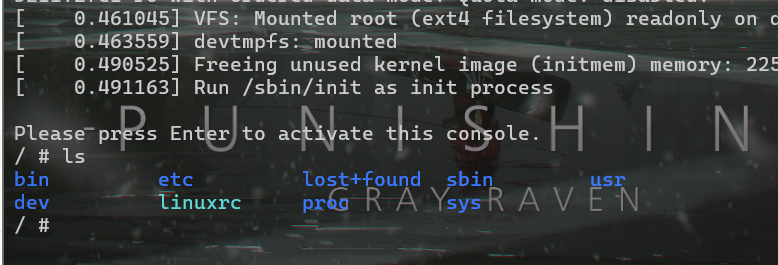
使用 GDB 对内核进行调试
我们开两个终端,一个负责打开程序,一个负责远程调试程序
qemu-system-riscv64 -nographic -machine virt -kernel arch/riscv/boot/Image \
-device virtio-blk-device,drive=hd0 -append "root=/dev/vda ro console=ttyS0" \
-bios default -drive file=~/24fall-os/os24fall-stu/src/lab0/rootfs.img,format=raw,id=hd0 -S -s
这各命令就是使用 QEMU 运行内核,只不过多了 -
s和-S两个参数服务于远程调试
这条命令表示使用支持多架构的 GDB 调试器来调试 Linux 内核。
gdb 即 GNU 调试器,multiarch 即多架构,gdb-multiarch 就是支持多架构的 GDB 调试器,意味着它可以调试编译成不同 CPU 架构的程序,比如 x86、ARM、RISC-V 等。
在交叉编译环境下调试 Linux 内核时,
gdb-multiarch就显得非常有用。
vmlinux是 Linux 内核的可执行文件,包含了内核的所有代码和符号信息。
符号信息即程序中的函数名、变量名等,这些信息对于调试非常重要,因为调试器可以通过符号名来找到代码中的对应位置。
GDB 命令尝试片段
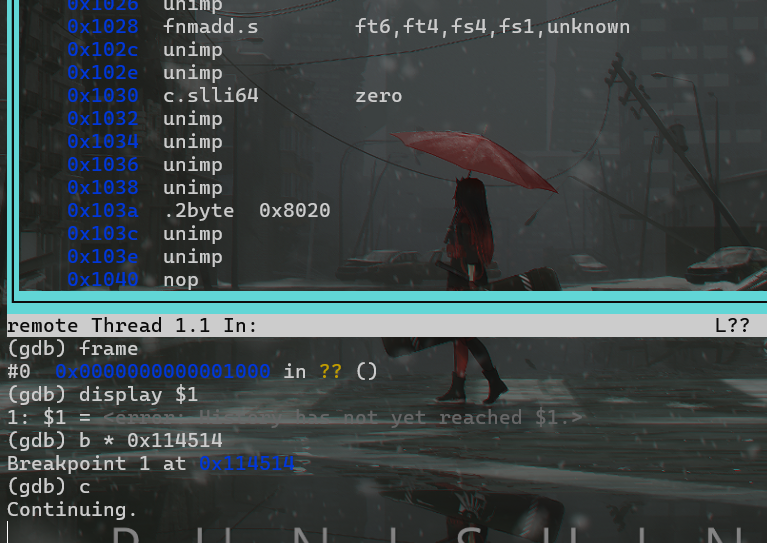
frame用于查看某个栈帧每个函数调用都会产生一个新的栈帧,用于存储函数的局部变量、参数、返回地址等信息。当一个函数调用另一个函数时,新的栈帧就会被压入栈中。
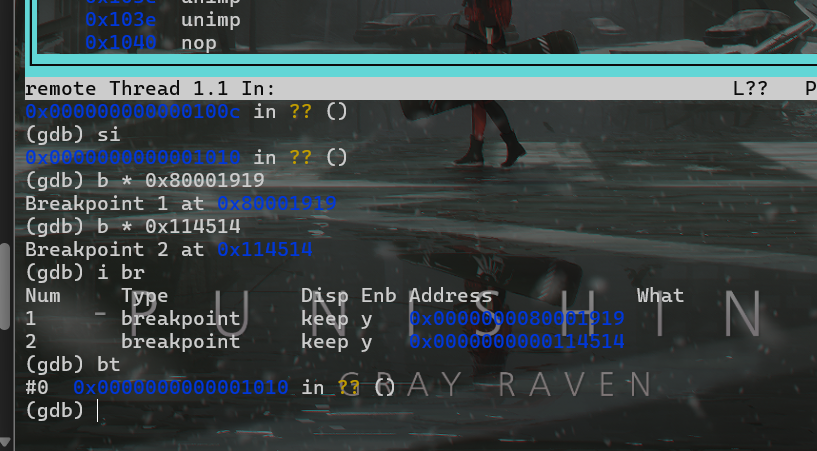
蓝色太深了好难看,不知道怎么调
bt即backtrace,用于显示当前函数调用栈的信息与
frame不同,backtrace提供的是整个函数调用栈的鸟瞰图,可以一次性显示多个栈帧的信息
frame是查看单个栈帧的详细信息,比较局部
思考题
使用 riscv64-linux-gnu-gcc 编译单个 .c 文件
riscv64-linux-gnu-gcc是一条完整的交叉编译器命令
riscv64指明目标处理器架构是 RISC-V 64 位
linux-gnu表示目标操作系统是 Linux,并且使用 GNU C 库(glibc)glibc 是 Linux 系统中最常用的 C 运行库,提供了许多系统调用和标准 C 库函数
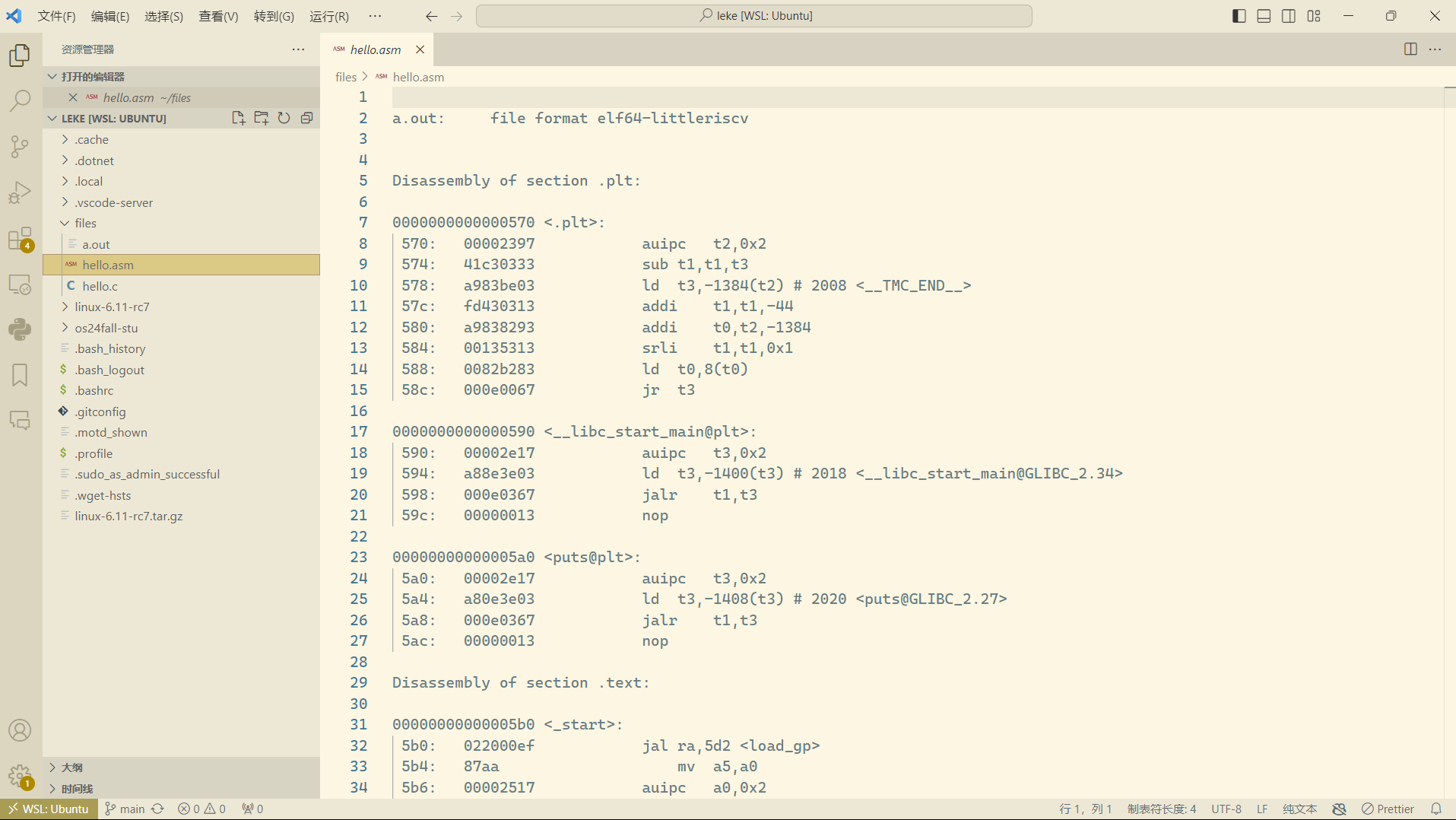
使用 riscv64-linux-gnu-objdump 反汇编 1 中得到的编译产物

-d指示objdump执行反汇编操作
> hello.asm将反汇编结果输出到hello.asm文件,这个箭头指示数据流向目标
下图为 \(VSCode\) 远程连接 \(WSL\) 查看反编译得到的 hello.asm
调试 Linux 时 :
- 在 GDB 中查看汇编代码
- 在 0x80000000 处下断点
- 查看所有已下的断点
- 在 0x80200000 处下断点
- 清除 0x80000000 处的断点
- 继续运行直到触发 0x80200000 处的断点
- 单步调试一次
- 退出 QEMU
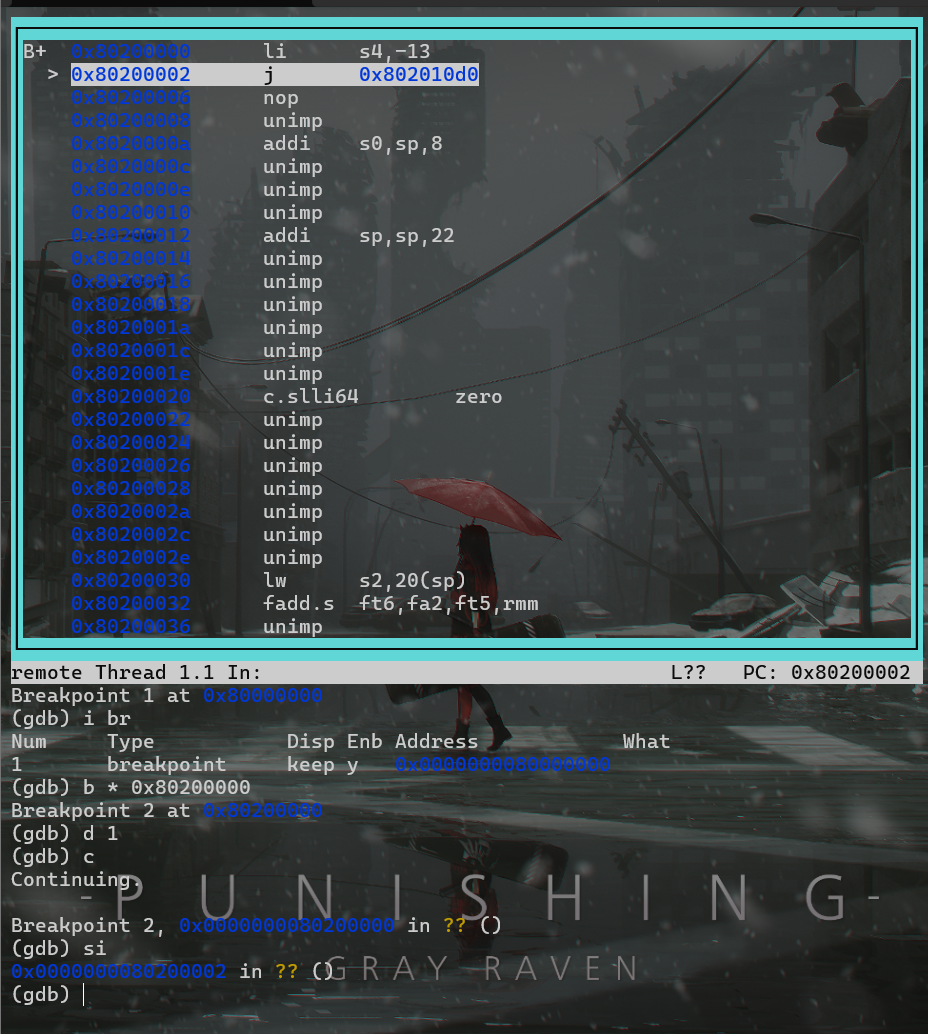
补充图里没有的:
- 在 GDB 中查看汇编代码:
layout asm - 在 0x80000000 处下断点:
b * 0x80000000 - 退出 QEMU:
使用 make 工具清除 Linux 的构建产物
vmlinux 和 Image 的关系和区别是什么?
前者是 Linux 内核编译的原始产物,是一个 \(ELF\) 格式的可执行文件,包含了内核所有代码和符号信息,提供了调试信息,所以可用于调试。
后者是对前者进行处理后得到的内核镜像二进制文件,可以进行压缩,所以可能不能调试。
总结来说,\(vmlinux\) 是内核的开发阶段使用的文件,而 \(Image\) 是内核的发布阶段使用的文件。\(vmlinux\) 提供了更详细的信息,方便开发者调试内核,而 \(Image\) 则更适合在实际系统中使用。
二、讨论、心得
实验中遇到的问题和解决方案
本次实验基本顺畅,没有遇到半天都解决不了的阻碍,都是一学就懂的东西。
这是本人第一次接触 Linux,所以认知障碍是非常大的,好在借助 gpt 和搜索引擎快速熟悉了 Linux 的基本知识与操作,并将新知识全部记录在了前面的实验报告里以便后续学习。
此外,深感 WSL 是披着 Linux 外衣的 Windows 系统,很多现成的软件可以直接远程连接 WSL 进行工作,十分便利,甚至资源管理器可以直接对 WSL 的文件进行管理。
个人感觉这样可能会限制学生的思维,毕竟 Linux 与 Windows 的操作思维应该相差挺大的?
额外啰嗦,与实验无关:
本人在此之前基本没有体验过命令行式交互,所以遇到的最大问题是无法确定交互后得到的反馈是不是正确的反馈。不过在有已经相对成熟的 gpt 的环境下学习一个计算机工具的成本已经非常低了,每条命令都可以喂给 gpt,进而可以学习到这条命令本身的作用和各个参数的作用,以及相应的反馈是什么,等等,所以这次实验整体做下来是十分轻松的,对于学生而言,gpt 用于辅助学习的价值远远大于直接获取答案的价值,gpt更像是一个次世代的搜索引擎,但似乎止步于此了?
20240913