浙江大学实验报告
[!ABSTRACT]
课程名称:操作系统 实验类型:综合型/设计型
实验项目名称:实验 2 RV64 内核线程调度
学生姓名:俞仲炜 专业:计算机科学与技术 学号:3220104929
队友:李立 专业:计算机科学与技术 学号:3220106038
电子邮件地址:zhongweiy@zju.edu.cn 实验日期:2024.11.9
一、实验内容或步骤
1.1 准备工程
将 LAB1 代码与 LAB2 新增代码进行整合,
[!QUOTE] 由于引入了简单的物理内存管理,需要在
_start的适当位置调用mm_init函数来初始化内存管理系统;
我们在 stack 初始化后调用 mm_init 来初始化内存管理系统,为 kalloc 操作准备 free page。
对 defs.h 文件进行内容添加后,工程可以正常运行。
1.2 线程调度功能实现
1.2.1 线程初始化
按照实验指导文档以及代码注释,我们对 task_init 函数进行补充
// 1. 调用 kalloc() 为 idle 分配一个物理页
idle = (struct task_struct*)kalloc();
// 2. 设置 state 为 TASK_RUNNING;
idle->state = TASK_RUNNING;
// 3. 由于 idle 不参与调度,可以将其 counter / priority 设置为 0
idle->counter = 0; idle->priority = 0;
// 1. 设置 idle 的 pid 为 0
idle->pid = 0;
// 5. 将 current 和 task [0] 指向 idle
current = idle; task[0] = idle;
idle 线程即 OS 的空闲进程,由于并没有为其设计 task_struct,所以需要手动追加线程信息。
本次实验框架下的线程最大数量是固定的,我们可以对所有的 task_struct 进行统一的初始化。
for(int i = 1; i < NR_TASKS; i++)
{
task[i] = (struct task_struct*)kalloc();
task[i]->state = TASK_RUNNING;
task[i]->counter = 0;
task[i]->priority = rand() % (PRIORITY_MAX - PRIORITY_MIN + 1) + PRIORITY_MIN;
task[i]->pid = i;
void (*__dummy_addr)(void) = __dummy;
task[i]->thread.ra = (uint64_t)__dummy_addr;
task[i]->thread.sp = (uint64_t)task[i] + PGSIZE;
}
- 我们通过
klloc为每个线程分配一个 page 的内存空间。 - 本次实验线程状态只有一个,即
TASK_RUNNING。 - 线程的 priority 在一定范围内随机设置,本次实验的范围为 [1,10]。
- 我们声明了一个函数指针指向
__dummy,以此获取其地址,方便赋予ra。 - 线程的
ra初始化为__dummy地址,后者用于初始化线程的上下文,并跳转进线程的执行体dummy。- 本次实验除 idle 外的所有线程的执行体均为
dummy
- 本次实验除 idle 外的所有线程的执行体均为
- 线程的
sp指向 page 的高地址,符合 RISCV 规定。
[!QUOTE] 在
arch/riscv/kernel/head.S中合适位置处调用task_init()进行线程初始化。
我们紧随 mm_init 的调用,在后面调用 task_init()。
1.2.2 __dummy 与 dummy 的实现
dummy 函数是线程的执行体,每执行一次后线程的时间片减 1。该函数由框架给出。
新线程的栈为空,当这个线程被调度时,是没有上下文需要被恢复的,所以需要为线程第一次调度提供一个特殊的返回函数 __dummy,其主要负责初始化 sepc,使得线程的运行与时钟中断事件绑定。
__dummy:
# set sepc = dummy
addi sp, sp, -8
sd t0, 0(sp)
la t0, dummy
csrw sepc, t0
ld t0, 0(sp)
addi sp, sp, 8
sret
1.2.3 实现线程切换
switch_to 判断下一个执行的线程 next 与当前的线程 current 是否为同一个线程,如果是同一个线程,则无需做任何处理,否则调用 __switch_to 进行线程切换:
void switch_to(struct task_struct *next) {
if(current != next)
{
printk("\switch to [PID = %d Priority = %d Counter = %d]\n", \
next->pid, next->priority, next->counter);
struct task_struct *prev = current;
current = next;
__switch_to(prev, next);
}
}
注意在第一次切换到相应线程时 __switch_to 里面会直接跳转离开 switch_to,所以不能在其之后放代码。
__switch_to 需要保存 Caller 没保存的寄存器,并恢复新线程需要的寄存器,最后跳转到新线程的 ra 所保存的地址。
__switch_to:
# save state to prev process
sd ra, 32(a0)
sd sp, 40(a0)
sd s0, 48(a0)
sd s1, 56(a0)
sd s2, 64(a0)
sd s3, 72(a0)
sd s4, 80(a0)
sd s5, 88(a0)
sd s6, 96(a0)
sd s7, 104(a0)
sd s8, 112(a0)
sd s9, 120(a0)
sd s10, 128(a0)
sd s11, 136(a0)
# restore state from next process
ld ra, 32(a1)
ld sp, 40(a1)
ld s0, 48(a1)
ld s1, 56(a1)
ld s2, 64(a1)
ld s3, 72(a1)
ld s4, 80(a1)
ld s5, 88(a1)
ld s6, 96(a1)
ld s7, 104(a1)
ld s8, 112(a1)
ld s9, 120(a1)
ld s10, 128(a1)
ld s11, 136(a1)
ret
1.2.4 实现调度入口函数
根据注释具体实现 do_timer() 函数,当前进程为 idle 线程或时间片已经或者即将耗尽时,立即调度。其余情况不操作。
void do_timer() {
// 1. 如果当前线程是 idle 线程或当前线程时间片耗尽则直接进行调度
// 2. 否则对当前线程的运行剩余时间减 1,若剩余时间仍然大于 0 则直接返回,否则进行调度
if(current == idle || current->counter == 0)
{
schedule();
}
else
{
if(--(current->counter)) return;
schedule();
}
}
1.2.5 线程调度算法实现
如果所有的线程 counter 都是 0,说明所有线程的时间片均已耗尽,需要根据优先级进行初始化。
// 1. If the counter of all tasks are 0, set all the counters to the task's priority
uint8_t All_zero_bool = 1;
for(int i = 0; i < NR_TASKS; i++) {
if(task[i]->counter != 0) {
All_zero_bool = 0;
break;
}
}
if(All_zero_bool) {
for(int i = 0; i < NR_TASKS; i++) {
task[i]->counter = task[i]->priority;
}
}
我们从所有进程中选取时间片(对应优先级)最多的线程进行下一次运行。
// 2. Choose the task with highest counter to be next
int next = 0;
for(int i = 0; i < NR_TASKS; i++) {
if(task[i]->counter > task[next]->counter)
next = i;
}
// 3. Switch to the next task
switch_to(task[next]);
思考题
在 RV64 中一共有 32 个通用寄存器,为什么 __switch_to 中只保存了 14 个?
在 RV64 中,通用寄存器中被分为了 Caller saved registers 和 Callee saved registers 两类,意思是函数调用时,有些寄存器是 Caller 负责保存,另一些是 Callee 负责保存
在 C 语言实现的 switch_to 函数中调用 __switch_to 时,编译器会隐式保存 Caller saved registers,包括临时寄存器(tx)和传参寄存器(ax)
所以在 __switch_to 中,我们只需要属于 Callee saved registers 的 12 个 save 寄存器(sx),以及用于跳转的 ra 寄存器、sp 寄存器,共计 14 个
阅读并理解 arch/riscv/kernel/mm.c 代码,尝试说明 mm_init 函数都做了什么,以及在 kalloc 和 kfree 的时候内存是如何被管理的。
_ekernel 位于 vmlinux 的末尾,负责记录 kernel 代码的结束地址,如此动态分配的内存都不会影响到 kernel
void kfreerange(char *start, char *end) {
char *addr = (char *)PGROUNDUP((uintptr_t)start);
for (; (uintptr_t)(addr) + PGSIZE <= (uintptr_t)end; addr += PGSIZE) {
kfree((void *)addr);
}
}
PGROUNDUP 负责保证页对齐,使得高位的 36 个 bit 能指示一个 page 的位置,这里通过其找到了内核代码段后的第一个空页的低地址,作为动态内存的起点,然后往后直到内存末尾,对每一个 page 进行初始化
memset(addr, 0x0, (uint64_t)PGSIZE);
r = (struct run *)addr;
r->next = kmem.freelist;
kmem.freelist = r;
初始化的操作包括清零、加入空闲链表作为新表头两个步骤(之前还有一个页对齐操作)
void *kalloc() {
struct run *r;
r = kmem.freelist;
kmem.freelist = r->next;
memset((void *)r, 0x0, PGSIZE);
return (void *)r;
}
我们调用 kalloc 时,会直接弹出空页链表的表头页,将其清 0 ,如此得到了一块可用的 page。
当线程第一次调用时,其 ra 所代表的返回点是 __dummy,那么在之后的线程调用中 __switch_to 中,ra 保存 / 恢复的函数返回点是什么呢?请同学用 gdb 尝试追踪一次完整的线程切换流程,并关注每一次 ra 的变换(需要截图)。
进行了一轮时间片轮转后,我们先尝试追踪线程切换流程
从最高优先级的 PID2 开始向 PID8 切换线程
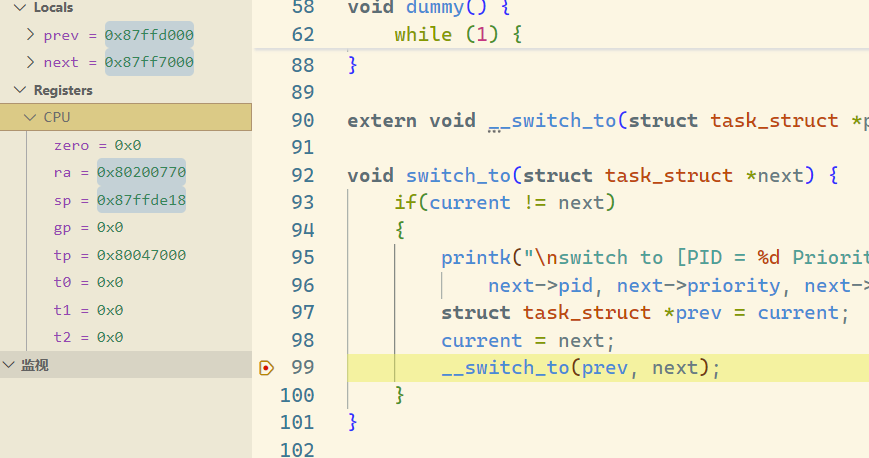
进入 __switch_to,此时 ra 为 0x8020079c,通过 gdb 查询可知此时 ra 保存的是
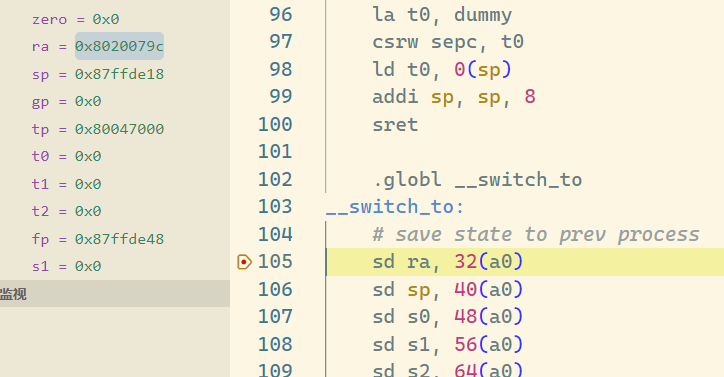

恢复之后的 ra 没有变化,和保存的一毛一样,这解答了题目的第一问的后一半
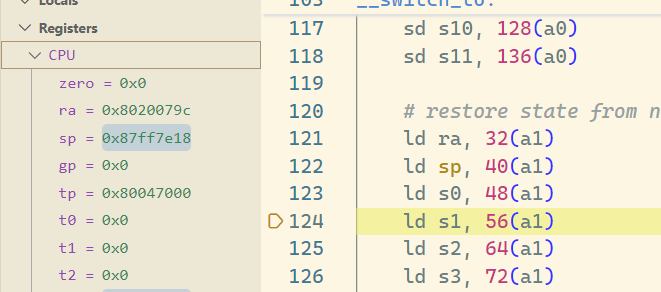
之后 ret 出来,可见这个 switch_to 函数的末尾,如此正好回到原来的执行流程

之后依次退出各个函数又回到 trap_handler ,回到 _traps
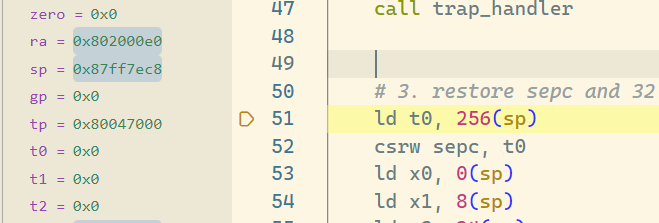
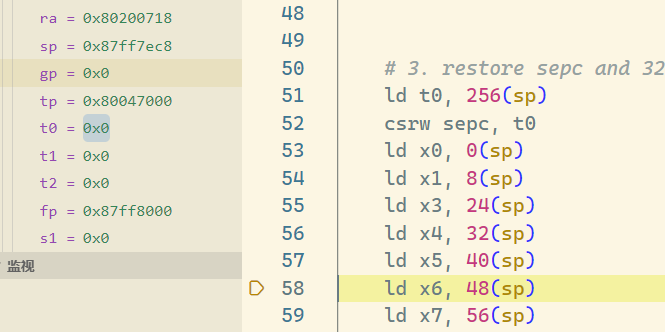
这里 ld 的 ra 显示在 dummy 函数某处,不过返回指令是 sret,返回地址不是 ra 而是 sepc

打满断点后发现是直接进入循环体内了,这是因为发生异常时还在 dummy 里进行死循环,所以 sepc 会设置在这
到此,线程切换完整结束
[!QUESTION]
验收时被问了这里为什么会跳回
dummy,明明实验报告已经把答案写过了,但当时居然还是没能回答上来,十分惭愧复盘了下,从
_traps能够sret回dummy内部,那说明sepc在中断发生时是在dummy内部的,dummy内部的循环在完成一次后陷入无操作的死循环,直到下一次时钟中断出现,sepc就理所当然地指向了dummy内部,进而在sret时跳回来现在想回来,当时没想到这条逻辑的原因有很多,一个是当时以为
_traps最后的跳转是ret指令,一直在想ra是<dummy+224>所以跳回了dummy;还有一个比较复杂,我
请尝试分析并画图说明 kernel 运行到输出第两次 switch to [PID ... 的时候内存中存在的全部函数帧栈布局。
利用 gdb 的 bt 命令追踪从 kernel 运行到输出第两次 switch to [PID ... 过程中的栈帧,可以整合得到如下函数栈帧布局
| ... | High addr |
|---|---|
| dummy () | **page of first thread ** |
| _traps () | |
| trap_handler (scause = 9223372036854775813, sepc = 2149582440) |
|
| do_timer () | |
| schedule () | |
| switch_to(next = 0x87ff7000) | |
| ... | |
| _stext () | boot_stack |
| start_kernel () | |
| _traps () | |
| trap_handler (scause = 9223372036854775813, sepc = 2149584160) |
|
| do_timer () | |
| schedule () | |
| switch_to (next = 0x87ffd000) | |
| __switch_to | |
| ... | Low addr |
由于输出第两次 switch to [PID ... 时还没开始执行 __switch_to,第二个线程的 page 无函数栈帧
心得体会
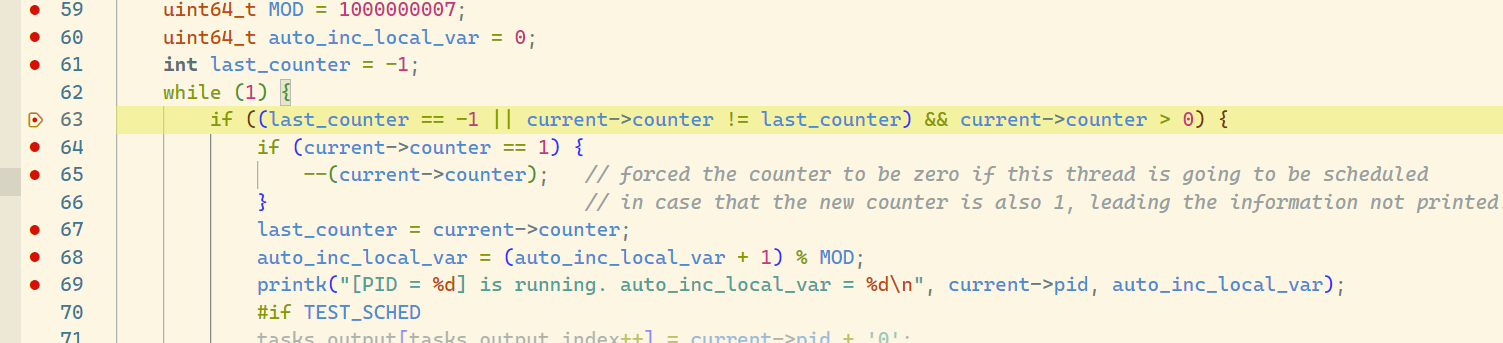
dummy()
在 dummy 函数中:
void dummy() {
uint64_t MOD = 1000000007;
uint64_t auto_inc_local_var = 0;
int last_counter = -1;
while (1) {
if ((last_counter == -1 || current->counter != last_counter) && current->counter > 0) {
if (current->counter == 1) {
--(current->counter); // forced the counter to be zero if this thread is going to be scheduled
} // in case that the new counter is also 1, leading the information not printed.
last_counter = current->counter;
auto_inc_local_var = (auto_inc_local_var + 1) % MOD;
printk("[PID = %d] is running. auto_inc_local_var = %d\n", current->pid, auto_inc_local_var);
在这个函数中,我们观察到,即使注释了 if (current->counter == 1) 的部分,程序的运行也不受影响。经过探讨分析,我们认为,这是因为我们在 do_timer 函数中处理了 current->counter == 1 的情况并强迫调度,故此在 dummy 中的这个 if 显得不再重要。
__dummy:
关于为什么要设计 __dummy 用于中转,而不是直接在线程初始化时将 ra 赋值为 dummy 的地址:因为后者没有对线程的 sepc 赋值,导致时钟中断时无法正确 sret。