浙江大学实验报告
[!ABSTRACT]
课程名称:操作系统 实验类型:综合型/设计型
实验项目名称:实验 5: RV64 缺页异常处理与 fork 机制
学生姓名:俞仲炜 专业:计算机科学与技术 学号:3220104929
队友:李立 专业:计算机科学与技术 学号:3220106038
电子邮件地址:zhongweiy@zju.edu.cn 实验日期:2024.12.22
实验内容或步骤
准备工作
从仓库同步 user/main.c 文件并删除原来的 getpid.c
修改 user/Makefile
[!TIP]
注意不需要加逗号与已有部分隔开,直接原封不动放后面即可
缺页异常处理
实现虚拟内存管理功能
VMA 权限的相关操作主要在 proc.c 和 trap.c 内,所以在 `proc.h 内添加以下 VMA 权限相关宏:
在 proc.h 添加 vma 的数据结构,采用链表的实现:
struct vm_area_struct {
struct mm_struct *vm_mm; // 所属的 mm_struct
uint64_t vm_start; // VMA 对应的用户态虚拟地址的开始
uint64_t vm_end; // VMA 对应的用户态虚拟地址的结束
struct vm_area_struct *vm_next, *vm_prev; // 链表指针
uint64_t vm_flags; // VMA 对应的 flags
// struct file *vm_file; // 对应的文件(目前还没实现,而且我们只有一个 uapp 所以暂不需要)
uint64_t vm_pgoff; // 如果对应了一个文件,那么这块 VMA 起始地址对应的文件内容相对文件起始位置的偏移量
uint64_t vm_filesz; // 对应的文件内容的长度
};
struct mm_struct {
struct vm_area_struct *mmap;
};
struct task_struct {
uint64_t state;
uint64_t counter;
uint64_t priority;
uint64_t pid;
struct thread_struct thread;
uint64_t *pgd;
struct mm_struct mm;
};
每一个 vm_area_struct 都对应于 task 地址空间的唯一连续区间,
为了支持 demand paging,我们需要支持对 vm_area_struct 的添加和查找,分别由 find_vma 和 do_mmap 函数负责
[!NOTE]
实际上等价于链表的查询和插入操作
find_vma 只需遍历 vma 链表,找到对应的地址区间即可:
struct vm_area_struct *find_vma(struct mm_struct *mm, uint64_t addr) {
struct vm_area_struct *res = mm->mmap;
if(!res) Err(PURPLE "mm is empty");
while(res){
if(addr>=res->vm_start && addr<res->vm_end) break;
res = res->vm_next;
}
return res;
}
do_mmap 则需新建 vm_area_struct 结构体,再根据传入的参数对结构体赋值,并按序添加到 mm 指向的 VMA 链表中
uint64_t do_mmap(struct mm_struct *mm, uint64_t addr, uint64_t len,
uint64_t vm_pgoff, uint64_t vm_filesz, uint64_t flags) {
// set new vma
struct vm_area_struct *new_vma = (struct vm_area_struct *)kalloc();
new_vma->vm_mm = mm;
new_vma->vm_start = addr;
new_vma->vm_end = addr + len;
new_vma->vm_pgoff = vm_pgoff;
new_vma->vm_filesz = vm_filesz;
new_vma->vm_flags = flags;
// find the position to insert
struct vm_area_struct **next_ptr;
for (next_ptr = &mm->mmap;
*next_ptr && (*next_ptr)->vm_start < new_vma->vm_start;
next_ptr = &(*next_ptr)->vm_next);
// insert
new_vma->vm_next = *next_ptr;
if(*next_ptr) {
new_vma->vm_prev = (*next_ptr)->vm_prev;
(*next_ptr)->vm_prev = new_vma;
}
*next_ptr = new_vma;
return new_vma->vm_start;
}
修改 task_init
接下来准备实现 demand paging,我们的实验只需要根据 vm_area_struct 中的 vm_flags 来确定当前发生了什么样的错误,分情况进行处理
task_init 不再需要立即构建用户栈、与代码和数据区域的映射,而是只需先为这俩区域构建对应的 VMA:
void task_init() {
...
for(int i = 1; i < nr_tasks; i++){
...
/* LAB5 4.2.2 */
// pgtbl
task[i]->pgd = (uint64_t *)kalloc();
Log(BLUE "[DEBUG] task[%d] alloc: 0x%lx\n", i, task[i]->pgd);
for(int j = 0; j < 512; j++){
task[i]->pgd[j] = swapper_pg_dir[j];
}
Log(BLUE "[DEBUG] task[%d] pgd: 0x%lx\n", i, task[i]->pgd);
// segment
task[i]->mm.mmap = NULL;
load_program(task[i]);
if(task[i]->mm.mmap == NULL) Err("task[%d] mmap failed", i);
// stack
do_mmap(&task[i]->mm, USER_END - PGSIZE, PGSIZE, 0, 0, VM_ANON | VM_READ | VM_WRITE);
}
Log(GREEN "[DEBUG] task_init done\n");
}
其中 load_program 函数也需删除掉对用户栈、代码的映射操作:
void load_program(struct task_struct *task) {
Elf64_Ehdr *ehdr = (Elf64_Ehdr *)_sramdisk;
Elf64_Phdr *phdrs = (Elf64_Phdr *)(_sramdisk + ehdr->e_phoff);
for (int i = 0; i < ehdr->e_phnum; ++i) {
Elf64_Phdr *phdr = phdrs + i;
if(phdr->p_type == PT_LOAD) {
Elf64_Word p_flags = phdr->p_flags;
uint64_t perm = (p_flags & PF_X ? VM_EXEC : 0) |
(p_flags & PF_W ? VM_WRITE : 0) |
(p_flags & PF_R ? VM_READ : 0);
do_mmap(&task->mm, phdr->p_vaddr, phdr->p_memsz, phdr->p_offset, phdr->p_filesz, perm);
}
}
task->thread.sepc = ehdr->e_entry;
}
在完成上述修改之后,如果运行代码我们就可以截获一个 page fault,如下所示:

发生了缺页异常的 sepc 是 0x100e8,说明我们在 sret 来跳转到用户态程序的时候,第一条指令就因为 V-bit 为 0 表征其映射的地址无效而发生了异常
实现 page fault handler
接下来修改 trap.c 中的 trap_handler ,添加捕获 page fault 的逻辑,分别需要捕获 12, 13, 15 号异常:
void trap_handler(uint64_t scause, uint64_t sepc, struct pt_regs *regs) {
...
else if (exc == 12 || exc == 13 || exc == 15) {
do_page_fault(regs);
}
...
}
捕获了 page fault 之后,需要实现缺页异常的处理函数 do_page_fault:
void do_page_fault(struct pt_regs *regs) {
Log(YELLOW "Page Fault at %lx with scause %ld\n", csr_read(stval), csr_read(scause));
// find the vma
uint64_t bad_addr = csr_read(stval);
struct vm_area_struct *vma = find_vma(¤t->mm, bad_addr);
if (vma == NULL) Err(RED "Page fault at %p: no vma found", bad_addr);
// check permission
uint64_t exc = csr_read(scause);
uint64_t flags = vma->vm_flags;
if (exc == 12 && !(flags & VM_EXEC)) {
Err(RED "Page fault at %p: caused by an instruction fetch", bad_addr);
} else if (exc == 13 && !(flags & VM_READ)) {
Err(RED "Page fault at %p: caused by a read", bad_addr);
} else if (exc == 15 && !(flags & VM_WRITE)) {
Err(RED "Page fault at %p: caused by a write", bad_addr);
}
// allocate a new page and map it
char *new_pg = (char *)alloc_page();
uint64_t vpg_start = PGROUNDDOWN(bad_addr);
uint64_t vpg_end = PGROUNDUP(bad_addr);
// permision
uint64_t perm = (flags & VM_READ ? PGTBL_ENTRY_R : 0) |
(flags & VM_WRITE ? PGTBL_ENTRY_W : 0) |
(flags & VM_EXEC ? PGTBL_ENTRY_X : 0) |
PGTBL_ENTRY_U | PGTBL_ENTRY_V;
if(!(flags & VM_ANON))
memcpy(_sramdisk + vma->vm_pgoff + vpg_start - vma->vm_start,
new_pg, PGSIZE);
else memset(new_pg, 0, PGSIZE);
create_mapping(current->pgd, vpg_start, new_pg - PA2VA_OFFSET,
PGSIZE, perm);
// flush TLB
asm volatile("sfence.vma zero, zero");
Log(GREEN "[PAGE FAULT FIXED] Page fault at %p: fixed\n", bad_addr);
}
函数的具体逻辑为:
- 通过
stval获得访问出错的虚拟内存地址,即bad_addr变量 - 通过
find_vma()查找 bad address 是否在某个 vma 中 - 检查当前 page fault 是否合法,即对应的内存操作是否是符合权限的
- 分配待映射的内存页
- 检查当前的 VMA 是否是匿名空间,如果是则可以直接映射,否则需要将对应的代码段加载进来
- 构建这个新内存页的映射,并刷新 TLB
测试缺页处理
make run TEST=PFH1
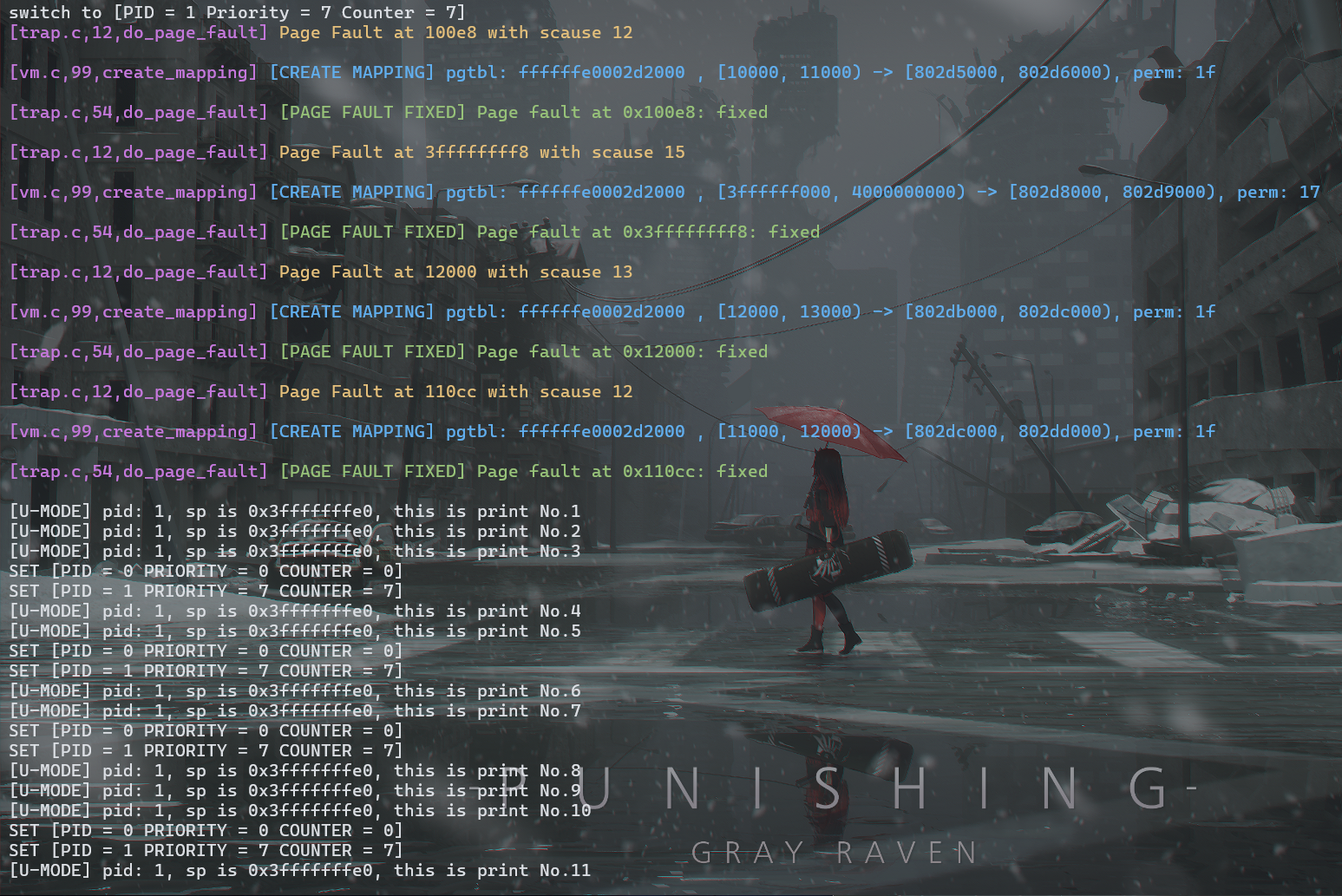
可以看到缺页异常并且只有第一次触发了,并得到了处理,用户态程序成功完成了打印操作
make run TEST=PFH2
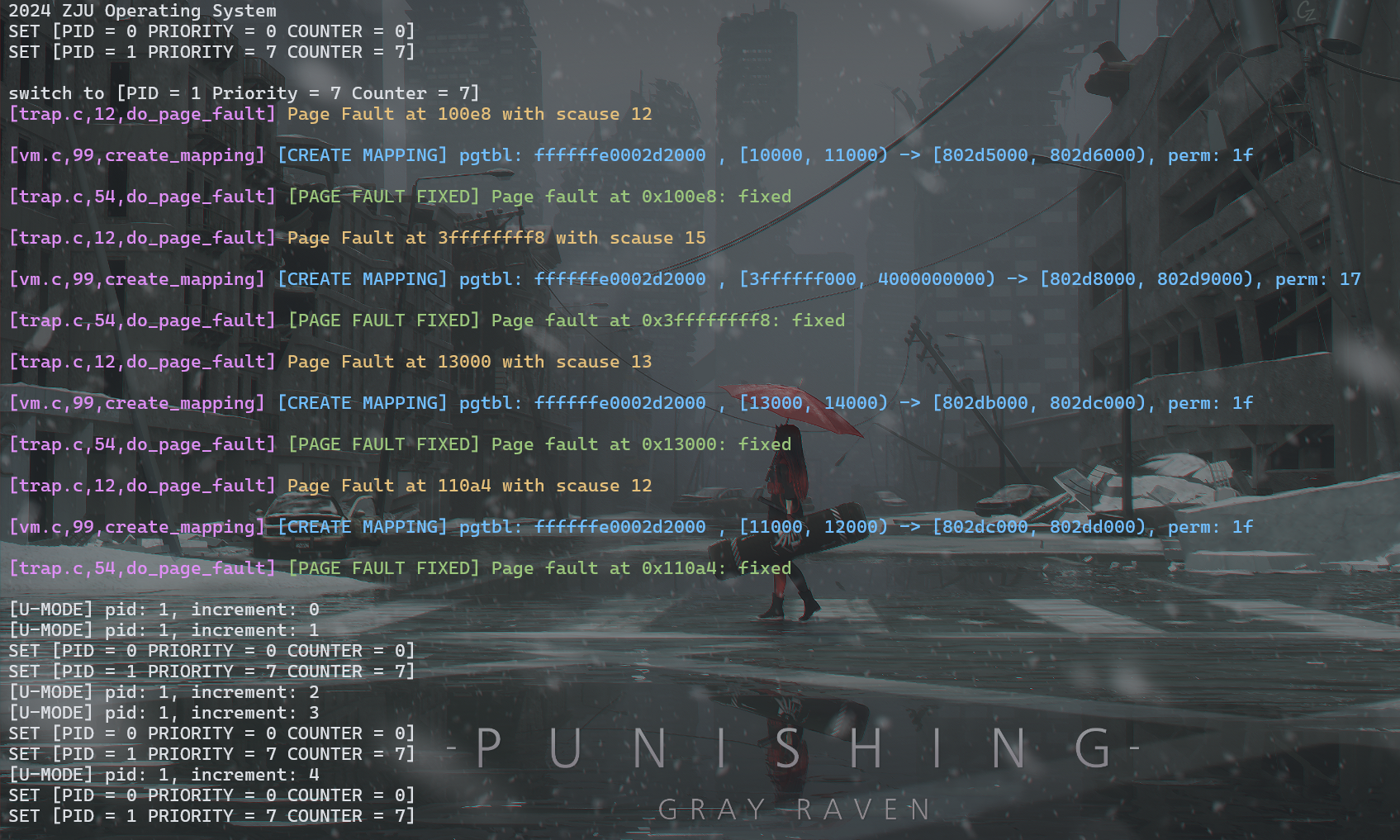
可以看到缺页异常处理时跳过了未使用的 .data 区域,说明该段区域没有触发缺页异常,在 log 中也可以发现 create_mapping 映射的虚拟地址空间缺少了 [12000,13000)
实现 fork 系统调用
表面的准备工作
在 proc.c 中添加全局变量 nr_tasks 来记录当前进程数,初始化为 2,如此,内核启动时仅创建一个 idle 进程和一个用户程序进程
此外,还需修改 proc.c 里遍历 struct task_struct *task[NR_TASKS] 时用到的上限,从 NR_TASKS 改为 nr_tasks
为了完成 FORK3 测试,将 NR_TASKS 宏的定义修改为 (1+8)
在 kernel 以及 user 中的 syscall.h 均添加以下系统调用号宏
在系统调用的处理函数中,检测到 regs->a7 == SYS_CLONE 时,调用 do_fork 函数来完成 fork 的工作:
void trap_handler(uint64_t scause, uint64_t sepc, struct pt_regs *regs) {
...
else if(regs->reg[16] == SYS_CLONE) {
Log(YELLOW "[SYSCALL] SYS_CLONE, sepc = 0x%lx\n", csr_read(sepc));
regs->reg[9] = do_fork(regs);
regs->sepc += 4;
}
...
}
思考 do_fork 要做什么
fork 的工作:
- 创建一个新进程作为子进程,为子进程分配新的 PID
- 拷贝父进程的内核栈给子进程,更新部分子进程的寄存器
- 创建一个新的页表
- 拷贝内核页表
swapper_pg_dir - 遍历父进程 vma,并遍历父进程页表,并相应地更新页表
- 拷贝内核页表
- 将子进程加入调度队列,等待下一轮调度
- 返回子进程的 PID 给父进程的用户态程序
依据上面的框架,我们只需逐个实现各个功能模块即可实现 do_fork
拷贝内核栈
task_struct 数据结构和内核栈分别位于同一个页的首尾,我们可以 memcpy 深拷贝这个页来得到需要的信息:
此时内核栈已经在 _traps 处压入了父进程的用户态寄存器已经部分 CSR 寄存器(即 pt_regs 数据结构),子进程通过相应的地址即可访问这些数据:
struct pt_regs *ch_regs = (struct pt_regs *)((uint64_t)child + (uint64_t)regs - PGROUNDDOWN((uint64_t)regs));
此外,由于子进程内核栈不是共享父进程的,且存在部分元数据需要修正,我们需要相应地修改 task_struct 以及部分用户态寄存器的值:
child->pid = nr_tasks++;
child->thread.ra = (uint64_t)__ret_from_fork;
// point sp at pt_regs
ch_regs->reg[1] = ch_regs;
child->thread.sp = ch_regs;
// user stack is shared
child->thread.sscratch = csr_read(sscratch);
child->pgd = (uint64_t *)kalloc();
(child->mm).mmap = NULL;
ch_regs->reg[9] = 0; // reg a0
ch_regs->sepc += 4;
其中:
child->pid即标识符child->thread.ra会在__switch_to弹出,使得子进程ret到 “刚 call 完 trap_handler” 的状态,也就是子进程被 fork 时父进程的状态ch_regs->reg[1]和child->thread.sp即sp,指向用户态寄存器数据结构地址,前者在子进程跳到 “刚 call 完 trap_handler” 的状态后会恢复至其sscratch,完成修改;后者在__switch_to会被压入压出child->thread.sscratch设置为父进程的即可,因为用户栈虚拟地址共用child->pgd分配一个新页,不同进程页表不共用(child->mm).mmap设置为NULL,之后构建ch_regs->reg[9]设置为0,子进程 fork 返回0即可ch_regs->sepc手动加 4,防止 fork 操作重复执行
创建子进程页表
我们首先拷贝内核页表 swapper_pg_dir:
随后拷贝父进程 vma 链表,并相应地检查每个 vma 是否有页有对应的页表项存在,有的话需要深拷贝一整页的内容并映射到新页表中:
struct vm_area_struct *vma = (current->mm).mmap;
while (vma != NULL)
{
do_mmap(&(child->mm), vma->vm_start, vma->vm_end - vma->vm_start, vma->vm_pgoff, vma->vm_filesz, vma->vm_flags);
uint64_t src_vmapg = PGROUNDDOWN(vma->vm_start);
while (src_vmapg < vma->vm_end)
{
if (page_is_valid(current->pgd, src_vmapg) == 1)
{
uint64_t page = (uint64_t)alloc_page();
memcpy((void *)(src_vmapg), (void *)page, PGSIZE);
if(vma->vm_flags & VM_ANON)
create_mapping(child->pgd, src_vmapg , page - PA2VA_OFFSET, PGSIZE, (vma->vm_flags) |
PGTBL_ENTRY_U | PGTBL_ENTRY_R | PGTBL_ENTRY_W | PGTBL_ENTRY_V);
else
create_mapping(child->pgd, src_vmapg , page - PA2VA_OFFSET, PGSIZE, (vma->vm_flags) |
PGTBL_ENTRY_U | PGTBL_ENTRY_X | PGTBL_ENTRY_R | PGTBL_ENTRY_V);
}
src_vmapg += PGSIZE;
}
vma = vma->vm_next;
}
其中 page_is_valid 负责检查每个 vma 管理的每一个页是否存在于父进程页表中:
int page_is_valid(uint64_t *pgd, uint64_t va) {
uint64_t vpn[3];
vpn[2] = (va >> 30) & 0x1ff;
vpn[1] = (va >> 21) & 0x1ff;
vpn[0] = (va >> 12) & 0x1ff;
uint64_t *pte = pgd;
uint64_t p_pte = NULL;
uint64_t res = 1;
for (int i = 2; i > 0; i--)
if ((pte[vpn[i]] & 0x1) == 0) {
res = 0;
}else{
p_pte = ((pte[vpn[i]] >> 10 << 12));
pte = (uint64_t *)(p_pte + PA2VA_OFFSET);
}
if ((pte[vpn[0]] & 0x1) == 0) res = 0;
return res;
}
处理进程返回逻辑
父进程的返回逻辑非常简单,直接为 do_fork 函数返回子进程的 pid 即可:
子进程要通过被调度了才能开始执行:schedule -> switch_to-> __switch_to-> " thread.ra" -> 用户程序
thread.ra 的设置与原因在 1.3.3 已说明,其值 __ret_from_fork 指向 “刚 call 完 trap_handler” 的状态
...
call trap_handler
.globl __ret_from_fork
__ret_from_fork:
# 3. restore sepc and 32 registers from stack
...
如此利用 __switch_to 时恢复的 ra 与 sp,我们可以直接跳转到 _traps 中从 trap_handler 返回的位置
其余相关寄存器的设置均已在 1.3.3 说明
测试 fork
make run TEST=FORK1
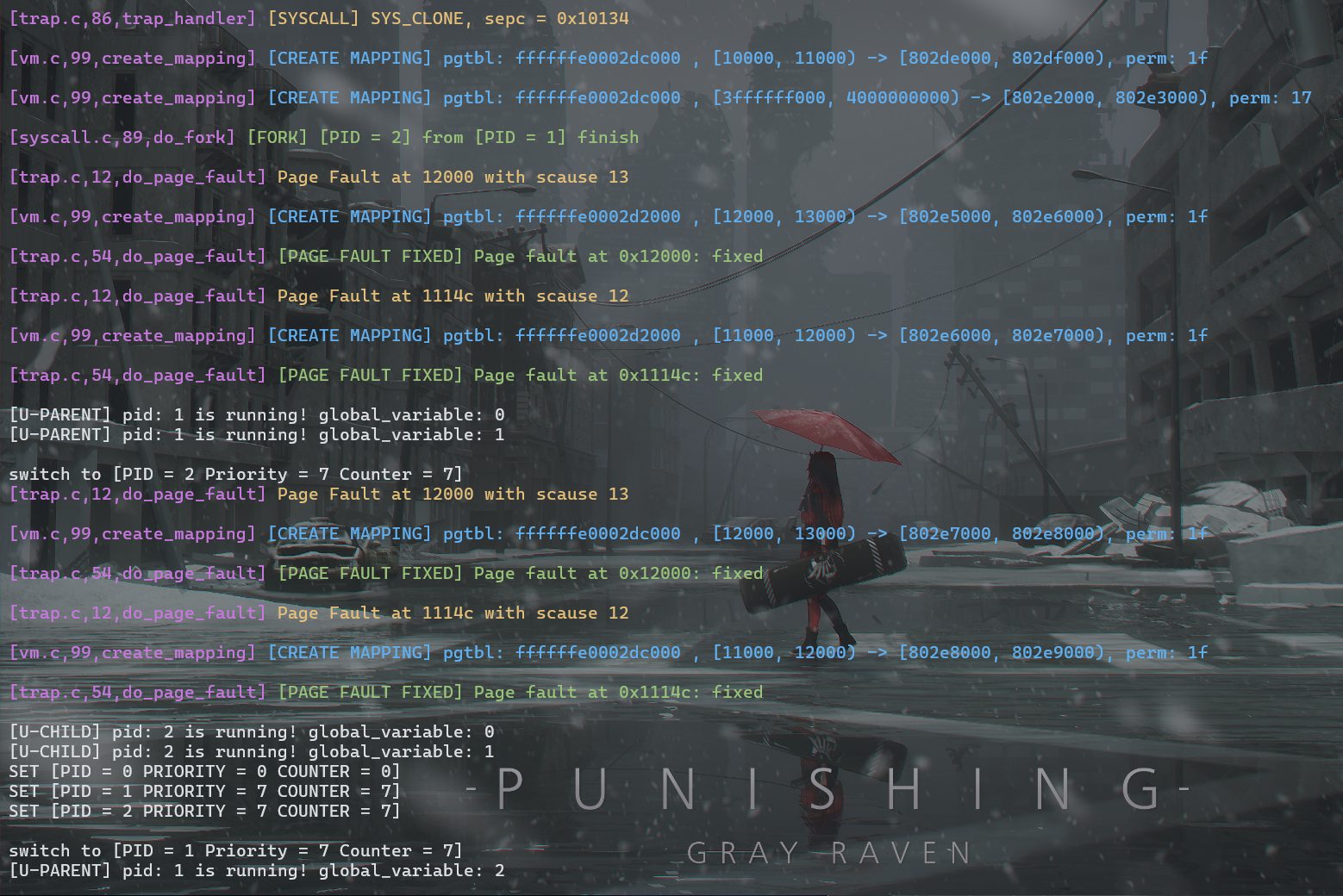
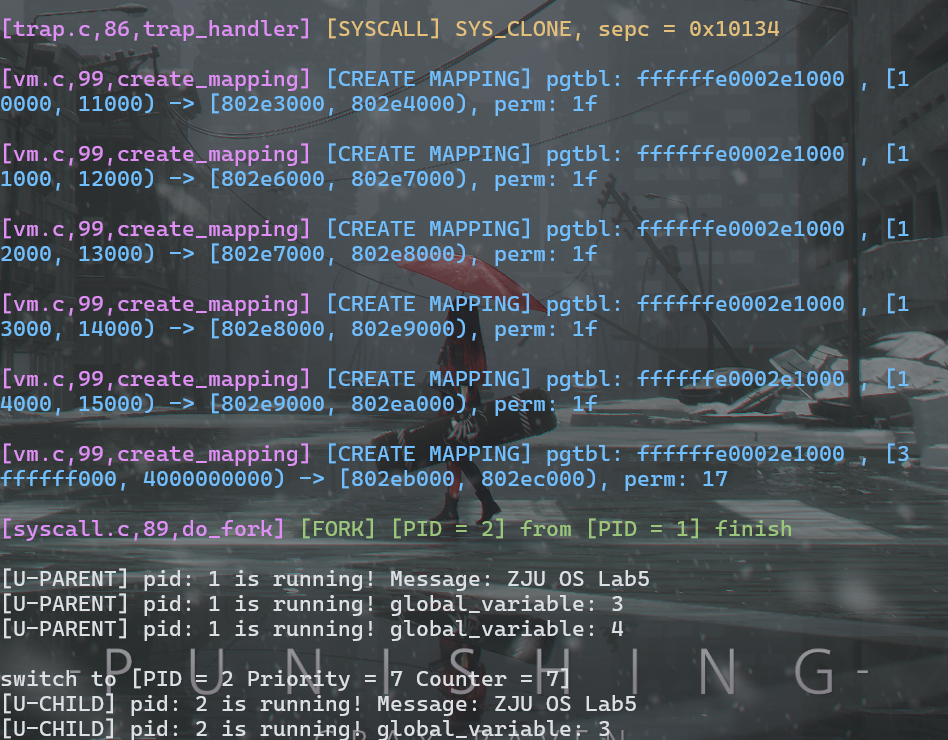
如上图所示,PID 为 1 的进程([U-PARENT])成功创建了 PID 为 2 的进程([U-CHILD]),而且子进程的 global_variable 与父进程进行 fork 时的一致,且运行时两者互不影响,后续 page fault 也是各自为自己的页表添加映射
make run TEST=FORK2
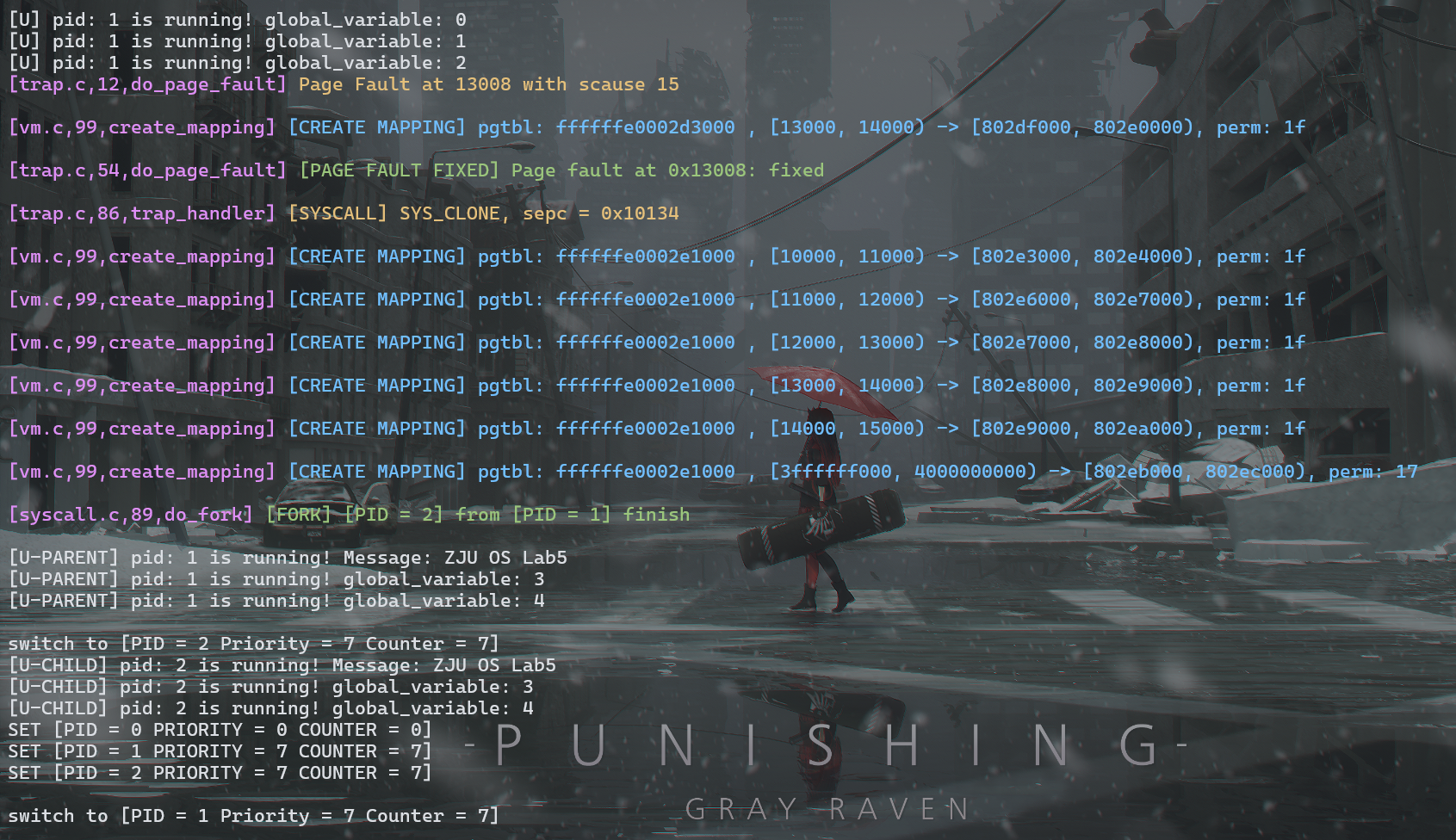
可以看到,父进程先给 global_variable 自增了三次,然后才 fork 了子进程
在 FORK1 的基础上,此测试中的父进程与子进程的 global_variable 一致,均从 3 开始执行自增,子进程也成功获取了 placeholder 的字符串并输出,执行也互不影响
make run TEST=FORK3
见思考题 2.5
思考题
呈现出你在 page fault 的时候拷贝 ELF 程序内容的逻辑。
uint64_t vpg_start = PGROUNDDOWN(bad_addr);
uint64_t vpg_end = PGROUNDUP(bad_addr);
if(!(flags & VM_ANON)) {
memcpy(_sramdisk + vma->vm_pgoff + vpg_start - vma->vm_start, new_pg, PGSIZE);
}else{
memset(new_pg, 0, PGSIZE);
}
这样简单粗暴地拷贝完整一页是有可能出错的,因为 elf 里的一个 segment 结尾不一定是页对齐的
这意味着,如果 bad_addr 正好处在 segment 的最后一页,且 segment 结尾不是页对齐的,那么我们额外拷贝了后面一段未知的数据,而且,我们在 create_mapping 一起给其设置了权限,程序是有可能访问这一段未知数据的,这样可能会出错
所以,可以改进 page fault 的时候拷贝 ELF 程序内容的方法,只需要额外检查边界情况即可:
uint64_t vpg_start = MAX(vma->vm_start, PGROUNDDOWN(bad_addr));
uint64_t vpg_end = MIN(vma->vm_end, PGROUNDUP(bad_addr));
if(!(flags & VM_ANON)) {
uint64_t seg_end = vma->vm_start + vma->vm_filesz;
memcpy(_sramdisk + vma->vm_pgoff + vpg_start - vma->vm_start,
new_pg + vpg_start - PGROUNDDOWN(vpg_start),
MIN(vpg_end, seg_end) - vpg_start);
}else{
memset(new_pg, 0, PGSIZE);
}
应该是这题想问的地方吧 T-T
回答 4.3.5 中的问题:
在 do_fork 中,父进程的内核栈和用户栈指针分别是什么?
do_fork 中,父进程处于内核态,内核栈指针为 sp ,用户栈指针为 sscratch 。
在 do_fork 中,子进程的内核栈和用户栈指针的值应该是什么?
do_fork 中,⼦ 进程的内核栈指针的值为 (uint64_t)child + (uint64_t)regs - PGROUNDDOWN((uint64_t)regs)
用户栈指针的值应与父进程的一致,即父进程 sscratch 的值
在 do_fork 中,子进程的内核栈和用户栈指针分别应该赋值给谁?
⼦ 进程的内核栈指针可用于计算用户态上下 ⽂ 的地址(实际上就是相等的)。退出内核态后,内核栈指针与用 户栈指针交换以切换到用户栈
为什么要为子进程 pt_regs 的 sepc 手动加四?
sepc 指向的是发起 fork 请求的指令,如果不手动加四子进程又会重复 fork
对于 Fork main #2(即 FORK2),在运行时,ZJU OS Lab5 位于内存的什么位置?是否在读取的时候产生了 page fault?请给出必要的截图以说明。
修改 user/main.c,打印 placeholder 地址:
/* Fork main #2 */
...
int main() {
int pid;
for (int i = 0; i < 3; i++) {
printf("[U] pid: %ld is running! global_variable: %d\n", getpid(), global_variable++);
}
printf("[DEBUG] placeholder is at %p\n", placeholder, placeholder + 8192);
placeholder[4096] = 'Z';
...
}
如下图所示,placeholder 位于 0x12008 处,而 ZJU OS Lab5 从 placeholder[4096] 开始存放,故 ZJU OS Lab5 位于 [0x13008, 0x13014)
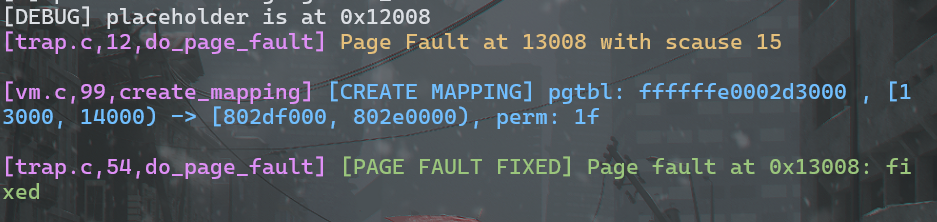
紧跟着 main 往 placeholder 写入字符串,上图可见在 0x13008 处产生了缺页异常并成功解决,之后打印时就没有缺页异常了:
画图分析 make run TEST=FORK3 的进程 fork 过程,并呈现出各个进程的 global_variable 应该从几开始输出,再与你的输出进行对比验证。
TEST=FORK3 代码如下:
/* Fork main #3 */
#elif defined(FORK3)
int global_variable = 0;
int main() {
printf("[U] pid: %ld is running! global_variable: %d\n", getpid(), global_variable++);
fork();
fork();
printf("[U] pid: %ld is running! global_variable: %d\n", getpid(), global_variable++);
fork();
while(1) {
printf("[U] pid: %ld is running! global_variable: %d\n", getpid(), global_variable++);
wait(WAIT_TIME);
}
}
我们可以画出以下流程图:
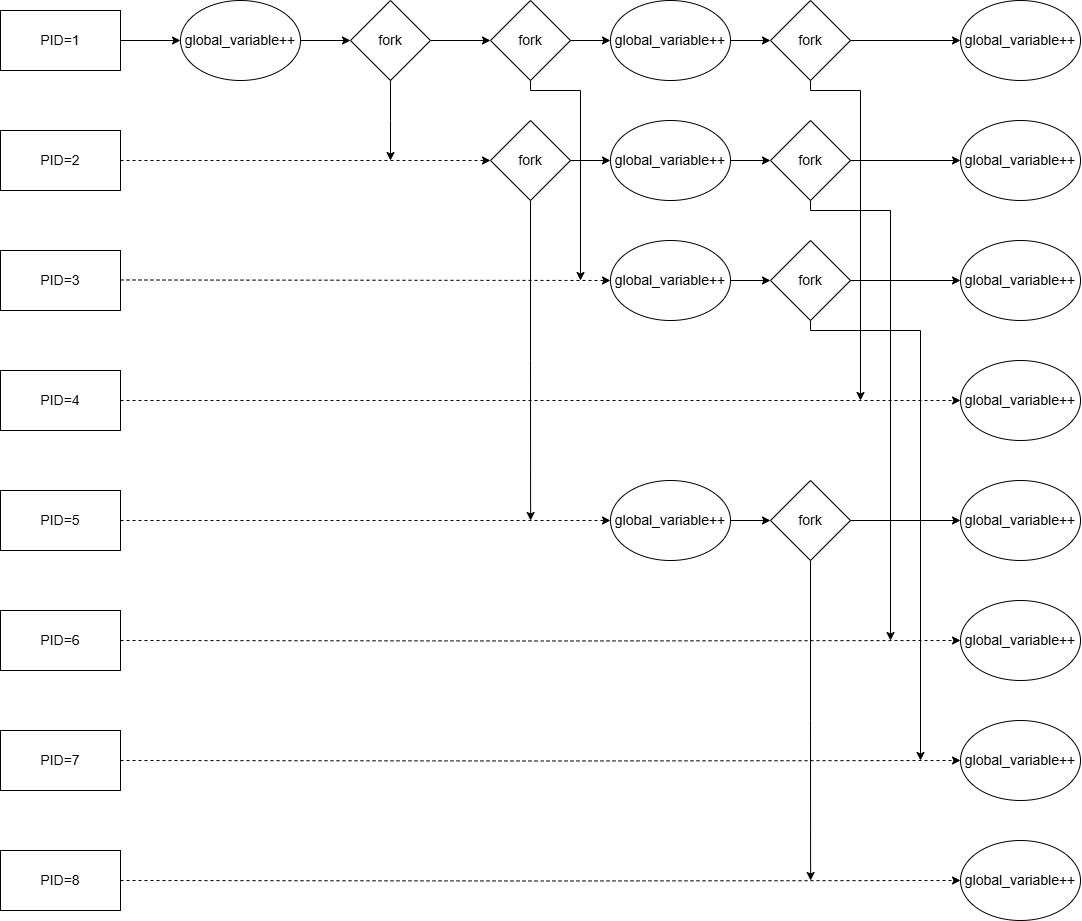
我们可以确定以下测试点:
PID 为 1 的进程在第一、二次输出中间 fork 了 PID 为 2、3 的进程,在第二、三次输出中间 fork 了 PID 为 4 的进程
PID 为 2、3 的进程的 global_variable 初始值应为 1,PID 为 4 的进程 global_variable 初始值应为 2
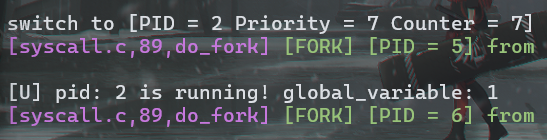


PID 为 2、3 的进程在第一、二次输出中间分别 fork 了 PID 为 5、6 的进程,PID 为 2 的进程在第二、三次输出中间 fork 了 PID 为 7 的进程
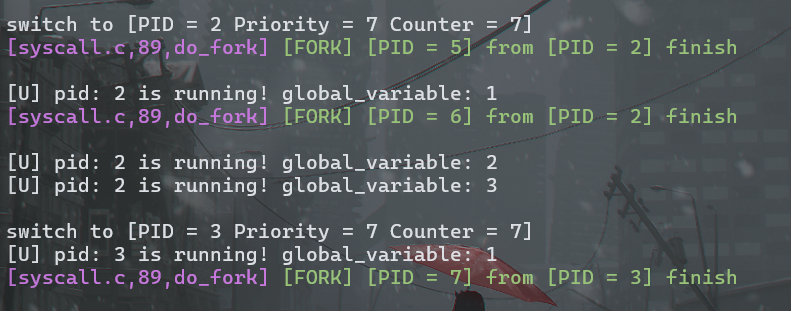
PID 为 5、6、7 的进程的 global_variable 初始值应分别为 1,2,2
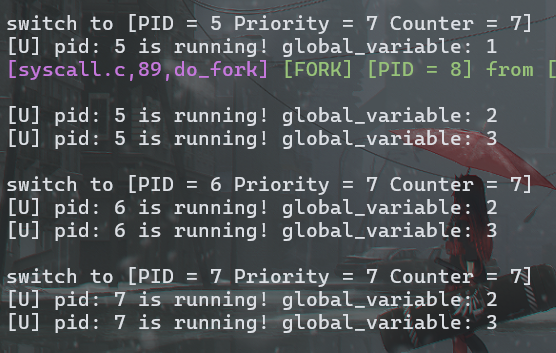
PID 为 5 的进程在第一次输出之前 fork 了 PID 为 8 的进程

PID 为 8 的进程的 global_variable 初始值应为 2

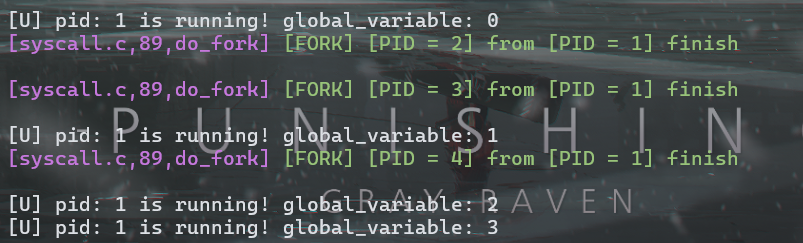
综上, make run TEST=FORK3 的结果符合理论预期
心得体会
本次实验让我们的操作系统能更灵活地加载程序,不再是固定的一次性全部 load 进内存,内存利用率得到了提高,且不再是在代码里写死了执行几个程序,程序可以自行 fork 来创建程序了
缺页异常处理部分并没有遇到太大问题,而在 fork 部分遇到一个问题是,fork 后子进程输出的依旧是 [U-PARENT]...,这说明子进程用的还是父进程的栈,在排查后发现是 _traps 中,从 trap_handle 返回后我们又执行了一次 ld sp, 272(sp),这本来是不需要的,但加了之后,在子进程执行到这条语句时,ld 出来的是父进程的 sp,所以出现了我们遇到的情况
将这句注释掉即可解决